Ajuste do modelo:
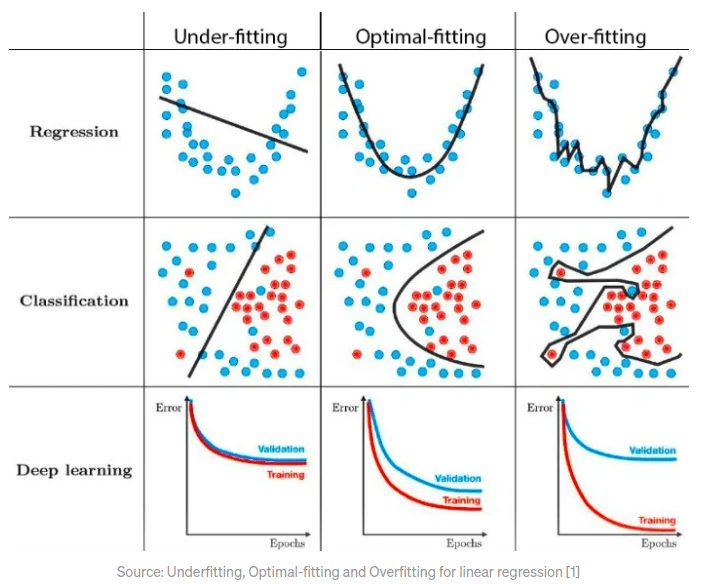
Primeiro identificar se o modelo está subajustado ou superajustado conforme o erro na predição dos dados de validação e treinamento. Quanto maior o erro, maior a variância, a variância é o erro do modelo para os dados de teste; já o viés, é o quão bem um modelo se adequa aos dados de treino, o quanto ele é generalista.
O ideal é um modelo que tem baixo viés e baixa variância, ou seja, ele se adéqua a qualquer dados e erra pouco.
Sobreajustado (overfitting): quer dizer um modelo não generalista, ou seja, ele memorizou os dados, acertou os dados de treinamento, mas obteve uma alta taxa de erros nos dados de validação.
Sobajustado (underfitting): é um modelo que erra bastante na predição dos dados de treinamento, tem baixo desempenho, uma das causas é que o modelo escolhido seja muito simples para o descrever e obter a variável dependente.
Balanceado (balanced): é um modelo ideal, com pouco erro para os dados de teste e um modelo generalista.
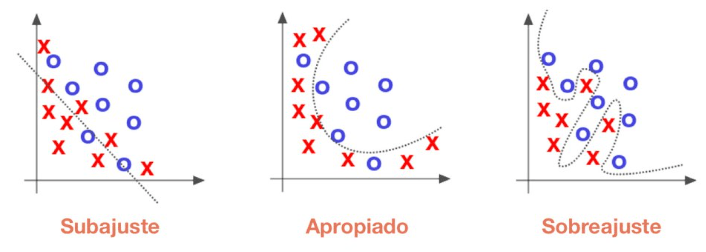
Fonte: https://aprendeia.com/sobreajuste-y-subajuste-en-machine-learning/, acesso em 25 de novembro de 2024.
Cross Validation:
Objetivo é achar os melhores valores para os hiperparametros (tunning do modelo) e ter uma expectativa mais acurada da qualidade do nosso modelo (Exemploe melhor AUC)
Divide a amostra em Treino e teste, onde treino será onde o modelo será desenvolvido e o teste será onde o modelo será avaliado.
Ou
Divide a amostra em Treino , Validação e teste, onde treino será onde o modelo será desenvolvido e o validação será onde o modelo será avaliado e teste o “valendo” onde será a real performance do modelo.
Performance classificador binário – 0 não evento e 1 evento
Curva ROC: (performance classificador binário)
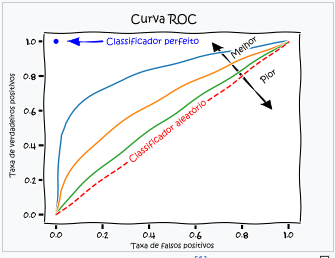
Site: https://pt.wikipedia.org/wiki/Caracter%C3%ADstica_de_Opera%C3%A7%C3%A3o_do_Receptor – acessado 29 janeiro 2025
O eixo “Taxa de verdadeiros positivos” é o acerto do evento e no eixo horizontal “Taxa de falsos positivos” é o erro do não-evento
GINI: (não é o mesmo gini de árvore)
Acurácia: medida mais intuitiva e mais simples
Matrix de confusão, vemos o total de positivos que foram classificados como positivos e total de negativos que foram classificados como negativos, soma ambos e divide pelo total da amostra, esse será o valor% da acurácia.
Porem, é apenas para 1 ponto de corte (50% – 50%).
Sensitividade: Acerto dos positivos
Especificidade: Acertos do não evento
Em uma árvore para cada ponto de corte Curva-ROC tenho uma nova matrix confusão, consequentemente uma nova sensitividade e especificidade, Curva-ROC.
K-fold:
Ele divide a base de treino em k grupos, separa um para validação, treina para os demais e avalia o modelo, e vai trocando os grupos , e depois calcula a media, acaba fazendo a validação com toda base de dados, e com a validação cruzada faz uma validação melhor.
Utilizado para comparar e validar os hiperparametros, o melhor é o que tem melhor acurácia.
K-fold com GridsearchCV:
