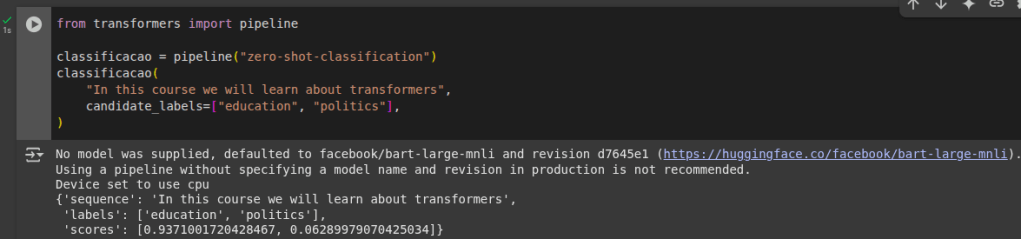
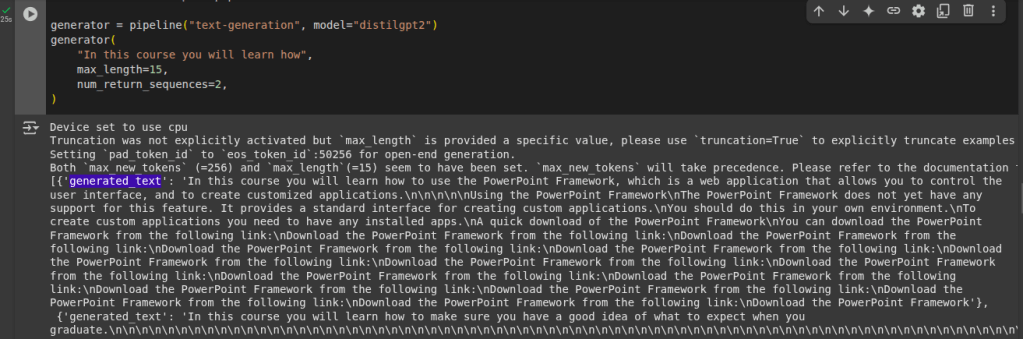
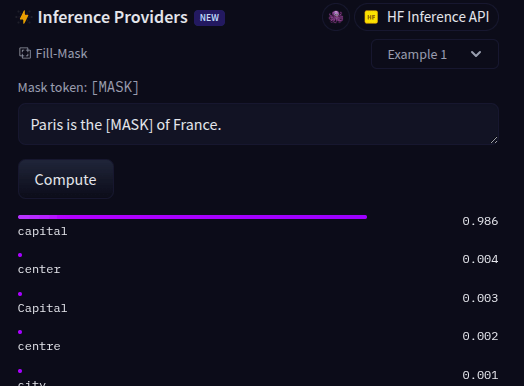
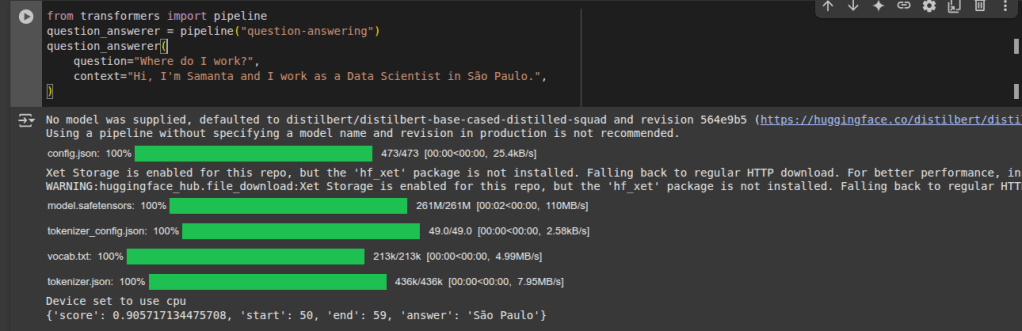
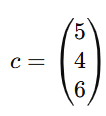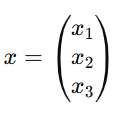Em busca da mistura com menos custo, ou seja, minimizar o preço.
Notação matemática:
- objetivo é achar as proporções dos ingredientes que respeitem os limites e chegue ao menor custo.
Modelo:
Exemplos de aplicações:
Exemplo 1)
Modelo: Alocação de Entregas com Capacidade
Contexto
Uma organização precisa distribuir entregas para centros regionais.
Cada centro deve ser atendido por exatamente um veículo.
Cada veículo tem um limite máximo de atendimentos.
O objetivo é minimizar a distância total percorrida.
from pulp import LpProblem, LpMinimize, LpVariable, lpSum, LpStatus, value, PULP_CBC_CMD# Criar problemamodelo = LpProblem("Delivery_Allocation_Model", LpMinimize)veiculos = ['V1', 'V2', 'V3']locais = ['Norte', 'Sul', 'Leste', 'Oeste', 'Centro']# Variável binária: y[v,l] = 1 se veículo v atende local ly = LpVariable.dicts( "assign", [(v, l) for v in veiculos for l in locais], cat="Binary")# Matriz de custos (distâncias)custo = { ('V1', 'Norte'): 15, ('V1', 'Sul'): 20, ('V1', 'Leste'): 10, ('V1', 'Oeste'): 25, ('V1', 'Centro'): 5, ('V2', 'Norte'): 18, ('V2', 'Sul'): 15, ('V2', 'Leste'): 12, ('V2', 'Oeste'): 22, ('V2', 'Centro'): 8, ('V3', 'Norte'): 20, ('V3', 'Sul'): 25, ('V3', 'Leste'): 15, ('V3', 'Oeste'): 18, ('V3', 'Centro'): 10,}# -------------------------# Função Objetivo# -------------------------modelo += lpSum(custo[(v, l)] * y[(v, l)] for v in veiculos for l in locais)# -------------------------# Restrição 1:# Cada local deve ser atendido exatamente uma vez# -------------------------for l in locais: modelo += lpSum(y[(v, l)] for v in veiculos) == 1# -------------------------# Restrição 2:# Capacidade máxima de atendimentos por veículo# -------------------------limite_atendimentos = {'V1': 3, 'V2': 2, 'V3': 3}for v in veiculos: modelo += lpSum(y[(v, l)] for l in locais) <= limite_atendimentos[v]# Resolvermodelo.solve(PULP_CBC_CMD(msg=False))# Resultadosprint("Status:", LpStatus[modelo.status])print("Distância total mínima:", value(modelo.objective))for v in veiculos: atendimentos = [l for l in locais if value(y[(v, l)]) > 0.5] print(f"{v} atende: {', '.join(atendimentos) if atendimentos else 'Nenhum'}")
Status: OptimalDistância total mínima: 63.0V1 atende: Norte, Leste, CentroV2 atende: SulV3 atende: Oeste
Exemplo 2)
custo mínimo para 1Kg de ração com as restrições abaixo de quantidade mínima de proteína e sódio.
Modelo com valores respectivos para Frango/Osso/Trigo, com:
- mistura total = 1 kg
- proteína mínima
- sódio máximo
- x1,x2,x3≥0
Atenção: os coeficientes como exemplo na tabela (proteína: 0.6/0.2/0.1 e sódio: 0.1/0.05/0.02; limites proteína ≥ 0.4 e sódio ≤ 0.08).
import numpy as npfrom scipy.optimize import linprog# -------------------------# Variáveis de decisão# x1 = kg Frango, x2 = kg Osso, x3 = kg Trigo# -------------------------# Função objetivo: minimizar custo# min 5x1 + 4x2 + 6x3c = np.array([5, 4, 6], dtype=float)# Restrições do tipo A_ub @ x <= b_ub# 1) Proteína mínima: 0.6x1 + 0.2x2 + 0.1x3 >= 0.4# Convertemos para <= multiplicando por -1:# -0.6x1 -0.2x2 -0.1x3 <= -0.4# 2) Sódio máximo: 0.1x1 + 0.05x2 + 0.02x3 <= 0.08A_ub = np.array([ [-0.6, -0.2, -0.1], # proteína (convertida) [ 0.1, 0.05, 0.02], # sódio], dtype=float)b_ub = np.array([ -0.4, # proteína mínima 0.08, # sódio máximo], dtype=float)# Restrição de igualdade: x1 + x2 + x3 = 1 (mistura total)A_eq = np.array([[1, 1, 1]], dtype=float)b_eq = np.array([1], dtype=float)# Limites (não negatividade): x1, x2, x3 >= 0bounds = [(0, None), (0, None), (0, None)]# Resolverres = linprog( c=c, A_ub=A_ub, b_ub=b_ub, A_eq=A_eq, b_eq=b_eq, bounds=bounds, method="highs")# Resultadosif res.success: x1, x2, x3 = res.x print("✅ Solução ótima encontrada (custo mínimo)") print(f"x1 (Frango) = {x1:.4f} kg") print(f"x2 (Osso) = {x2:.4f} kg") print(f"x3 (Trigo) = {x3:.4f} kg") print(f"Custo mínimo = R$ {res.fun:.4f}") # Checagem das restrições (opcional) proteina = 0.6*x1 + 0.2*x2 + 0.1*x3 sodio = 0.1*x1 + 0.05*x2 + 0.02*x3 print("\n🔎 Checagem:") print(f"Total = {x1 + x2 + x3:.4f} (deve ser 1)") print(f"Proteína = {proteina:.4f} (>= 0.4)") print(f"Sódio = {sodio:.4f} (<= 0.08)")else: print("❌ Não foi possível encontrar solução.") print("Motivo:", res.message)✅ Solução ótima encontrada (custo mínimo)x1 (Frango) = 0.5000 kgx2 (Osso) = 0.5000 kgx3 (Trigo) = 0.0000 kgCusto mínimo = R$ 4.5000🔎 Checagem:Total = 1.0000 (deve ser 1)Proteína = 0.4000 (>= 0.4)Sódio = 0.0750 (<= 0.08)