Exemplo em python está no repositório: https://github.com/samantaleke/Unsupervised_clustering
- Método hierarquico aglomerativo.
- Método não hierarquico K-means.
- Técnicas de cluster são técnicas não supervisionadas e exploratórias, sem fins para criação de modelo preditivo, não se faz previsão. Apenas criação de grupos.
- Se novas observações entrarem na amostra, ou sairem, deve se executar novamente a criação de clusters.
- Tanto o Método Hierárquico Aglomerativo quanto o Método Não Hierárquico K-means são técnicas de análise de agrupamentos (clusterização) projetadas para funcionar com variáveis quantitativas (numéricas/contínuas).
- A diferença essencial, é que no K-means você precisa informar quantos clusters irá se formar, ao contrário do método hierárquico que agente escolhe após o dendograma.
- Escalas das medidas das variáveis deve ser pequena (exemplo 1 a 10) , se não estiver , deve se realizar a normalização, exemplo por z-score. Pois essas grandes amplitudes podem dominar os clusters.
Método hierarquico aglomerativo. (para análise)
O método hierárquico aglomerativo é uma técnica de aprendizado não supervisionado que agrupa dados “de baixo para cima”.
Método muito utilizado em analise exploratória e a quantidade de cluster é definida ao longo da analise.
Método não hierarquico K-means.
Deve se definir antes quantos grupos de cluster serão encontrados.
Método que se baseia na minimização.
Método hierarquico aglomerativo. (distância)
O quanto os grupos são diferentes entre si.
ANTES de iniciar:
- Verificar se as suas variáveis possuem unidade de medidas/ amplitudes muito distintas, muito grandes.
- Se for, deve-se utilizar a padronização em todas varáveis. Como? Ex. Z-score, passando a ter médias 0 e desvio padrão 1.
deve-se fazer o passo 1 e 2, pois impactam muito nos resultados da clusterização, onde variáveis com grandes amplitydes/distancia acabam dominando na clusterização.
Depois escolher entre:
Medida de dissimilaridade: se eu quero que os grupos sejam mais homogêneos internamente e heterogêneo entre si, tenho que decidir qual medida diga quais são as observações parecidas e quais são diferentes.
Método de encadeamento.
Qual o padrão de agrupamento.
Exemplo calculo:
Decidir a medida de distancia (dissimilaridade): QUANTO Maior a distância mais diferentes são entre 2 pontos.
Exemplo: Para calcular a distância, normalmente utiliza-se uma das medidas: euclidiana, euclidiana quadrática ou distância de Manhattan, distância de Chebychev, distância de Canberra (proporção), ou até a correlação de Pearson entre as observações.
Exemplo, conforme a tabela abaixo, que já estão na mesma escala de 0 a 10, ou seja, não precisa normalizar.

Seguem as distâncias:
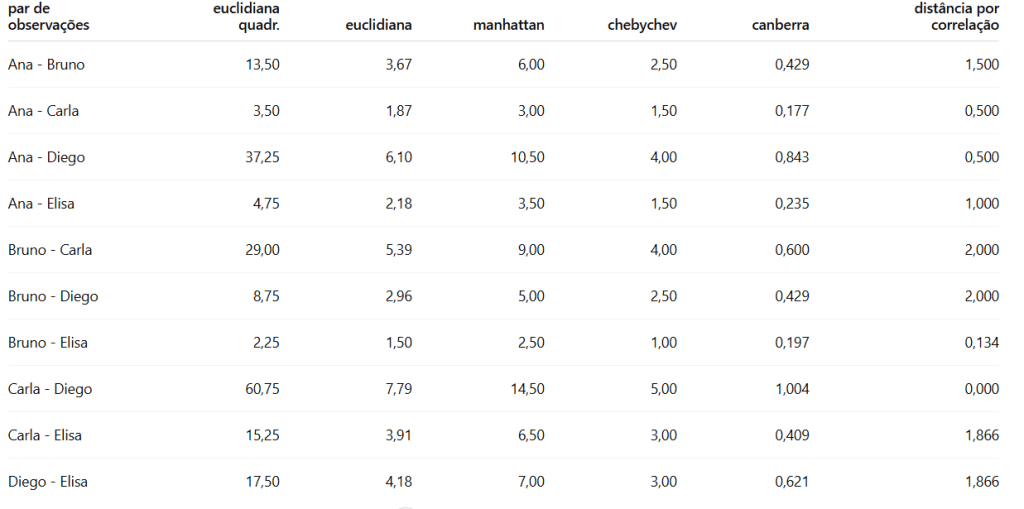
Distância Euclidiana Quadrática:
Ou seja, distância euclidiana quadrática entre Ana e Bruno é 13,50.
Escolho a metrica de distância/dissimilaridade, muito utilizada a euclidiana e vou unindo os pares com menores distâncias, criando os clusters.
Agora entra o método de encadeamento.
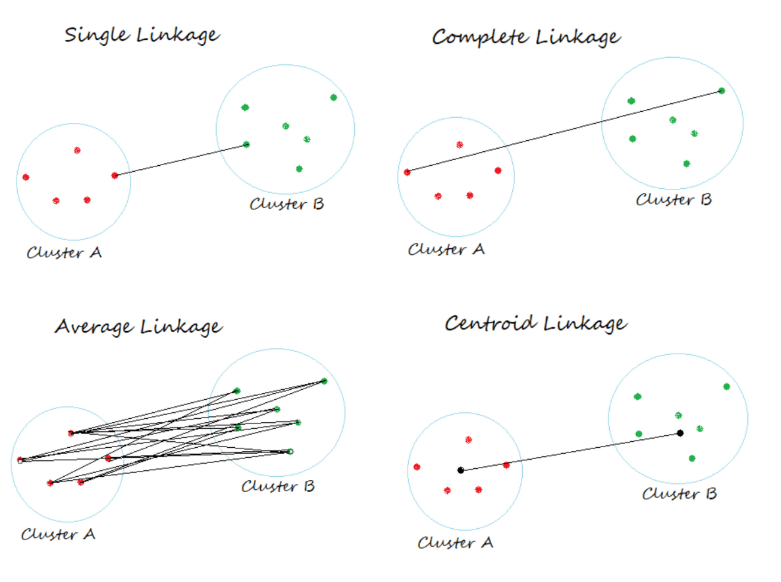
Ligação Simples (Single Linkage)/(vizinho mais próximo): Define a distância entre dois clusters como a menor distância entre qualquer ponto do primeiro cluster e qualquer ponto do segundo cluster.
Ligação Completa (Complete Linkage): Define a distância entre dois clusters como a maior distância entre qualquer ponto do primeiro cluster e qualquer ponto do segundo cluster.
Ligação Média (Average Linkage): Calcula a distância entre dois clusters como a média das distâncias entre todos os pares de pontos (um de cada cluster).
O método de Ward é uma técnica de análise de agrupamento hierárquico (clustering) que minimiza a variância dentro dos clusters. Ele agrupa observações maximizando a homogeneidade interna, ideal para variáveis quantitativas e para criar grupos de tamanhos similares. O processo aglomerativo une, a cada etapa, os dois grupos que resultam no menor aumento da soma dos quadrados.
Por fim, vai unindo todas as observações, no exemplo acima todas as pessoas, até o fim, criando um Dendograma:
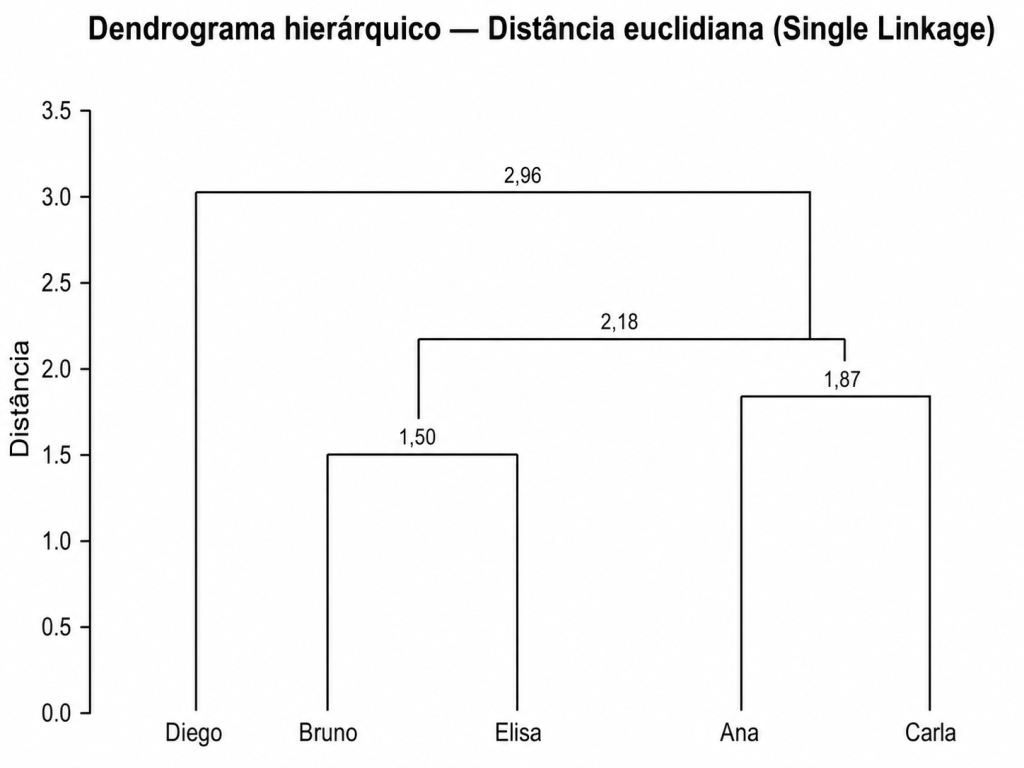
Estabelecer um corte, quantas barras verticais cortou ?
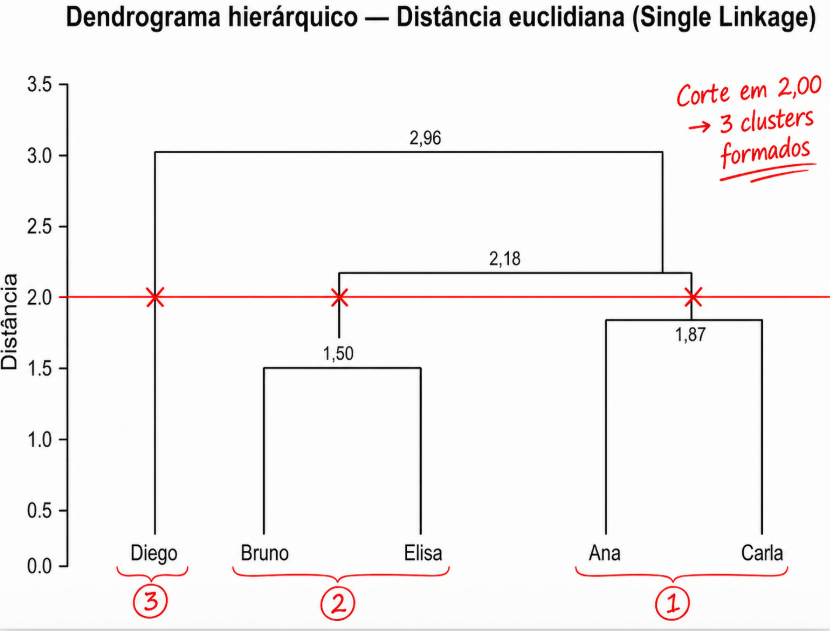
veja que verifico logo abaixo da minha linha de corte, quantas | barras tem logo abaixo, no caso são 3 | barras, exemplificada com X em vermelho.
Em Python posso criar uma variável categórica com o valor do cluster a qual aquela observação pertence:
cluster_euclidi_min = AgglomerativeClustering(n_clusters = 3, metric = 'euclidean', linkage = 'single')indica_cluster = cluster_euclidi_min.fit_predict(df)df['cluster'] = indica_clusterdf['cluster'] = df['cluster'].astype('category')
Método não hierarquico K-means
Utiliza critério de minimização. Busca minimização a distância de cada observação até o centróide daquela observação.
- K Clusters deve ser escolhidos antes, os centróides, cada centróide vai gerar 1 cluster.
- Depois o k-means aloca as observações mais próximas desses centróides.
A solução final indica que a soma dos quadrados das distâncias entre cada observação e o centro do cluster ao qual ela foi alocada, conhecida como WCSS, foi minimizada. Essa solução é alcançada quando os centróides não se alteram mais significativamente entre as iterações.
Onde:
- xi é a observação i;
- μk é o centróide do cluster k;
- zik indica se a observação i pertence ao cluster k;
- K é o número de clusters.
Como funciona o K-means?
- Inicialização dos centróides
O algoritmo começa escolhendo K centróides iniciais, que representam os centros provisórios dos grupos. Esses pontos podem ser escolhidos aleatoriamente no espaço dos dados. - Atribuição dos pontos aos clusters
Em seguida, cada ponto do conjunto de dados é associado ao centróide mais próximo, de acordo com uma medida de distância, como a distância euclidiana. Assim, são formados os primeiros K clusters. - Atualização dos centróides
Depois que os pontos são atribuídos aos clusters, o algoritmo recalcula a posição de cada centróide. O novo centróide passa a ser a média dos pontos pertencentes ao respectivo grupo. - Repetição do processo
As etapas de atribuição dos pontos e atualização dos centróides são repetidas várias vezes. A cada iteração, os grupos tendem a ficar mais ajustados. - Critério de parada
O processo termina quando os centróides deixam de mudar significativamente ou quando o algoritmo atinge um número máximo de iterações definido previamente. - Resultado final
Ao final, cada ponto estará associado a um dos K clusters, de forma que os pontos dentro de um mesmo grupo sejam mais semelhantes entre si do que em relação aos pontos de outros grupos.
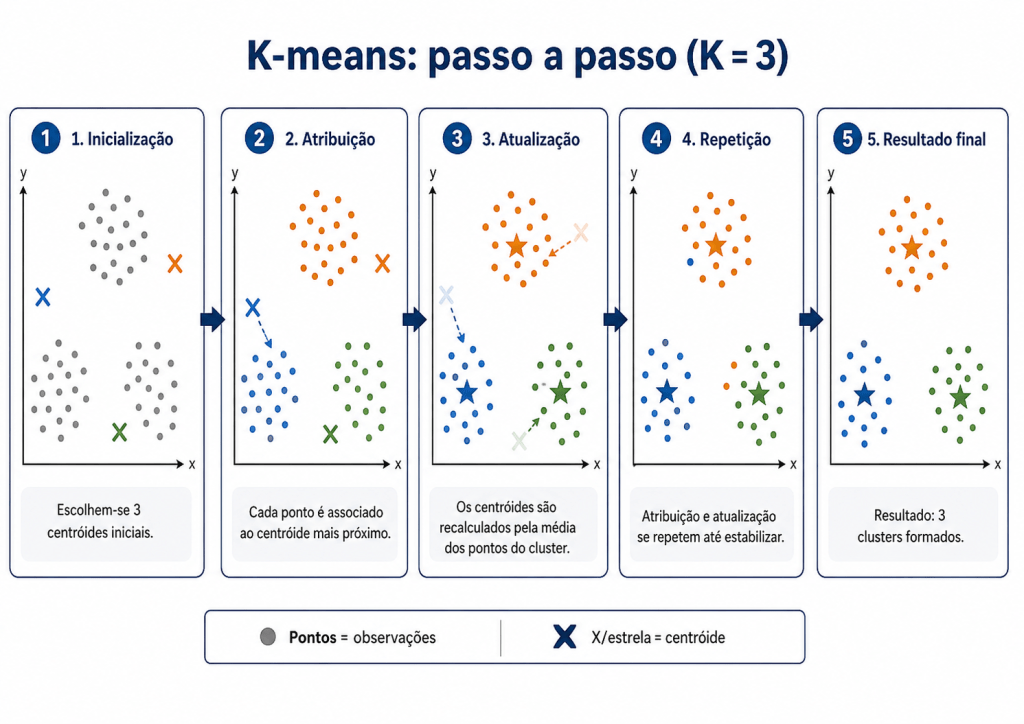
Conforme o mesmo exemplo de Métodos Hierarquicos Aglomerativos, abaixo estão a formação de clusters com K-means.
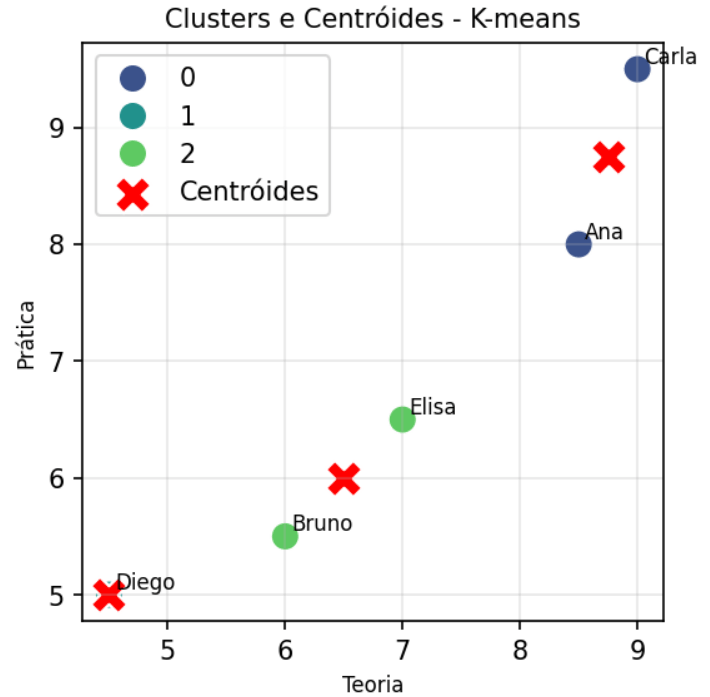
Como escolher quantos clusters ?
A definição do número de clusters, representado por K, é uma etapa importante no uso do algoritmo K-means. Como o modelo exige que esse valor seja informado previamente, algumas técnicas podem ajudar a identificar uma quantidade adequada de grupos.
Método Cotovelo (Elbow):
O Método do Cotovelo avalia diferentes valores de K e calcula, para cada um deles, a soma dos quadrados das distâncias dentro dos clusters, conhecida como WCSS.
À medida que o número de clusters aumenta, a WCSS tende a diminuir, pois os grupos ficam menores e os pontos ficam mais próximos de seus respectivos centróides. No entanto, chega um momento em que aumentar o número de clusters gera pouca melhoria adicional.
No gráfico, esse ponto costuma aparecer como uma “dobra” ou “cotovelo”. Esse valor de K é considerado uma boa escolha, pois representa um equilíbrio entre simplicidade e qualidade do agrupamento.
O ponto onde a curva “dobra”.
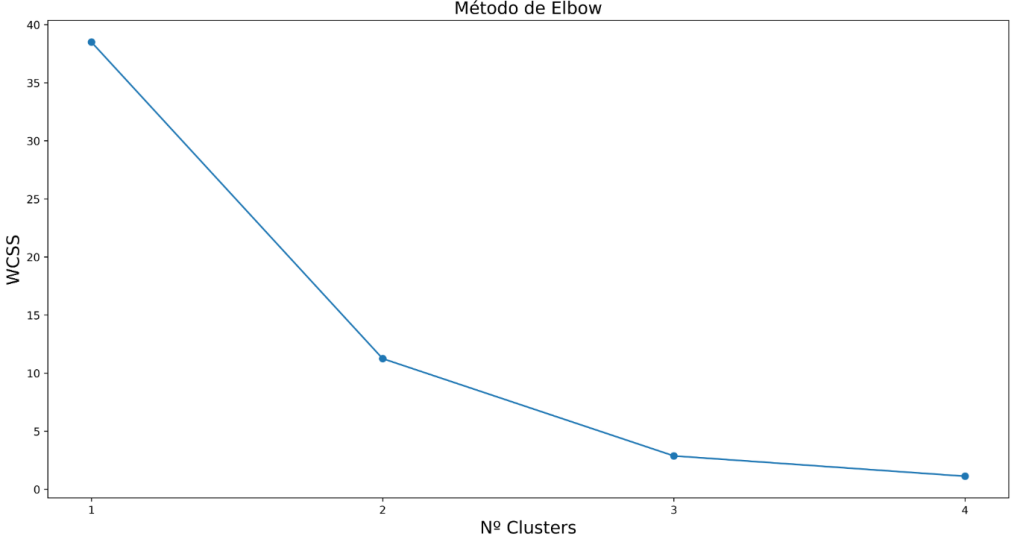
No Método do Cotovelo, quanto menor o WCSS, mais próximos os pontos estão dos centróides de seus respectivos clusters.
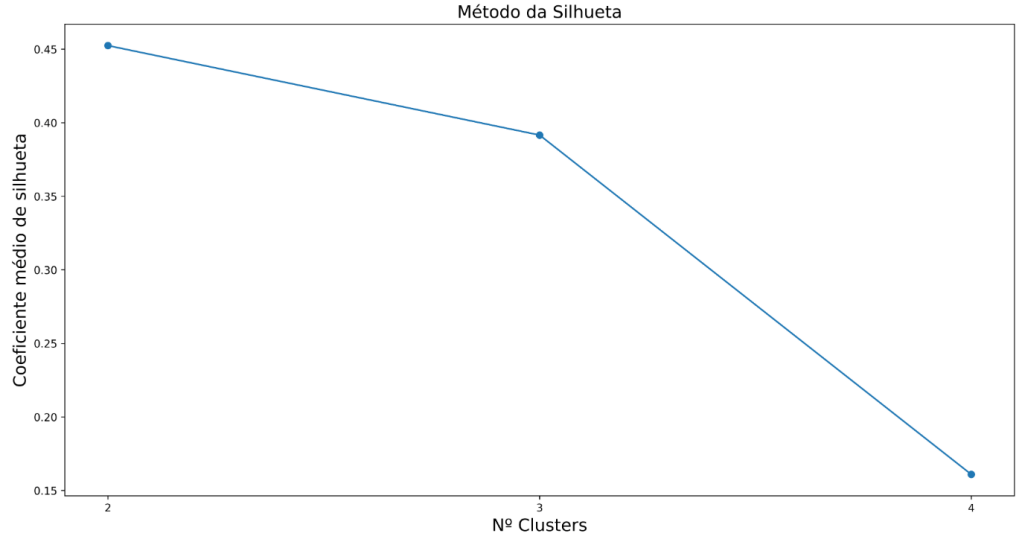
Método da Silhueta
O Método da Silhueta avalia o quanto cada observação está bem alocada dentro do seu cluster. Para isso, são consideradas duas medidas principais:
- a: distância média da observação em relação aos pontos do cluster ao qual ela pertence;
- b: distância média da observação em relação ao cluster mais próximo ao qual ela não pertence.
Com essas duas informações, calcula-se o coeficiente de silhueta para cada observação. Depois, obtém-se a média dos coeficientes de todas as observações.
Esse procedimento é repetido para diferentes valores de K. Em geral, quanto maior o coeficiente médio de silhueta, melhor tende a ser a separação entre os clusters.
Análise:
Entender quais variáveis ajudaram mais a diferenciar os grupos formados. Ou qual variavel mais influenciou na separação de pelo menos um dos Clusters.
A ANOVA pode ser utilizada como uma análise complementar para verificar quais variáveis mais diferenciam os clusters formados pelo K-means. Em geral, quanto maior a estatística F, maior a diferença entre as médias dos clusters em relação à variabilidade interna dos grupos.
*No exemplo há apenas 5 estudantes, com uma amostra tão pequena, o p-valor não deve ser interpretado com muita força estatística.
Uma forma de fazer essa análise é comparar a variabilidade existente entre os clusters com a variabilidade existente dentro dos clusters. A lógica é simples: uma variável tende a ser mais relevante para separar os grupos quando apresenta médias bem diferentes entre os clusters e, ao mesmo tempo, menor dispersão dentro de cada grupo.
Para isso, pode-se utilizar a análise de variância [ANOVA], por meio da estatística F:
Na prática, quanto maior o valor da estatística F, maior tende a ser a capacidade daquela variável em diferenciar os agrupamentos.
Os graus de liberdade utilizados nesse teste são:
Em que:
- representa o número de clusters;
- representa o tamanho da amostra.
Assim, após formar os clusters, é possível avaliar quais variáveis mais contribuíram para a separação dos grupos. As variáveis com maiores valores da estatística F, principalmente quando acompanhadas de significância estatística, tendem a ser as mais discriminantes na formação dos clusters.
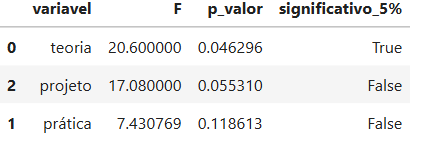
Variável mais discriminante: teoria
Estatística F: 20.6000
p-valor: 0.0463
A variável teoria apresentou a maior estatística F, com valor de 20,60, e p-valor de 0,0463. Como esse p-valor é menor que 0,05, essa foi a única variável com diferença estatisticamente significativa entre os clusters, considerando o nível de significância de 5%.
A variável projeto também apresentou uma estatística F elevada, com valor de 17,08, mas seu p-valor foi 0,0553, ligeiramente acima de 0,05. Portanto, neste exemplo, ela ficou próxima da significância estatística, mas não seria considerada significativa pelo critério tradicional de 5%.
A variável prática apresentou estatística F menor, igual a 7,43, e p-valor de 0,1186, indicando menor evidência de diferença entre os clusters em comparação com as demais variáveis.
