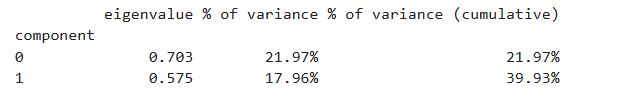Uma variável pode ser estatisticamente significativa quando analisada isoladamente, mas perder significância quando inserida em um modelo com outras variáveis altamente correlacionadas.
Em regressões múltiplas, a significância estatística de uma variável depende não apenas de sua relação com a variável resposta, mas também da informação compartilhada com as demais variáveis explicativas. Quando existe forte multicolinearidade, o modelo encontra dificuldades para separar os efeitos individuais dos preditores, aumentando os erros-padrão dos coeficientes e reduzindo sua significância estatística.
Quanto da variabilidade de Y foi explicada pelo modelo?
❷ Teste F
Pergunta:
O modelo como um todo possui capacidade explicativa?
Hipóteses:
Nesse exemplo:
Prob(F-statistic) = 0.000001
Logo:
✅ Rejeita H₀
✅ Pelo menos um β é significativo
α (Intercepto)
Linha:
Intercept
Coeficiente:
10.52
Interpretação:
Quando:
esperamos:
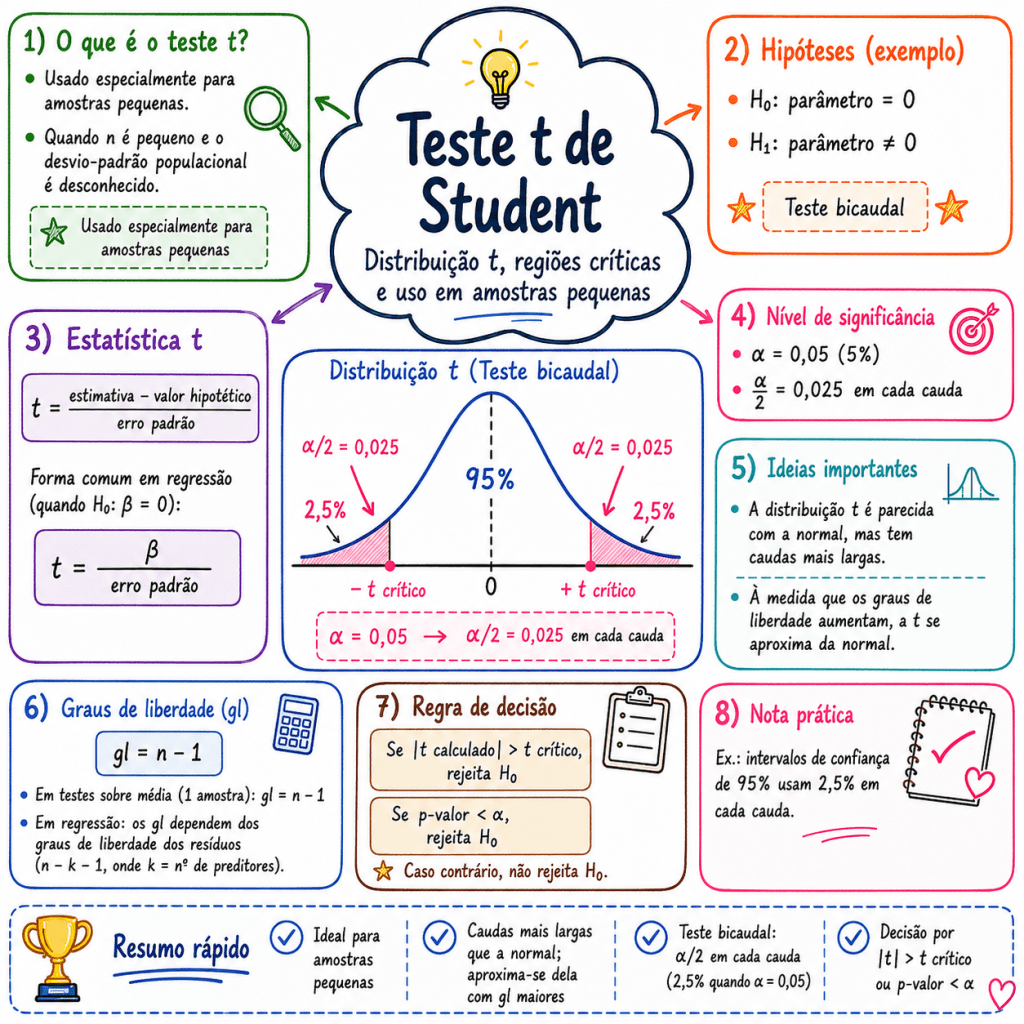
Teste t
Cada linha de variável possui um teste t próprio.
Exemplo:
X1coef = 2.31t = 5.50p-value = 0.000
Hipóteses:
Como:
p-value < 0,05
✅ X1 é significativa.
Resumo visual
SUMMARY
│
├── R²
│ Quanto Y foi explicado?
│
├── Teste F
│ Modelo funciona?
│
├── α (Intercept)
│ Valor esperado de Y quando X=0
│
├── β
│ Efeito de cada variável
│
├── Teste t
│ β é significativo?
│
├── p-value
│ Evidência estatística
│
└── IC95%
Faixa plausível para o coeficiente
Teste F → avalia o modelo inteiro
Teste t → avalia cada β individualmente
α → é apenas mais um coeficiente, mas representa o intercepto da reta/plano de regressão.
Multicolinearidade
Um dos sintomas clássicos da multicolinearidade ocorre quando o teste F indica que o modelo é globalmente significativo, mas os testes t individuais não identificam coeficientes significativos. Nessa situação, as variáveis explicativas possuem forte correlação entre si, dificultando a separação de seus efeitos individuais sobre a variável resposta. Como consequência, os erros-padrão aumentam, as estatísticas t diminuem e os p-values tornam-se elevados, mesmo quando o conjunto de variáveis explica adequadamente Y.
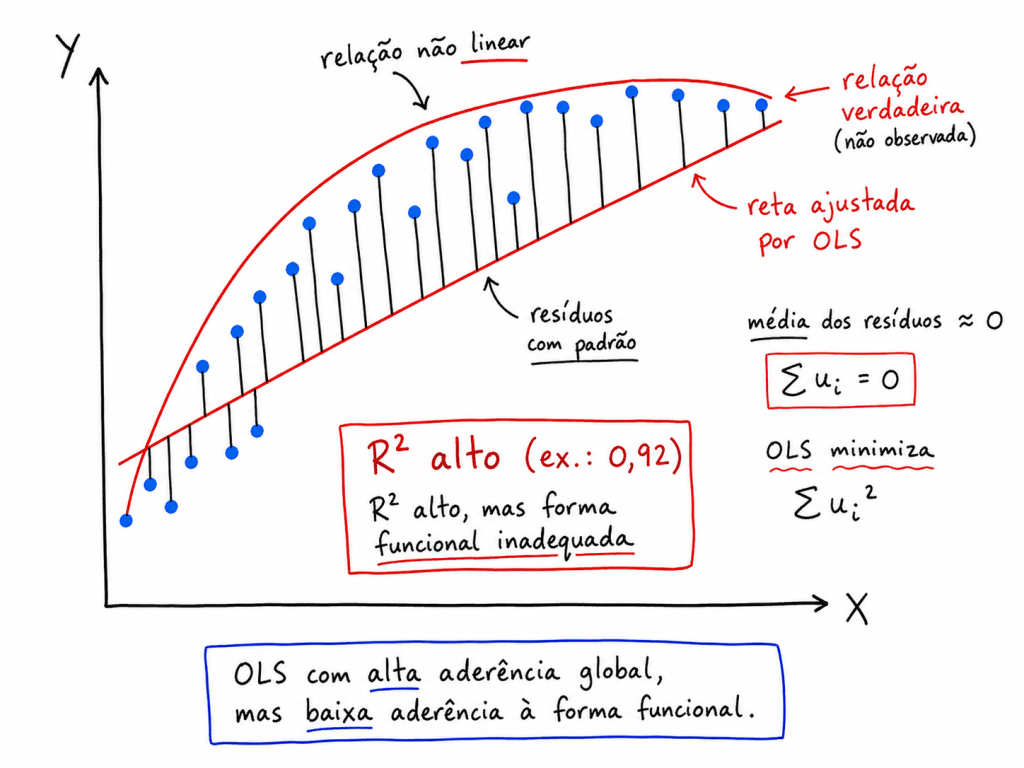
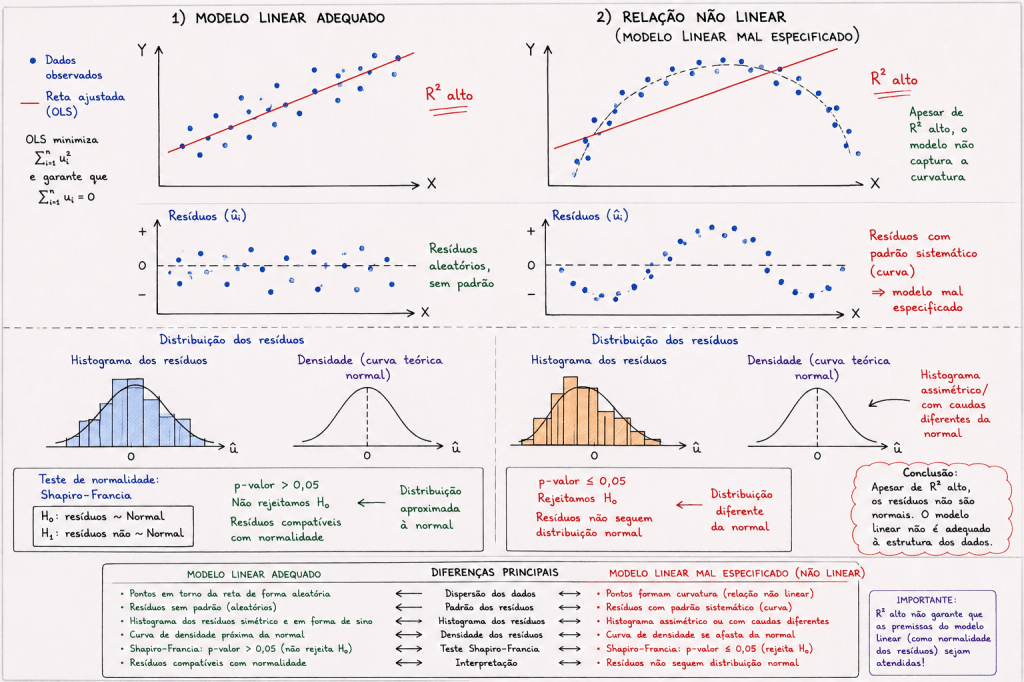
Resíduos não aderentes a normalidade, por determinado teste estatístico, provavelmente a distribuição de dados é não linear.
Exemplo de Teste estatístico para verificar se os resíduos estão aderentes a normalidade.
Shapiro-Wilk: Amostras pequenas (50 observações)
Shapiro-Francia: Amostras maiores.
O teste de Shapiro–Francia é um teste estatístico utilizado justamente para verificar essa hipótese de normalidade.
Hipóteses do teste
O teste trabalha com duas hipóteses:
Ou seja:
representa a hipótese de normalidade;
representa a hipótese alternativa, indicando violação da normalidade.
Interpretação do p-valor
Após executar o teste, obtém-se um valor chamado p-value.
A regra geral é:
Se:
não rejeitamos .
Assim, há evidências de que os resíduos possuem aderência à normalidade.
Se:
rejeitamos .
Nesse caso, conclui-se que os resíduos não seguem distribuição normal.
Normalização/Transformação box-cox (transformação da variável dependente)
O Box-Cox não transforma os resíduos diretamente. Primeiro transformamos , ajustamos o modelo com , e só depois avaliamos se os novos resíduos ficaram mais aderentes à normalidade.
Qual melhor Lambda que maximiza a aderência a normalidade.
Na transformação Box-Cox, quando ainda não existe um modelo ajustado, não avaliamos os termos de erro, pois os resíduos só existem após a estimação do modelo. Nesse caso, a transformação é aplicada diretamente sobre a variável resposta Y, com o objetivo de aproximar sua distribuição da normalidade e estabilizar sua variância.
O parâmetro da transformação Box-Cox é escolhido de forma a tornar a variável resposta transformada o mais próxima possível de uma distribuição normal. Assim, antes de ajustar o modelo, buscamos uma escala mais adequada para , aumentando a chance de que os resíduos do modelo apresentem melhor comportamento estatístico.
A transformação é:
quando:
E quando:
usa-se:
A ideia é testar vários valores de λ, por exemplo:
e escolher aquele que maximiza a aderência de à distribuição normal.
É usada quando a variável resposta é contínua e aproximadamente simétrica.
Erros comuns, importante:
Intercepto não significativo não invalida o modelo. Não remover o intercept/alfa do modelo. Ele apenas indica que, com a amostra disponível, não há evidência suficiente de que o intercepto seja diferente de zero. Forçar sem justificativa pode gerar viés e piorar a interpretação do modelo.
R2 ajustado é para comparar modelos.
Cuidado com ponderação arbitrária, exemplo transformar variável qualitativa em LabelEncoder int(64), o correto é dummizar, deixar como string.
Alguns exemplos utilizados corretamente.
Prever o valor de um imóvel com base em área, localização e número de quartos.
Nesse caso, a resposta pode assumir vários valores numéricos contínuos.
Funcionamento:
Em modelos OLS a somatória dos termos de erro é igual a zero.
Modelo GLM
Distribuição
Tipo da variável dependente
Quando usar
Forma aproximada da distribuição
Regressão Linear
Normal
Quantitativa contínua
Quando a resposta é contínua e aproximadamente simétrica
🔔 Curva em sino
Olhamos o nível de significância do Beta.
A regressão linear simples busca modelar a relação entre uma variável dependente e uma variável independente .
A equação geral é:
Yi=β0+β1Xi+εi
Onde:
Termo
Significado
(Y_i)
Valor observado da variável dependente para a observação (i)
(X_i)
Valor da variável independente para a observação (i)
(\beta_0)
Intercepto da reta, ou seja, valor esperado de (Y) quando (X = 0)
(\beta_1)
Inclinação da reta, ou seja, quanto (Y) varia quando (X) aumenta 1 unidade
(\varepsilon_i)
Termo de erro, isto é, a diferença entre o valor observado e o valor estimado
Uma forma mais didática também é escrever:
Nesse caso:
representa o intercepto da reta, ou seja, α é o ponto onde a reta corta o eixo ;
representa a inclinação da reta;
representa o erro da observação iii.
Então, a nomenclatura:
Valor estimado pelo modelo
O modelo não prevê exatamente . Ele calcula um valor estimado, chamado de :
Onde:
é o valor previsto pelo modelo.
Termo de erro
O erro é a diferença entre o valor real observado e o valor previsto pelo modelo:
Substituindo:
Esse erro mostra o quanto o modelo errou para cada observação.
Ideia do algoritmo
O algoritmo da regressão linear procura encontrar a melhor reta possível para os dados.
Essa melhor reta é aquela que minimiza a soma dos erros ao quadrado:
Como:
temos:
Esse método é chamado de Mínimos Quadrados Ordinários — Ordinary Least Squares[OLS].
Fórmula da inclinação da reta
A inclinação pode ser calculada por:
Ela mede o quanto tende a mudar quando aumenta uma unidade.
Fórmula do intercepto
Depois de calcular , calculamos o intercepto :
Onde:
é a média dos valores de ;
é a média dos valores de .
Interpretação prática
Imagine o modelo:
Nesse caso:
A interpretação é:
Quando , o valor esperado de é 10.
E:
Quando aumenta 1 unidade, espera-se que aumente 2 unidades.
Exemplo:
Se o valor real observado fosse:
então o erro seria:
Ou seja, o modelo subestimou o valor real em 3 unidades.
A Regressão Linear busca encontrar uma reta que melhor representa a relação entre e . Essa reta é definida por um intercepto e uma inclinação. O intercepto indica o valor esperado de quando , enquanto a inclinação indica quanto muda quando aumenta uma unidade. O termo de erro representa a diferença entre o valor observado e o valor previsto pelo modelo. O algoritmo estima os coeficientes minimizando a soma dos erros ao quadrado.
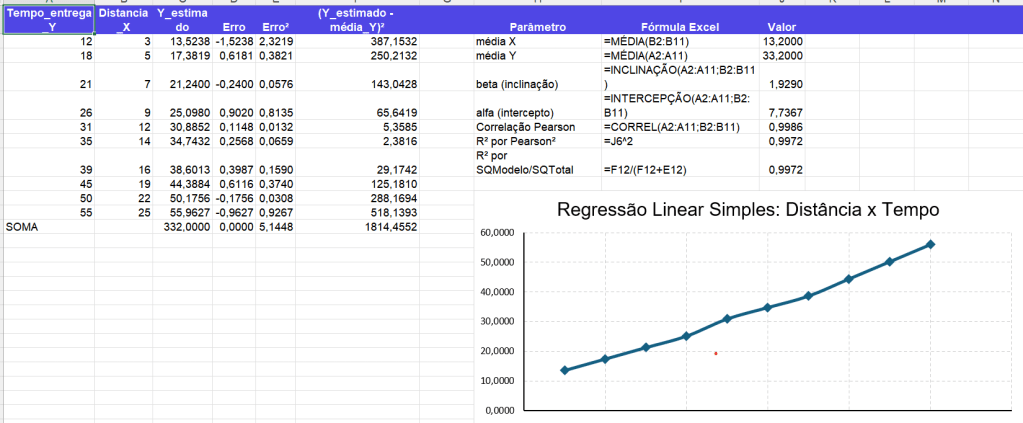
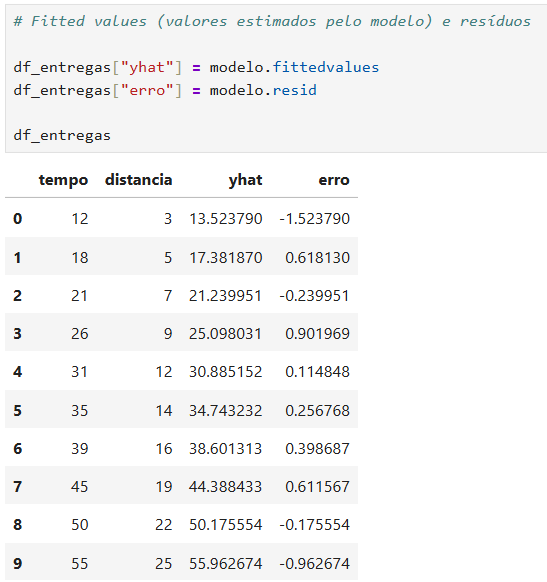
Exemplo:
Y: tempo de entrega;
X: distância;
cálculo de , , erro, erro², , , correlação de Pearson e ;
Tempo entrega Y
Distância X
Y estimado
Erro
Erro²
(Y^−Yˉ)2
12
3
13,5238
-1,5238
2,3219
387,1532
18
5
17,3819
0,6181
0,3821
250,2132
21
7
21,2400
-0,2400
0,0576
143,0428
26
9
25,0980
0,9020
0,8135
65,6419
31
12
30,8852
0,1148
0,0132
5,3585
35
14
34,7432
0,2568
0,0659
2,3816
39
16
38,6013
0,3987
0,1590
29,1742
45
19
44,3884
0,6116
0,3740
125,1810
50
22
50,1756
-0,1756
0,0308
288,1694
55
25
55,9627
-0,9627
0,9267
518,1393
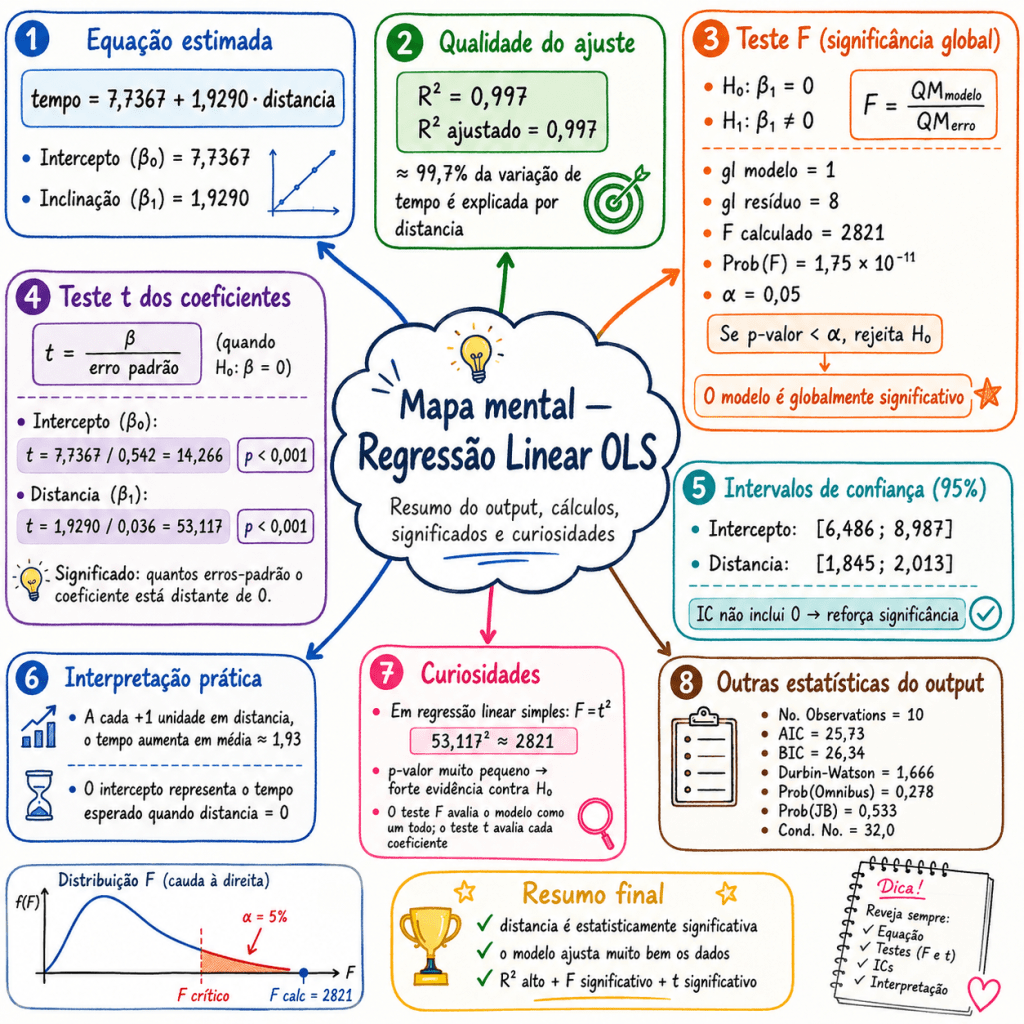
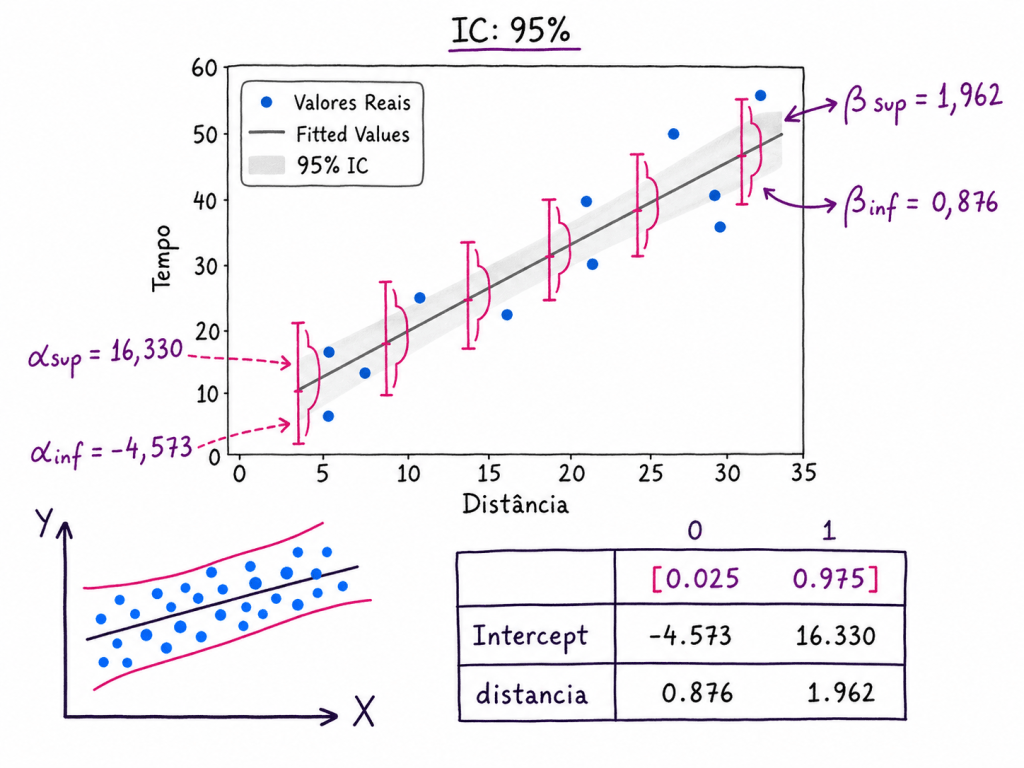
Modelo encontrado
A reta estimada ficou:
Y^=7,7367+1,9290X
Ou seja:
α=7,7367
A interpretação é:
A cada aumento de 1 unidade na distância, o tempo de entrega aumenta, em média, aproximadamente 1,9290 unidades.
Tabelas de parâmetros:
Parâmetro
Fórmula Excel
Valor
média X
=MÉDIA(B2:B11)
13,2000
média Y
=MÉDIA(A2:A11)
33,2000
beta
=INCLINAÇÃO(A2:A11;B2:B11)
1,9290
alfa
=INTERCEPÇÃO(A2:A11;B2:B11)
7,7367
Correlação Pearson
=CORREL(A2:A11;B2:B11)
0,9986
R² por Pearson²
=J6^2
0,9972
R² por soma dos quadrados
=F12/(F12+E12)
0,9972
A regressão linear simples encontra a melhor reta para explicar a relação entre e . O cálculo pode ser visto como um problema de otimização, pois o objetivo é minimizar a soma dos erros ao quadrado:
α,βmini=1∑n(Yi−Y^i)2
Como:
Y^i=α+βXi
então:
α,βmini=1∑n(Yi−α−βXi)2
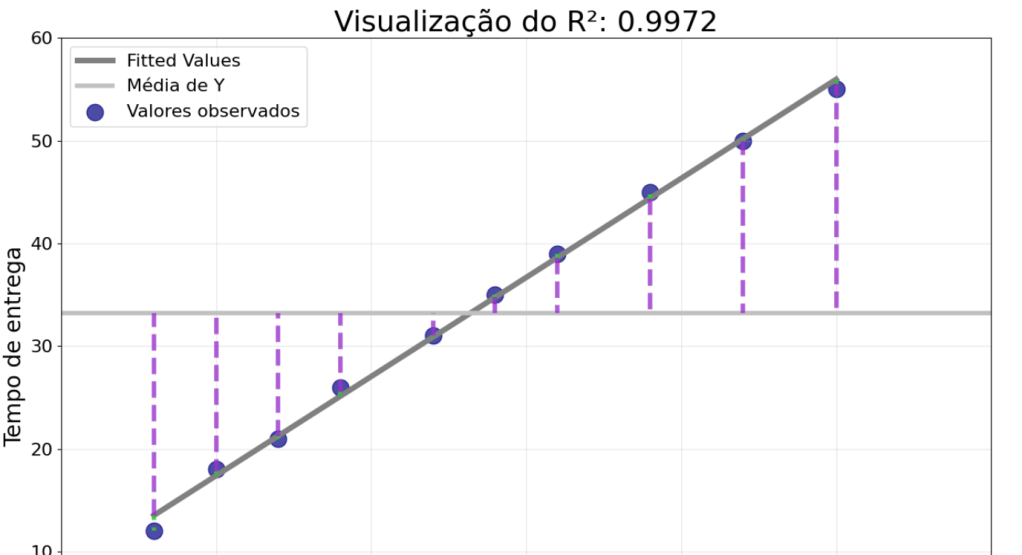
Nesse exemplo, o modelo apresentou:
R2=0,9972
Isso significa que aproximadamente 99,72% da variação do tempo de entrega foi explicada pela distância.
E como é uma regressão linear simples, com apenas uma variável , vale a curiosidade:
R2=r2
onde é a correlação de Pearson entre e .
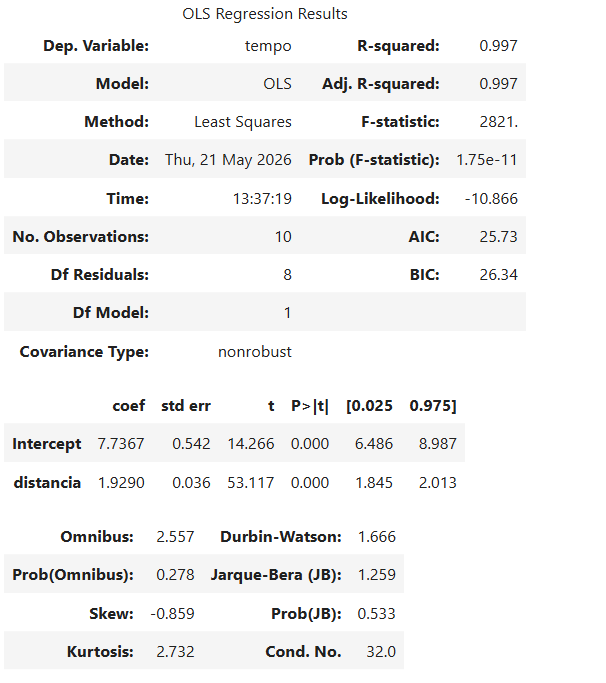
Python
Utilizando o modelo OLS (Ordinary Least Squares, ou Mínimos Quadrados Ordinários), já tenho como premissa que a variável Y ou dependente é quantitativa, que a somatório dos erro é igual 0 e a somatória dos erros ao quadrado será a mínima possível.
Correspondência entre a saída do Python e a equação da regressão
A regressão linear simples estimada pelo Python aparece no formato:
No nosso exemplo:
Ou seja:
Saída no Python
Nome estatístico
Nome didático
Valor no nosso exemplo
Interpretação
R-squared
(R^2)
R-quadrado
0,997
Percentual da variação de (Y) explicado por (X)
Intercept
(\alpha) ou (\beta_0)
Intercepto / Alfa
7,7367
Valor estimado de tempo quando a distância é zero
distancia
(\beta) ou (\beta_1)
Beta / Inclinação
1,9290
Quanto o tempo aumenta quando a distância cresce 1 unidade
Equação do modelo
A partir da tabela de coeficientes:
Variável
Coeficiente
Intercept
7,7367
distancia
1,9290
A equação fica:
Onde:
Portanto:
Interpretação do intercepto
O intercepto é o valor esperado de Y quando X=0.
Neste exemplo:
Isso significa que, quando a distância é igual a zero, o tempo estimado pelo modelo seria aproximadamente:
Na prática, nem sempre o intercepto tem uma interpretação realista. Ele é principalmente necessário para posicionar a reta no gráfico.
Interpretação do beta
O coeficiente da variável distancia é:
Isso significa que, para cada aumento de 1 unidade na distância, o tempo de entrega aumenta, em média, aproximadamente:
unidades de tempo.
Em linguagem simples:
Quanto maior a distância, maior tende a ser o tempo de entrega.
Interpretação do R-quadrado
O R-squared aparece como:
Isso significa que aproximadamente:
da variação do tempo de entrega é explicada pela distância no modelo linear simples.
Ou seja, nesse exemplo fictício, a distância explica quase totalmente a variação do tempo.
Coluna
Significado
Fórmula
tempo
Valor real observado de (Y)
(Y_i)
distancia
Variável explicativa (X)
(X_i)
yhat
Valor estimado pelo modelo
(\hat{Y}_i)
erro
Resíduo do modelo
(Y_i – \hat{Y}_i)
A coluna yhat representa os fitted values, ou seja, os valores previstos pela reta de regressão.
Como o modelo estimado foi:
para cada linha, o Python calcula:
Já a coluna erro representa o resíduo:
Ou seja, é a diferença entre o tempo real observado e o tempo estimado pelo modelo.
Exemplo prático
Para a primeira linha, supondo:
o valor estimado é:
Então o erro é:
Como o erro ficou negativo, significa que o modelo estimou um valor maior do que o valor observado.
Resumo e entendimento para o exemplo:
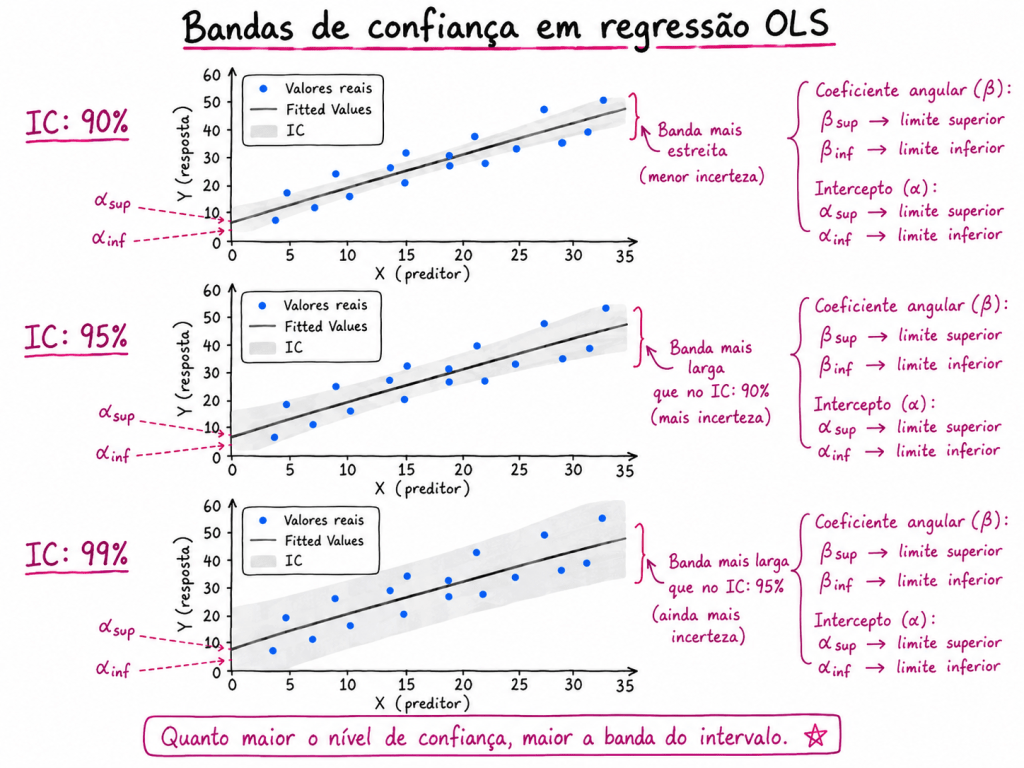
Pontos importantes sobre significância, intervalos de confiança e intercepto na Regressão OLS
Ao interpretar um modelo de regressão linear estimado por OLS, é comum olhar para os coeficientes, os p-valores e os intervalos de confiança. Porém, alguns cuidados são importantes para evitar interpretações erradas.
Resumo dos pontos principais
Ponto
Interpretação
Intervalos de confiança aumentam quando elevamos o nível de confiança
Um IC de 99% tende a ser mais largo que um IC de 95%
A significância depende do nível de significância adotado
Um coeficiente pode ser significativo a 5%, mas não a 1%
Em modelos preditivos, p-valor não é tudo
Métricas de erro e validação também são essenciais
Amostras pequenas aumentam a incerteza
O erro padrão pode crescer e reduzir a significância dos coeficientes
Intercepto não significativo não deve ser removido automaticamente
Forçar a reta pela origem pode gerar viés
1. Quanto maior o nível de confiança, maior será o intervalo do coeficiente
O intervalo de confiança de um coeficiente representa uma faixa provável de valores para o verdadeiro parâmetro populacional.
De forma simplificada:
Onde:
é o coeficiente estimado pelo modelo;
é o erro padrão do coeficiente;
é o valor crítico da distribuição t.
Quando aumentamos o nível de confiança, por exemplo de 95% para 99%, o modelo precisa construir uma faixa mais ampla para aumentar a chance de conter o verdadeiro valor do parâmetro.
2. Um coeficiente pode ser significativo em um nível e deixar de ser em outro
A significância estatística depende diretamente do nível de significância adotado, geralmente representado por α.
Por exemplo:
Isso significa que, ao aumentar o nível de confiança, o teste fica mais rigoroso.
Imagine um coeficiente com:
Se adotarmos α=0,05, esse coeficiente será considerado estatisticamente significativo, pois:
Mas, se adotarmos α=0,01, ele deixará de ser significativo, pois:
Resumo:
Situação
p-valor
Nível de significância
Interpretação
Confiança de 95%
0,03
5%
Significativo
Confiança de 99%
0,03
1%
Não significativo
Então, um mesmo coeficiente pode ser significativo a 95%, mas não significativo a 99%.
Esse ponto é importante porque mostra que a significância estatística não é uma característica absoluta do coeficiente. Ela depende do critério adotado na análise.
3. Em modelos preditivos, significância estatística não deve ser analisada isoladamente
Em problemas de predição, o objetivo principal não é apenas saber se um coeficiente é estatisticamente diferente de zero, mas avaliar se o modelo consegue prever bem novos dados.
Por isso, além dos p-valores, é importante observar métricas como:
erro médio absoluto, MAE;
raiz do erro quadrático médio, RMSE;
;
análise dos resíduos;
desempenho em dados de teste;
validação cruzada, quando aplicável.
Um coeficiente individual pode não ser estatisticamente significativo e, ainda assim, o modelo pode apresentar bom desempenho preditivo.
Por outro lado, um modelo pode ter coeficientes estatisticamente significativos e ainda assim não ser bom para previsão, principalmente se não generalizar bem para novos dados.
Portanto, para fins preditivos, significância estatística é útil, mas não deve ser o único critério de decisão.
4. Amostras pequenas podem dificultar a significância dos parâmetros
O tamanho da amostra tem grande impacto na inferência estatística.
A estatística t de um coeficiente é calculada por:
No caso do intercepto, também chamado de , temos:
Quando a amostra é pequena, o erro padrão tende a ser maior. Isso reduz o valor da estatística t e pode aumentar o p-valor.
A lógica é:
Ou seja, com poucas observações, o modelo pode não ter evidência estatística suficiente para indicar que determinado parâmetro é diferente de zero.
5. Intercepto não significativo não significa que ele deve ser removido automaticamente
Um erro comum em modelos regressivos é remover o intercepto apenas porque ele não apresentou significância estatística.
Isso pode ser perigoso.
O intercepto representa o valor esperado de quando as variáveis explicativas são iguais a zero. Dependendo do problema, esse ponto pode nem ter interpretação prática, mas ainda assim o intercepto ajuda a ajustar corretamente a reta de regressão.
Remover o intercepto força a reta a passar pela origem:
Em vez de permitir:
Essa imposição pode gerar viés no modelo, principalmente quando não existe justificativa teórica para assumir que quando .
Portanto, intercepto não significativo deve ser analisado com cuidado, e não removido automaticamente.
Em regressão OLS, a interpretação dos coeficientes não deve se limitar ao p-valor. O nível de confiança, o tamanho da amostra, o erro padrão e o objetivo do modelo — explicação ou predição — influenciam diretamente a análise. Além disso, a ausência de significância estatística do intercepto não é, por si só, justificativa para removê-lo do modelo.
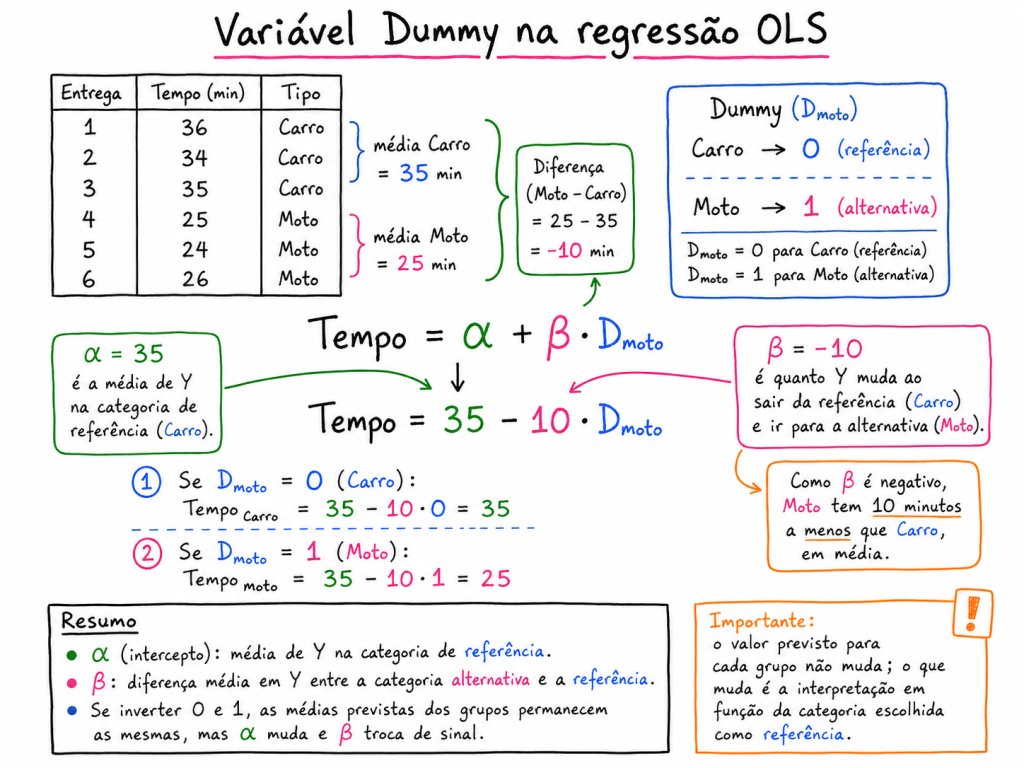
Pontos Importantes sobre variáveis categóricas Dummy
Em modelos regressivos, uma variável dummy indica o efeito médio de pertencer a uma determinada categoria em comparação com uma categoria de referência. Quando a dummy assume valor 0, a observação pertence ao grupo base. Quando assume valor 1, pertence ao grupo alternativo. Assim, o coeficiente da dummy representa o incremento ou redução média esperada em Y ao mudar da categoria de referência para a categoria alternativa, mantendo as demais variáveis constantes.
Uma variável dummy representa uma mudança média em quando saímos da categoria de referência e vamos para a categoria alternativa, mantendo as demais variáveis constantes.
Ou seja:
Dummy em regressão: mede quanto muda, em média, quando passamos da categoria de referência para a categoria alternativa .
O alfa nas variáveis Dummys é o valor medio de Y de quem está na categoria de referência.
O Beta é o quanto se altera de Y quando se passa da categoria de referencia para categorias alternativa. (0 categoria referencia e 1 categoria alternativa). Não importa qual vai ser 0 ou qual categoria será 1, sempre retorna o mesmo valor.
Por exemplo:
Onde:
A interpretação de é:
Quando a observação pertence à categoria alternativa , o valor esperado de muda em média unidades em relação à categoria de referência , mantendo constante.
Exemplo simples
Imagine um modelo para explicar o tempo de entrega:
Onde:
Se o modelo estimou:
A interpretação seria:
Entregas feitas por motoboy têm, em média, 8 minutos a menos no tempo de entrega em relação às entregas feitas por carro, considerando a mesma distância.
Se fosse:
A interpretação seria:
Entregas feitas por motoboy têm, em média, 5 minutos a mais no tempo de entrega em relação às entregas feitas por carro, considerando a mesma distância.
Com 3 categorias se cria 2 Dummies , utilizando One-Hot-encoding.
O valor da Y (variável dependente) vai dizer qual modelos podemos utilizar.
Modelos são correlacionais, não causais, não sei se as variáveis X causam a Y. Correlação não implica causalidade.
Os GLM (modelos lineares generalizados) ampliam a ideia dos modelos lineares tradicionais, permitindo analisar diferentes tipos de variável resposta, não apenas variáveis contínuas com distribuição Normal.
A lógica central continua sendo a mesma: construir um preditor linear a partir das variáveis explicativas. Porém, os GLMs introduzem dois elementos importantes:
Componente aleatório
Nos modelos lineares clássicos, geralmente assumimos que a variável resposta segue uma distribuição Normal. Já nos GLMs, essa exigência é flexibilizada.
A variável resposta pode seguir distribuições pertencentes à família exponencial, como:
Normal: para dados contínuos aproximadamente simétricos;
Poisson: para dados de contagem;
Binomial: para respostas binárias ou proporções;
Gama: para dados contínuos positivos e assimétricos.
Isso torna os GLMs úteis para situações em que a variável resposta não se comporta bem como uma variável Normal.
Função de ligação
A função de ligação conecta a média esperada da variável resposta ao preditor linear do modelo.
De forma geral:
g(μ)=η
Onde:
η=β0+β1X1+β2X2+⋯+βpXp
Aqui:
μ representa a média esperada da variável resposta;
g(μ) é a função de ligação;
η é o preditor linear;
β0,β1,…,βp são os coeficientes do modelo;
X1,X2,…,Xp são as variáveis explicativas.
A função de ligação permite modelar a relação entre a resposta e os preditores de forma adequada à distribuição escolhida. Por exemplo, em modelos de contagem, ela ajuda a garantir que os valores previstos sejam sempre positivos; em modelos binomiais, garante que as probabilidades previstas fiquem entre 0 e 1.
Uma forma simples de resumir é:
O GLM mantém a estrutura linear nos parâmetros, mas permite trabalhar com diferentes distribuições da variável resposta por meio de uma função de ligação adequada.
Exemplos de modelos GLM:
Modelo GLM
Tipo da variável dependente
Tipo de resposta
Distribuição usada
Função de ligação comum
Exemplo
Regressão Linear
Quantitativa contínua
Valores numéricos contínuos e aproximadamente simétricos
Normal
Identidade
Valor de imóvel, altura, temperatura
Regressão Logística
Qualitativa nominal binária
Duas categorias, como sim/não ou 0/1
Binomial
Logit
Aprovação/reprovação, doente/não doente
Regressão de Poisson
Quantitativa discreta
Contagem de eventos
Poisson
Log
Número de reclamações, número de atendimentos
Regressão Binomial Negativa
Quantitativa discreta
Contagem com superdispersão
Binomial Negativa
Log
Número de internações com alta variabilidade
Regressão Gama
Quantitativa contínua positiva
Valores positivos e assimétricos à direita
Gama
Log ou inversa
Custo hospitalar, tempo de internação
OBS:
observação importante:
A Regressão Logística trabalha com uma variável dependente qualitativa nominal binária, porque a resposta representa categorias, como:Y={1,0,simna˜o
Já modelos como Poisson e Binomial Negativa usam variáveis dependentes quantitativas discretas, pois a resposta é uma contagem:Y=0,1,2,3,…
E modelos como Linear e Gama usam variáveis dependentes quantitativas contínuas, pois a resposta representa medidas numéricas em escala contínua.
Distribuição característica:
Modelo GLM
Distribuição
Tipo da variável dependente
Quando usar
Forma aproximada da distribuição
Regressão Linear
Normal
Quantitativa contínua
Quando a resposta é contínua e aproximadamente simétrica
🔔 Curva em sino
Regressão Logística
Binomial
Qualitativa nominal binária
Quando a resposta possui duas categorias, como 0/1, sim/não
⚫ ⚪ Dois resultados possíveis
Regressão de Poisson
Poisson
Quantitativa discreta
Quando a resposta representa contagem de eventos
▂▅█▆▃ Barras de contagem
Regressão Binomial Negativa
Binomial Negativa
Quantitativa discreta
Quando há contagem com variância maior que a média
▂▃▆█▅▃ Cauda mais longa
Regressão Gama
Gama
Quantitativa contínua positiva
Quando a resposta é positiva e assimétrica à direita
Verificar se existe associação e estatisticamente significantes: teste Qui-Quadrado.
Criando a tabela contingência, para verificar a contagem por variável.
Abaixo será explicado detalhadamente cada item:
ANACOR
Função de cada etapa da ANACOR
Etapa
Função na análise
1. Tabela de contingência
É o ponto de partida. Mostra as frequências observadas entre duas variáveis categóricas, por exemplo, Perfil do Cliente × Canal de Atendimento.
2. Frequências esperadas
Mostram quais valores seriam esperados se as duas variáveis fossem independentes, ou seja, se não houvesse associação entre elas.
3. Resíduos padronizados
Medem a diferença entre o observado e o esperado em cada célula. Indicam quais combinações ocorreram mais ou menos do que o esperado.
4. Matriz A
É construída a partir dos resíduos padronizados divididos por n. Ela organiza os desvios padronizados em uma matriz preparada para a decomposição matemática.
5. Matriz /W=ATA
Resume a estrutura de associação das categorias das colunas. É a matriz usada para encontrar os autovalores e autovetores.
6. Autovalores λ
Indicam quanta informação, ou inércia, cada dimensão explica. Quanto maior o autovalor, mais importante é aquela dimensão.
7. Autovetores
Indicam a direção dos eixos fatoriais. Eles ajudam a determinar como as categorias serão posicionadas no espaço.
8. Coordenadas das categorias
Transformam as categorias em pontos no plano. Cada categoria recebe uma coordenada e , correspondentes às dimensões 1 e 2.
9. Gráfico perceptual
Representa visualmente as categorias. Categorias próximas no gráfico tendem a estar mais associadas.
Frequências absolutas observadas
Onde:
representa a frequência esperada da célula da linha i e coluna j;
representa o total da linha;
representa o total da coluna;
representa o total geral da tabela.
Exemplo de Frequências Absolutas:
Perfil do Cliente
App
Site
Telefone
Loja Física
Total
Jovem
35
20
5
10
70
Adulto
25
30
15
20
90
Idoso
5
10
25
30
70
Total
65
60
45
60
230
Duas variáveis categóricas:
Perfil do Cliente Canal de Atendimento
Frequência esperada
Para Jovem × App:
Exemplo de Frequências esperadas
Perfil do Cliente
App
Site
Telefone
Loja Física
Jovem
19,78
18,26
13,70
18,26
Adulto
25,43
23,48
17,61
23,48
Idoso
19,78
18,26
13,70
18,26
Tabela de resíduos simples
O resíduo simples é calculado por:
Onde:
é a frequência observada;
é a frequência esperada.
Exemplo do cálculo do resíduo simples
Para Jovem × App:
Resíduos simples
Perfil do Cliente
App
Site
Telefone
Loja Física
Jovem
15,22
1,74
-8,70
-8,26
Adulto
-0,43
6,52
-2,61
-3,48
Idoso
-14,78
-8,26
11,30
11,74
Resíduos padronizados
O resíduo padronizado é calculado por:
Ele é mais útil do que o resíduo simples porque coloca os valores em uma escala comparável.
Exemplo do cálculo do resíduo padronizado
Para Jovem × App:
Exemplo da Tabela de resíduos padronizados
Perfil do Cliente
App
Site
Telefone
Loja Física
Jovem
3,42
0,41
-2,35
-1,93
Adulto
-0,09
1,35
-0,62
-0,72
Idoso
-3,32
-1,93
3,05
2,75
Os maiores resíduos positivos indicam as associações mais fortes entre categorias.
Neste exemplo, os principais destaques são:
Associação
Resíduo padronizado
Interpretação
Jovem × App
3,42
Jovens usam App mais do que o esperado
Idoso × Telefone
3,05
Idosos usam Telefone mais do que o esperado
Idoso × Loja Física
2,75
Idosos usam Loja Física mais do que o esperado
Jovem × Telefone
-2,35
Jovens usam Telefone menos do que o esperado
Idoso × App
-3,32
Idosos usam App menos do que o esperado
Teste Qui-quadrado
Ele verifica se existe associação estatística entre as duas variáveis categóricas:
Onde:
é a frequência observada.
é a frequência esperada.
Exemplo do cálculo de uma célula
Para Jovem × App:
Esse valor representa a contribuição da célula Jovem × App para o Qui-quadrado total.
Contribuições para o Qui-quadrado
Perfil do Cliente
App
Site
Telefone
Loja Física
Jovem
11,71
0,17
5,52
3,74
Adulto
0,01
1,81
0,39
0,52
Idoso
11,05
3,74
9,33
7,55
Somando todas as contribuições:
A fórmula dos graus de liberdade é:
Onde:
Neste Exemplo:
Resultado do teste
Estatística
Valor
Qui-quadrado calculado
55,51
Graus de liberdade
6
p-valor
0,00000000037
Nível de significância
0,05
Como o p-valor é muito menor que 0,05:
rejeitamos a hipótese nula de independência.
O resultado indica que existe associação estatisticamente significativa entre perfil do cliente e canal de atendimento.
Na prática, isso significa que a escolha do canal de atendimento não parece ocorrer de forma aleatória em relação ao perfil do cliente.
Os maiores responsáveis pelo valor do Qui-quadrado foram:
Associação
Contribuição
Jovem × App
11,71
Idoso × App
11,05
Idoso × Telefone
9,33
Idoso × Loja Física
7,55
Jovem × Telefone
5,52
Essas células mostram onde estão as maiores diferenças entre o observado e o esperado.
Resíduos padronizados ajustados (utilizar esse)
Após o cálculo dos resíduos padronizados, é possível aprofundar a análise utilizando os resíduos padronizados ajustados. Esses resíduos corrigem o efeito dos totais marginais das linhas e colunas, permitindo uma interpretação mais adequada da associação entre cada par de categorias.
A fórmula do resíduo padronizado ajustado é:
Como os resíduos padronizados ajustados se aproximam de uma distribuição normal padrão, podemos interpretar assim:
Valor do resíduo ajustado
Interpretação
Maior que 1,96
Associação positiva significativa
Menor que -1,96
Associação negativa significativa
Entre -1,96 e 1,96
Sem associação estatisticamente forte
Considerando nível de significância de 5%
indica que aquela célula contribui de forma relevante para a associação entre as variáveis.
No Exemplo:
No exemplo analisado, o perfil Jovem apresentou forte associação positiva com o canal App, enquanto o perfil Idoso apresentou associação positiva com Telefone e Loja Física. Por outro lado, clientes idosos apresentaram associação negativa com o uso de App, indicando que esse canal aparece menos do que seria esperado para esse perfil.
Resíduos padronizados ajustados
Perfil do Cliente
App
Site
Telefone
Loja Física
Jovem
4,84
0,59
-3,38
-2,75
Adulto
-0,13
2,10
-0,90
-1,11
Idoso
-4,70
-2,75
4,39
3,91
Principais associações do exemplo
Associação
Resíduo ajustado
Interpretação
Jovem × App
5,12
Associação positiva forte
Idoso × Telefone
4,32
Associação positiva forte
Idoso × Loja Física
4,01
Associação positiva forte
Idoso × App
-4,96
Associação negativa forte
Jovem × Telefone
-3,32
Associação negativa forte
Jovem × Loja Física
-2,82
Associação negativa
Idoso × Site
-2,82
Associação negativa
Adulto × Site
2,08
Associação positiva
Exemplo do cálculo: Jovem × App
Primeiro, usamos o resíduo padronizado da célula:
Agora calculamos o ajuste da linha e da coluna.
Total da linha Jovem:
Total da coluna App:
Total geral:
Então:
Conclusões: Células com associação positiva.
As células com resíduo ajustado maior que 1,96 são:
Associação
Resíduo ajustado
Interpretação
Jovem × App
4,84
Jovens tendem a utilizar mais o App
Adulto × Site
2,10
Adultos tendem a utilizar mais o Site
Idoso × Telefone
4,39
Idosos tendem a utilizar mais o Telefone
Idoso × Loja Física
3,91
Idosos tendem a utilizar mais a Loja Física
Elaboração do mapa perceptual
Passo a passo em calculo para chegar nos eixos do mapa perceptual.
Para a elaboração do mapa perceptual da Análise de Correspondência, inicialmente constrói-se a matriz A, formada pelos resíduos padronizados divididos pela raiz quadrada do total geral da tabela. Essa matriz representa os desvios padronizados entre as frequências observadas e esperadas.
Em seguida, calcula-se a matriz W, definida por:
A partir dessa matriz, os autovalores são obtidos pela solução da equação característica:
As raízes dessa equação correspondem aos autovalores, que indicam a quantidade de inércia (variância) explicada por cada dimensão. No exemplo analisado, a primeira dimensão apresentou autovalor igual a 0,2283, explicando 94,60% da inércia total. A segunda dimensão apresentou autovalor igual a 0,0130, explicando 5,40%.
Como a quantidade máxima de dimensões é dada por m=min(I−1,J−1), e a tabela possui três categorias nas linhas e quatro categorias nas colunas, tem-se:
Assim, o mapa perceptual pode ser representado em duas dimensões, correspondentes aos eixos e . Cada categoria recebe uma coordenada no plano, permitindo visualizar graficamente as associações entre perfis de clientes e canais de atendimento.
Autovalor:
Na Análise de Correspondência, os autovalores indicam a quantidade de inércia explicada por cada dimensão do mapa perceptual. Essa inércia pode ser interpretada como a quantidade de informação associativa representada em cada eixo.
Exemplo:
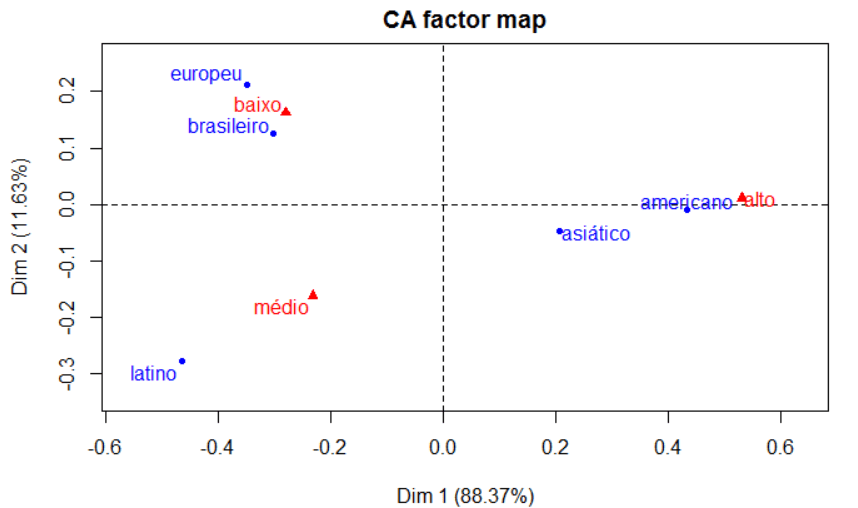
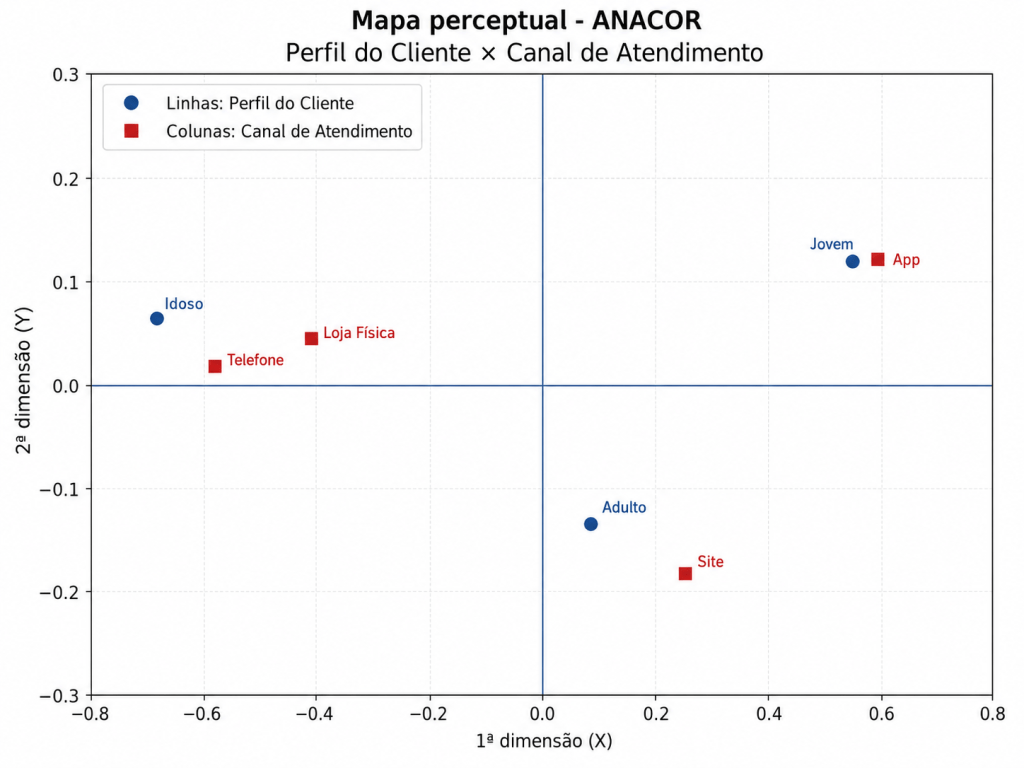
No exemplo, observa-se proximidade entre Jovem e App, indicando associação entre clientes jovens e uso do aplicativo. O perfil Adulto aparece mais próximo de Site, enquanto o perfil Idoso aparece próximo de Telefone e Loja Física. Portanto, o mapa perceptual confirma visualmente a associação entre Perfil do Cliente e Canal de Atendimento.
1. Construção da matriz A
Primeiro, parte-se da tabela de resíduos padronizados simples, calculados por:
Depois, cada resíduo padronizado é dividido pela raiz quadrada do total geral da tabela:
No exemplo Perfil do Cliente × Canal de Atendimento, temos:
Logo:
A matriz fica aproximadamente:
Perfil do Cliente
App
Site
Telefone
Loja Física
Jovem
0,2256
0,0268
-0,1549
-0,1275
Adulto
-0,0057
0,0887
-0,0410
-0,0473
Idoso
-0,2192
-0,1275
0,2014
0,1811
Essa matriz representa os desvios padronizados entre as frequências observadas e esperadas.
2. Construção da matriz W
Após montar a matriz , calcula-se sua transposta:
Em seguida, calcula-se a matriz :
Como tem dimensão 3×4, então:
e
A matriz W fica:
App
Site
Telefone
Loja Física
App
0,0990
0,0335
-0,0789
-0,0682
Site
0,0335
0,0248
-0,0335
-0,0307
Telefone
-0,0789
-0,0335
0,0663
0,0582
Loja Física
-0,0682
-0,0307
0,0582
0,0513
3. Determinação dos autovalores
Com base na matriz , os autovalores são obtidos por:
Onde:
W
é a matriz obtida por ;
representa os autovalores;
é a matriz identidade.
As raízes dessa equação são os autovalores.
No exemplo, os autovalores principais são:
Dimensão
Autovalor λ
% da inércia
1
0,2283
94,60%
2
0,0130
5,40%
Total
0,2413
100,00%
4. Cálculo dos valores singulares
Os valores singulares são calculados pela raiz quadrada dos autovalores:
Assim:
A tabela fica:
Dimensão
Autovalor λ
% Inércia
Valor Singular σ
1
0,2283
94,60%
0,4778
2
0,0130
5,40%
0,1141
Total
0,2413
100,00%
5. Quantidade máxima de dimensões
A quantidade máxima de dimensões é dada por:
No exemplo:
I = 3
porque existem 3 perfis:
e
J = 4
porque existem 4 canais:
Portanto:
m = 2
Logo, o mapa perceptual terá no máximo duas dimensões, que serão representadas pelos eixos e .
6. Coordenadas das categorias
Depois dos autovalores e autovetores, são calculadas as coordenadas das categorias no mapa perceptual.
Cada categoria recebe uma posição:
(x, y)
Onde:
Coordenadas dos perfis
Perfil do Cliente
Dimensão 1 / X
Dimensão 2 / Y
Jovem
0,5372
0,1154
Adulto
0,1028
-0,1402
Idoso
-0,6694
0,0649
Coordenadas dos canais
Canal de Atendimento
Dimensão 1 / X
Dimensão 2 / Y
App
0,5803
0,1156
Site
0,2489
-0,1825
Telefone
-0,5816
0,0187
Loja Física
-0,4413
0,0433
7. Interpretação do mapa perceptual
No mapa perceptual, categorias próximas indicam associação.
Neste exemplo:
Proximidade no mapa
Interpretação
Jovem próximo de App
Jovens estão mais associados ao uso do aplicativo
Adulto próximo de Site
Adultos estão mais associados ao uso do site
Idoso próximo de Telefone e Loja Física
Idosos estão mais associados a canais tradicionais
A Dimensão 1 explica 94,60% da inércia. Portanto, o eixo horizontal é o mais importante. Ele separa principalmente:
de:
A Dimensão 2 explica apenas 5,40%, ajudando no ajuste visual das categorias, mas com importância menor.
1. Autovalores do nosso exemplo
Para o exemplo Perfil do Cliente × Canal de Atendimento, os autovalores foram:
Dimensão
Autovalor λ
% Inércia
Valor Singular σ
1
0,2283
94,60%
0,4778
2
0,0130
5,40%
0,1141
Total
0,2413
100,00%
2. Como calcular a % de inércia
Na ANACOR, a ideia é parecida com PCA: cada dimensão explica uma parte da informação total. Mas, em vez de “variância”, usamos o termo inércia, porque estamos analisando a associação entre categorias.
A fórmula é:
Onde:
é o autovalor da dimensão analisada.
E:
é a soma de todos os autovalores não nulos.
Aplicando no nosso exemplo
A soma dos autovalores é:
Para a Dimensão 1:
Para a Dimensão 2:
Somando:
Ou seja:
A Dimensão 1, representada pelo eixo , explica aproximadamente 94,60% da inércia total. Isso significa que quase toda a associação entre Perfil do Cliente e Canal de Atendimento está concentrada nesse primeiro eixo.
A Dimensão 2, representada pelo eixo , explica aproximadamente 5,40% da inércia total. Ela ainda participa do mapa perceptual, mas tem peso muito menor na explicação da associação.
Portanto, no nosso exemplo, o eixo é muito mais importante para a interpretação do gráfico do que o eixo .
Qual categoria é mais representativa? Calcular as massas:
Na ANACOR, as massas mostram o peso relativo de cada categoria na tabela. Em termos simples, elas indicam quais categorias têm maior participação no total da amostra.
A massa é calculada dividindo o total da linha ou da coluna pelo total geral.
1. Tabela observada
Perfil do Cliente
App
Site
Telefone
Loja Física
Total
Jovem
35
20
5
10
70
Adulto
25
30
15
20
90
Idoso
5
10
25
30
70
Total
65
60
45
60
230
O total geral é:
n = 230
2. Massas das linhas
A massa da linha é calculada por:
Onde:
é o total da linha, e:
n
é o total geral da tabela.
Tabela de massas das linhas
Perfil do Cliente
Total da linha
Massa
Jovem
70
0,3043
Adulto
90
0,3913
Idoso
70
0,3043
Total
230
1,0000
A categoria de linha mais representativa é:
porque possui a maior massa:
Ou seja, os adultos representam aproximadamente:
do total da amostra.
Tabela de massas das colunas
Canal de Atendimento
Total da coluna
Massa
App
65
0,2826
Site
60
0,2609
Telefone
45
0,1957
Loja Física
60
0,2609
Total
230
1,0000
A categoria de coluna mais representativa é:
porque possui a maior massa:
Ou seja, o canal App representa aproximadamente:
do total de atendimentos.
As massas indicam quais categorias têm maior peso no conjunto de dados.
No exemplo:
Tipo de categoria
Categoria mais representativa
Massa
Percentual
Linha
Adulto
0,3913
39,13%
Coluna
App
0,2826
28,26%
Portanto, a categoria mais representativa entre os perfis é Adulto, enquanto a categoria mais representativa entre os canais é App.
Mas atenção: massa alta não significa necessariamente maior associação. A massa mostra o peso da categoria na amostra. Já a associação é analisada pelos resíduos padronizados ajustados e pela posição no mapa perceptual.
AutoVetores:
Indicam a direção dos eixos fatoriais. Eles ajudam a determinar como as categorias serão posicionadas no espaço.
Mapa Perceptual da Anacor:
ACM
O ACM apresenta a mesma lógica da ANACOR.
Também fazemos o teste estatístico Qui-quadrado, lembrando que o qui-quadrado são sempre em pares de variáveis.
Uma das diferenças no python da ANACOR e MCA, é que na ANACOR o input é a matriz de contingência, mas na MCA é o banco de dados com as variáveis categóricas. OBS.: no MCA deve se excluir a coluna ID entra apenas as variáveis.
Técnica
Input mais comum em Python
Objetivo
ANACOR / CA
Matriz de contingência
Analisar associação entre duas variáveis categóricas
MCA
Base de dados com várias variáveis categóricas
Analisar associação entre múltiplas variáveis categóricas
Exemplo: MCA aplicada ao perfil de consumo em plataformas de streaming.
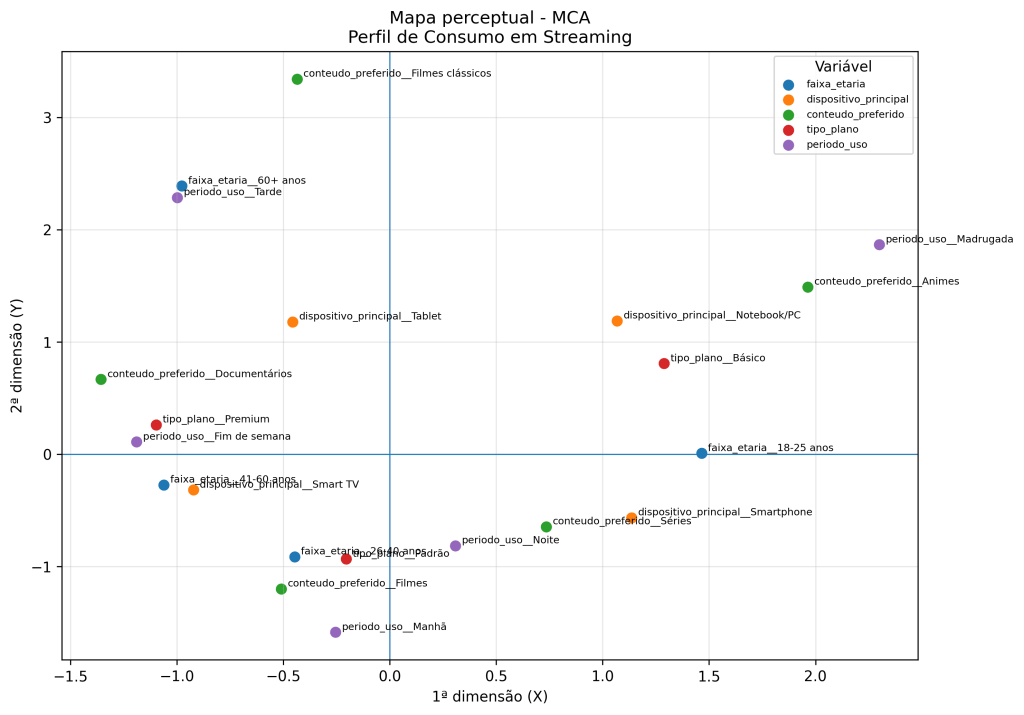
Na MCA, os autovalores indicam a quantidade de inércia explicada por cada dimensão. No exemplo analisado, a primeira dimensão explicou 21,97% da inércia total, enquanto a segunda dimensão explicou 17,96%. Somadas, as duas primeiras dimensões representam 39,93% da informação associativa presente nos dados. Portanto, o mapa perceptual bidimensional permite visualizar parte importante da estrutura de associação entre as categorias, embora não represente toda a inércia do conjunto de dados.
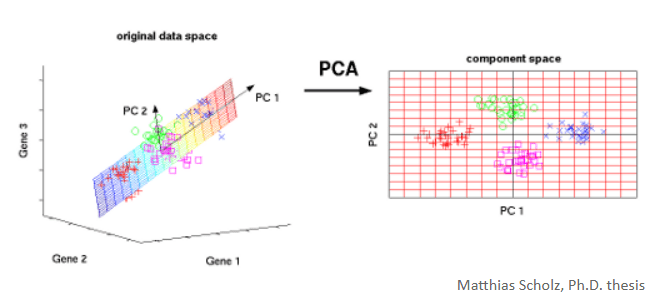
Este projeto tem como objetivo criar um indicador sintético para critério de preço de imóveis, utilizando PCA / Análise Fatorial.
A ideia principal é consolidar várias características dos imóveis em uma única métrica, permitindo criar um ranking de imóveis com base em fatores extraídos das variáveis originais.
Etapa
Tópico
Ideia principal
Plot
0
Verificar variáveis métricas
Garantir que a PCA use apenas variáveis numéricas.
Gráfico de tipos das variáveis
1
Outliers
Verificar imóveis com características muito fora do padrão.
Boxplots por variável
2
Correlação de Pearson
Avaliar se existe relação linear entre as variáveis.
Heatmap de correlação
3
Esfericidade de Bartlett
Testar se a matriz de correlação é diferente da identidade.
Gráfico do p-valor vs. 0,05
4
Autovalores e Kaiser
Selecionar fatores com autovalor maior ou igual a 1.
Barras dos autovalores
5
Autovetores
Mostrar as direções matemáticas dos fatores.
Heatmap dos autovetores
6
Cargas fatoriais
Interpretar o conteúdo de cada fator.
Barras das cargas + loading plot
7
Comunalidades
Ver quanto cada variável continua representada após selecionar fatores.
Barras das comunalidades
8
Extração dos fatores
Gerar o valor de cada fator para cada imóvel.
Histograma dos fatores e plano fatorial
9
Scores fatoriais
Mostrar os pesos das variáveis padronizadas na formação dos fatores.
Barras dos scores fatoriais
10
Ranking
Criar o indicador ponderando os fatores pela variância explicada.
Top 10 ranking + dispersão indicador vs. preço real
Utiliza somente Variáveis Métricas (quantitativas), pois utiliza método/correlação de Person.
Objetivo é agrupamento em fatores.
Muito utilizado para diminuir a dimensão, a quantidade de variáveis, exemplo, de 200 variáveis métricas diminui para 102 variáveis métricas.
Exemplos de utilização:
Criar um indicador/ranking que seja utilizado como critério de preço.
Um método exploratório sem fins preditivos.
Análise de Construtos
Identificação de Padrões: agrupando variáveis que medem o mesmo construto subjacente.
Redução de quantidade de variáveis: Redução de quantidade de variáveis métricas.
Eliminação de Redundância: Remove informações redundantes, mantendo a variabilidade principal dos dados de origem.
Funcionamento
Antes de iniciar
Análise preliminar, verifificar a correlação de Pearson (1) e esfericidade de Bartlett (2), antes de prosseguir com PCA.
Correlação de Pearson.
PCA se basei nas correlações entre variáveis para criar os fatores, correlação de Pearson (relação linear entre 2 variáveis) e se são estatisticamente significantes.
O coeficiente de correlação de Pearson mede a intensidade e a direção da relação linear entre duas variáveis. Ele é calculado pela razão entre a covariância das variáveis e o produto dos seus respectivos desvios-padrão.
Em termos matemáticos:
De forma simplificada, podemos interpretar a fórmula como: Covariância de 2 variáveis, dividido pelo produto dos 2 desvios padrão.
ou seja:
A covariância, presente no numerador, indica se duas variáveis tendem a variar na mesma direção ou em direções opostas. Já os desvios-padrão, no denominador, padronizam essa relação, permitindo que o coeficiente fique limitado entre -1 e 1.
Assim:
Interpretação:
Valor de (ρ)
Interpretação
Próximo de 1
Forte correlação positiva
Próximo de -1
Forte correlação negativa
Próximo de 0
Baixa ou nenhuma relação linear
No contexto do PCA, essa matriz é usada para entender como as variáveis se relacionam entre si. Quando há variáveis muito correlacionadas, o PCA consegue combinar essas informações em novos componentes principais, reduzindo a dimensionalidade dos dados sem perder muita informação.
2) Adequação Global da análise fatorial com método de Esfericidade de Bartlett
Após a construção da matriz de correlações de Pearson, foi aplicado o teste de esfericidade de Bartlett com o objetivo de avaliar a adequação global dos dados à análise fatorial/PCA.
No teste de esfericidade de Bartlett, a hipótese nula estabelece que a matriz de correlações de Pearson é igual à matriz identidade .
Isso significa que as correlações entre as variáveis fora da diagonal principal são nulas, indicando ausência de associação linear entre elas.
Já a hipótese alternativa afirma que a matriz de correlações é diferente da matriz identidade, ou seja, existe correlação entre pelo menos algumas variáveis, tornando a aplicação do PCA mais adequada.
No teste de esfericidade de Bartlett, as hipóteses são:
Hipótese nula H0: A hipótese nula H0 afirma que a matriz de correlações de Pearson é igual à matriz identidade. Portanto, se não rejeitamos H0, entende-se que a matriz de correlações é próxima da identidade, indicando pouca ou nenhuma correlação entre as variáveis. Nesse caso, o PCA não é muito indicado.
Hipótese alternativa H1: A hipótese alternativa H1 afirma que a matriz de correlações de Pearson é diferente da matriz identidade. Portanto, se rejeitamos H0, geralmente com p-valor < 0,05, conclui-se que a matriz de correlações difere significativamente da identidade, indicando que há correlação suficiente entre as variáveis para prosseguir com o PCA.
Ou seja, queremos testar se as variáveis são praticamente não correlacionadas entre si.
Se não rejeitamos H0H_0H0: a matriz de correlações é próxima da identidade → PCA não é muito indicado. Se rejeitamos H0H_0H0, com p-valor < 0,05: a matriz de correlações difere da identidade → há correlação suficiente para prosseguir com o PCA.
Se o resultado for a hipótese H1 (alternativa), ou seja, matriz de correlação de Person é diferente de uma matriz de identidade.
Iniciando PCA (extração dos fatores)
Autovalor
A dimensão da matriz sempre será quantidade de variáveis que tem, e a quantidade de autovalores tambem, ou seja, 4 observações = 4 dimensões de uma matriz e = 4 autovalores = 4 fatores.
A matriz de correlações de Pearson , com dimensão , possui autovalores , que são obtidos a partir da seguinte condição:
det(ρ−λI)=0
Essa expressão representa a equação característica da matriz. Ao resolver essa equação, encontramos suas raízes, que correspondem aos autovalores.
De forma expandida, temos a matriz:
No contexto do PCA, os autovalores indicam a quantidade de variância explicada por cada componente principal. Quanto maior o autovalor, maior é a parcela de informação dos dados originais representada por aquele componente.
Em outras palavras, os autovalores ajudam a identificar quais componentes concentram mais variabilidade e, portanto, quais são mais importantes para resumir a estrutura dos dados.
Exemplo:
Ou seja, percentual de variância dos dados originais, ou seja, a quantidade de informações está contida naquele Fator
Autovetor
Os autovetores indicam como as variáveis originais se combinam para formar cada componente principal. Cada autovetor está associado a um autovalor e representa uma direção de maior variação dos dados. No PCA, esses vetores mostram quais variáveis têm maior peso em cada componente, permitindo interpretar os padrões de correlação existentes entre elas.
Para cada autovalor eu tenho 1 autovetor. Ou seja, para cada autovalor encontrado, existe um autovetor correspondente que indica a direção do componente principal.
Após a obtenção dos autovalores da matriz de correlações de Pearson , calcula-se o respectivo autovetor associado a cada autovalor
Os autovetores são obtidos resolvendo o seguinte sistema:
Em forma matricial:
Ou seja, para cada autovalor encontrado, existe um autovetor correspondente que indica a direção do componente principal.
De forma expandida, o sistema pode ser representado como:
No contexto do PCA, os autovetores representam as combinações lineares das variáveis originais que formam os componentes principais.
Em outras palavras, eles indicam o peso de cada variável em cada componente. Assim, ajudam a entender quais variáveis contribuem mais para cada dimensão extraída pelo PCA.
Fatores
Para formar os fatores por combinação linear das variáveis originais, calculam-se os scores fatoriais. Em geral, pode-se obter até K scores, onde K corresponde ao número de variáveis do conjunto de dados. Esses scores são determinados com base nos autovalores e autovetores da matriz de correlações, representando os pesos utilizados na construção de cada fator.
Como, em resumo o valor do autovalor dividido pela raiz quadrada do respectivo autovetor.
De forma expandida:
Como neste exemplo foram utilizadas três variáveis — Atendimento, Preço e Qualidade — podem ser gerados até três scores fatoriais, um para cada componente principal.
Os scores fatoriais são obtidos pela divisão de cada elemento do autovetor pela raiz quadrada do respectivo autovalor.
Variável
Score Fatorial 1
Score Fatorial 2
Score Fatorial 3
Atendimento
0,343
0,803
6,136
Preço
-0,335
2,684
1,437
Qualidade
0,340
1,839
-4,776
Esses valores foram obtidos a partir dos autovetores e autovalores do exemplo.
O Score Fatorial 1 é o mais importante para a interpretação inicial, pois está associado ao maior autovalor e, portanto, ao componente que explica a maior parte da variância dos dados.
Nesse primeiro fator, observamos que:
Atendimento possui peso positivo;
Qualidade possui peso positivo;
Preço possui peso negativo.
Assim, o primeiro fator representa um contraste entre Atendimento/Qualidade e Preço. Em outras palavras, ele resume a principal estrutura dos dados: quanto maiores os valores associados a atendimento e qualidade, menor tende a ser o peso associado ao preço.
A ideia é:
Onde:
Z representa a variável padronizada;
s11,s21,s31 são os scores fatoriais do Fator 1.
Variável
Score Fatorial 1
Score Fatorial 2
Score Fatorial 3
Atendimento
0,343
0,803
6,202
Preço
-0,335
2,686
1,452
Qualidade
0,340
1,840
-4,826
Fórmula do Fator 1
Como o primeiro fator é formado pela combinação linear das variáveis padronizadas, temos:
Variável
Valor padronizado
Z_Atendimento
0,935
Z_Preço
-0,935
Z_Qualidade
1,154
Aplicando no Fator 1:
F1=0,343(0,935)−0,335(−0,935)+0,340(1,154)
Ou seja, a Observação 1 teria score aproximado de 1,026 no primeiro fator.
Após calcular os scores fatoriais, cada fator pode ser representado como uma combinação linear das variáveis padronizadas. No exemplo analisado, o primeiro fator foi formado pelos pesos de Atendimento, Preço e Qualidade. Como Atendimento e Qualidade possuem pesos positivos, enquanto Preço possui peso negativo, esse fator representa principalmente um contraste entre percepção de qualidade/atendimento e preço. Assim, cada observação passa a ter um novo valor no fator, calculado a partir da soma ponderada das variáveis padronizadas.
Carga Fatorial
Auxilia também na análise exploratória.
Correlação das observações com os fatores.
Variável
Fator 1
Fator 2
Fator 3
Comunalidades
Atendimento
0,993
0,071
0,097
1,000
Preço
-0,971
0,239
0,023
1,000
Qualidade
0,984
0,164
-0,076
1,000
Medida
Fator 1
Fator 2
Fator 3
Autovalores
2,895
0,089
0,016
Variância explicada
96,51%
2,96%
0,52%
Variância acumulada
96,51%
99,48%
100,00%
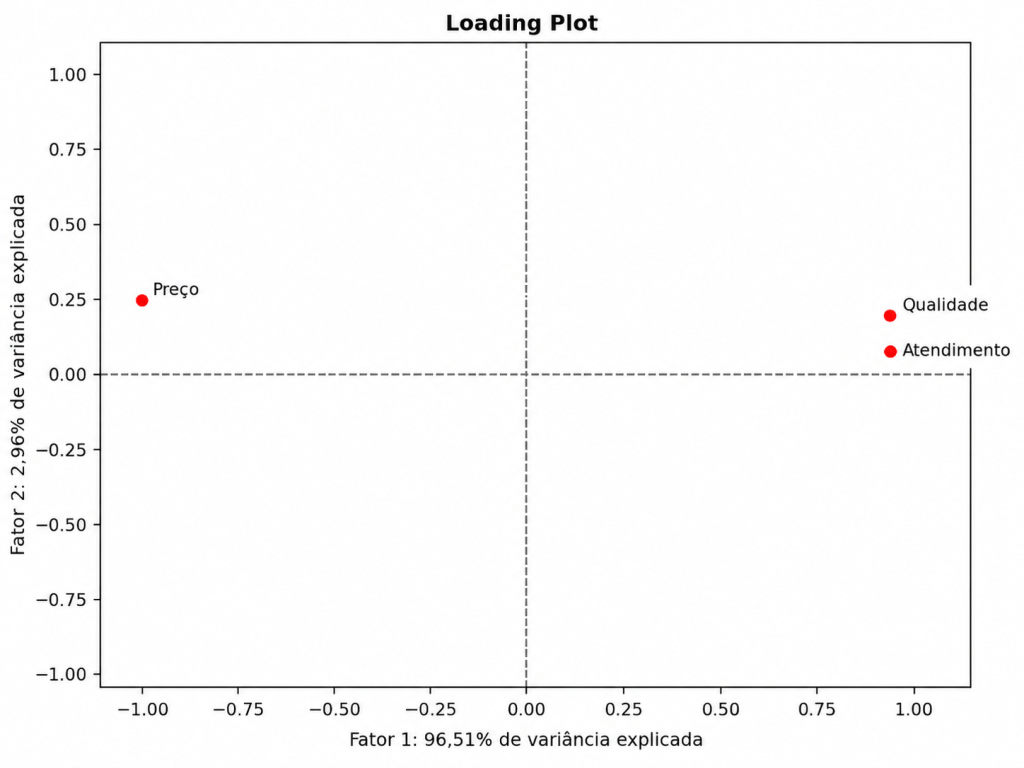
No Fator 1 concentra quase toda a informação dos dados, pois apresenta autovalor igual a 2,895 e explica aproximadamente 96,51% da variância total.
As maiores cargas fatoriais do Fator 1 aparecem em:
Atendimento=0,993
Preço=−0,971
Qualidade=0,984
Isso indica que o primeiro fator está fortemente associado a Atendimento e Qualidade, mas em sentido contrário ao Preço.
Como o Fator 2 e o Fator 3 possuem autovalores menores que 1, eles explicam pouca variância individualmente. Pelo critério de Kaiser, manteríamos apenas o Fator 1, pois:
Portanto, as cargas fatoriais indicaram que o primeiro fator possui forte associação positiva com Atendimento e Qualidade, enquanto a variável Preço apresentou associação negativa. Isso sugere que o Fator 1 resume uma dimensão relacionada à percepção de qualidade e atendimento em oposição ao preço. Como esse fator apresentou autovalor igual a 2,895 e explicou 96,51% da variância total, ele concentrou a maior parte da informação dos dados. Pelo critério de Kaiser, apenas esse fator seria mantido, pois foi o único com autovalor superior a 1.
Comunalidade
Quando você trabalha com todos os fatores possíveis, ou seja, quantidade de variáveis, não tenho nenhum tipo de perda de informação das variáveis originais.
Então nós dissemos que as comunalidade seriam a perda da variância se acaso retirar Fatores, quanto de informação perderiamos.
Ou seja,
Fator
Autovalor
Variância explicada
Fator 1
2,895
96,51%
Fator 2
0,089
2,96%
Fator 3
0,016
0,52%
Se manter apenas o Fator 1, a variância total explicada pelo modelo fica:
96,51%
E a parte que fica fora do modelo é:
100%−96,51%=3,49%
Ou seja, deixaria de explicar aproximadamente:
2,96%+0,52%=3,48%
Essa diferença é pequena, por isso manter só o Fator 1 faz sentido nesse exemplo.
Calcular o Fator e Score fatorial em cada observação
Scores fatoriais / coeficientes do fator: são os pesos usados na fórmula.
Valor do fator em cada linha: é o resultado da fórmula aplicada em cada observação.
No exemplo, mantendo apenas o Fator 1, a fórmula fica:
Ou seja, para cada linha da base, primeiro padronizamos as variáveis e depois aplicamos os pesos do fator.
1. Padronização das variáveis
Antes de calcular o fator, cada variável precisa ser transformada em valor padronizado Z:
Onde:
Variável
Média
Desvio-padrão
Atendimento
6,500
1,604
Preço
6,500
1,604
Qualidade
7,375
1,408
2. Fórmula do Fator 1
Após a padronização, aplicamos os pesos do Fator 1:
3. Exemplo calculado em uma linha
Para a Observação 1, os valores originais eram:
Observação
Atendimento
Preço
Qualidade
1
8
5
9
Os valores padronizados ficam aproximadamente:
Variável
Valor padronizado
Z_Atendimento
0,935
Z_Preço
-0,935
Z_Qualidade
1,154
Aplicando na fórmula:
Portanto, a Observação 1 tem valor aproximado de 1,027 no Fator 1.
Resultado para todas as observações:
Observação
Z_Atendimento
Z_Preço
Z_Qualidade
Fator 1
1
0,935
-0,935
1,154
1,027
2
0,312
0,312
0,444
0,153
3
1,559
-1,559
1,154
1,449
4
-0,312
-0,312
-0,266
-0,093
5
0,312
-0,312
0,444
0,362
6
-0,935
0,935
-0,977
-0,966
7
-1,559
1,559
-1,687
-1,631
8
-0,312
0,312
-0,266
-0,302
O valor do fator em cada linha representa uma nova pontuação criada a partir das variáveis originais padronizadas.
Essa pontuação resume o comportamento conjunto das variáveis em um único indicador.
No exemplo, o Fator 1 resume principalmente a relação positiva entre Atendimento e Qualidade e a relação oposta com Preço.
Seleção de fatores
Depois de calcular autovalores, cargas fatoriais, comunalidades e fatores, o próximo passo é decidir quantos fatores manter na análise.
Nem sempre usamos todos os fatores. A decisão pode ser feita observando a magnitude dos autovalores.
No nosso exemplo, os autovalores foram aproximadamente:
Fator
Autovalor
Variância explicada
Fator 1
2,895
96,51%
Fator 2
0,089
2,96%
Fator 3
0,016
0,52%
Pelo critério de Kaiser, mantemos apenas os fatores com autovalor maior que 1:
No exemplo acima:
Portanto, apenas o Fator 1 seria mantido.
O Fator 1 sozinho explica aproximadamente:
da variância total dos dados.
Isso significa que ele já resume quase toda a informação presente nas três variáveis originais. Os Fatores 2 e 3 explicam parcelas muito pequenas da variância e, por isso, não teriam tanta representatividade nesse exemplo.
Comunalidade após escolher alguns fatores
No exemplo acima, ao manter apenas o Fator 1, as comunalidades deixam de ser iguais a 1,000, pois os demais fatores foram retirados da análise.
Nesse caso, a comunalidade de cada variável representa a parcela da sua variância explicada somente pelo primeiro fator.
No exemplo analisado, o Fator 1 explicou 98,6% da variância de Atendimento, 94,3% da variância de Preço e 96,8% da variância de Qualidade, indicando que um único fator já representa muito bem as três variáveis originais.
Agora se escolher 2 fatores, ou seja, Fator 1 e Fator 2, a comunalidade de cada variável será a soma dos quadrados das cargas fatoriais desses dois fatores.
A fórmula fica:
Ou seja:
as cargas fatoriais eram aproximadamente:
Variável
Fator 1
Fator 2
Atendimento
0,993
0,071
Preço
-0,971
0,239
Qualidade
0,984
0,164
Então, as comunalidades com 2 fatores ficam:
Variável
Cálculo
Comunalidade
Atendimento
0,9932+0,0712
0,991
Preço
(−0,971)2+0,2392
1,000
Qualidade
0,9842+0,1642
0,995
Em percentual:
Variável
Comunalidade com 2 fatores
Atendimento
99,1%
Preço
100,0%
Qualidade
99,5%
Comparando:
Variável
Comunalidade com 1 fator
Comunalidade com 2 fatores
Atendimento
0,986
0,991
Preço
0,943
1,000
Qualidade
0,968
0,995
Criação de ranking
Ponderação dos fatores e respectivas variâncias explicadas.
Dar maior peso aos fatores que explicam maior quantidade de variância dos dados.
A lógica é:
Cada observação recebe um valor em cada fator. Depois, esses fatores são combinados em uma única pontuação final, usando como peso a variância explicada por cada fator.
Ou seja, fatores que explicam mais variância recebem maior peso no ranking.
Técnicas de cluster são técnicas não supervisionadas e exploratórias, sem fins para criação de modelo preditivo, não se faz previsão. Apenas criação de grupos.
Se novas observações entrarem na amostra, ou sairem, deve se executar novamente a criação de clusters.
Tanto o Método Hierárquico Aglomerativo quanto o Método Não Hierárquico K-means são técnicas de análise de agrupamentos (clusterização) projetadas para funcionar com variáveis quantitativas (numéricas/contínuas).
A diferença essencial, é que no K-means você precisa informar quantos clusters irá se formar, ao contrário do método hierárquico que agente escolhe após o dendograma.
Escalas das medidas das variáveis deve ser pequena (exemplo 1 a 10) , se não estiver , deve se realizar a normalização, exemplo por z-score. Pois essas grandes amplitudes podem dominar os clusters.
Método hierarquico aglomerativo. (para análise)
O método hierárquico aglomerativo é uma técnica de aprendizado não supervisionado que agrupa dados “de baixo para cima”.
Método muito utilizado em analise exploratória e a quantidade de cluster é definida ao longo da analise.
Método não hierarquico K-means.
Deve se definir antes quantos grupos de cluster serão encontrados.
Método que se baseia na minimização.
Método hierarquico aglomerativo. (distância)
O quanto os grupos são diferentes entre si.
ANTES de iniciar:
Verificar se as suas variáveis possuem unidade de medidas/ amplitudes muito distintas, muito grandes.
Se for, deve-se utilizar a padronização em todas varáveis. Como? Ex. Z-score, passando a ter médias 0 e desvio padrão 1.
deve-se fazer o passo 1 e 2, pois impactam muito nos resultados da clusterização, onde variáveis com grandes amplitydes/distancia acabam dominando na clusterização.
Depois escolher entre:
Medida de dissimilaridade: se eu quero que os grupos sejam mais homogêneos internamente e heterogêneo entre si, tenho que decidir qual medida diga quais são as observações parecidas e quais são diferentes.
Método de encadeamento.
Qual o padrão de agrupamento.
Exemplo calculo:
Decidir a medida de distancia (dissimilaridade): QUANTO Maior a distância mais diferentes são entre 2 pontos.
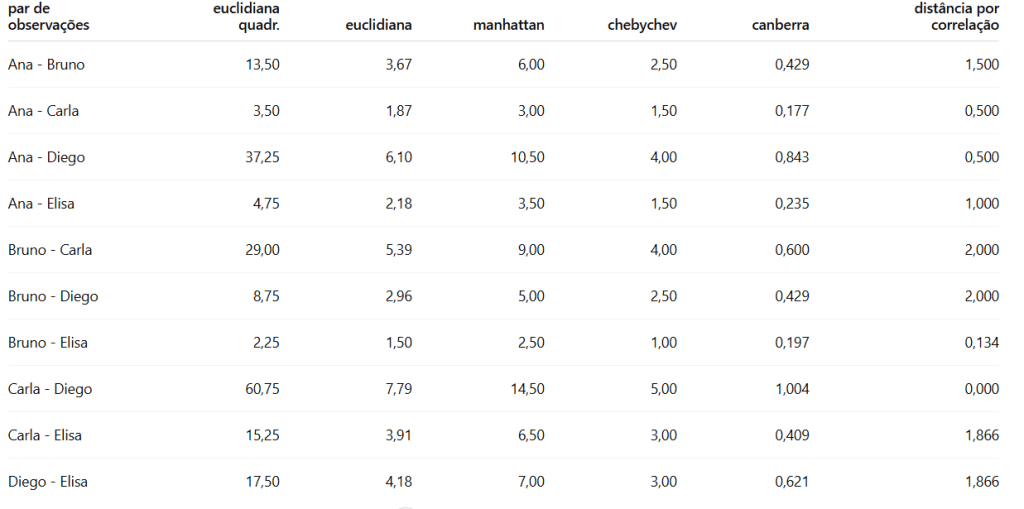
Exemplo: Para calcular a distância, normalmente utiliza-se uma das medidas: euclidiana, euclidiana quadrática ou distância de Manhattan, distância de Chebychev, distância de Canberra (proporção), ou até a correlação de Pearson entre as observações.
Exemplo, conforme a tabela abaixo, que já estão na mesma escala de 0 a 10, ou seja, não precisa normalizar.
Seguem as distâncias:
Distância Euclidiana Quadrática:
Ou seja, distância euclidiana quadrática entre Ana e Bruno é 13,50.
Escolho a metrica de distância/dissimilaridade, muito utilizada a euclidiana e vou unindo os pares com menores distâncias, criando os clusters.
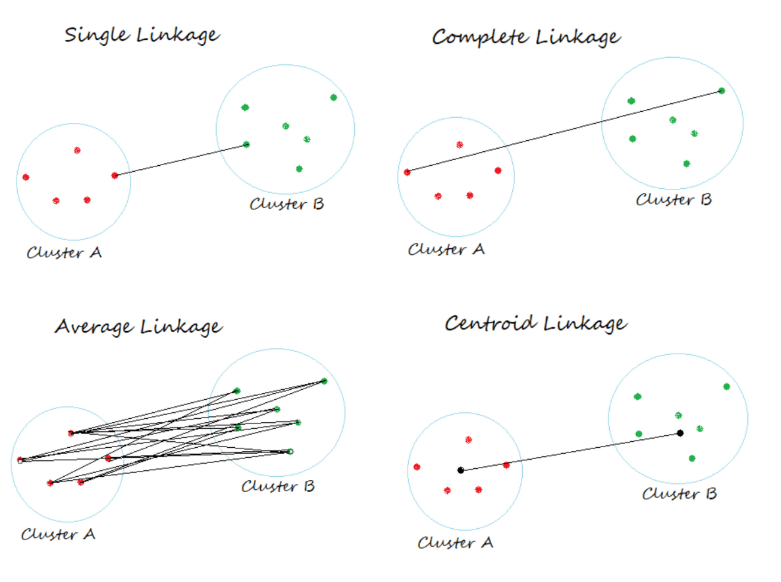
Agora entra o método de encadeamento.
Ligação Simples (Single Linkage)/(vizinho mais próximo): Define a distância entre dois clusters como a menor distância entre qualquer ponto do primeiro cluster e qualquer ponto do segundo cluster.
Ligação Completa (Complete Linkage): Define a distância entre dois clusters como a maior distância entre qualquer ponto do primeiro cluster e qualquer ponto do segundo cluster.
Ligação Média (Average Linkage): Calcula a distância entre dois clusters como a média das distâncias entre todos os pares de pontos (um de cada cluster).
O método de Ward é uma técnica de análise de agrupamento hierárquico (clustering) que minimiza a variância dentro dos clusters. Ele agrupa observações maximizando a homogeneidade interna, ideal para variáveis quantitativas e para criar grupos de tamanhos similares. O processo aglomerativo une, a cada etapa, os dois grupos que resultam no menor aumento da soma dos quadrados.
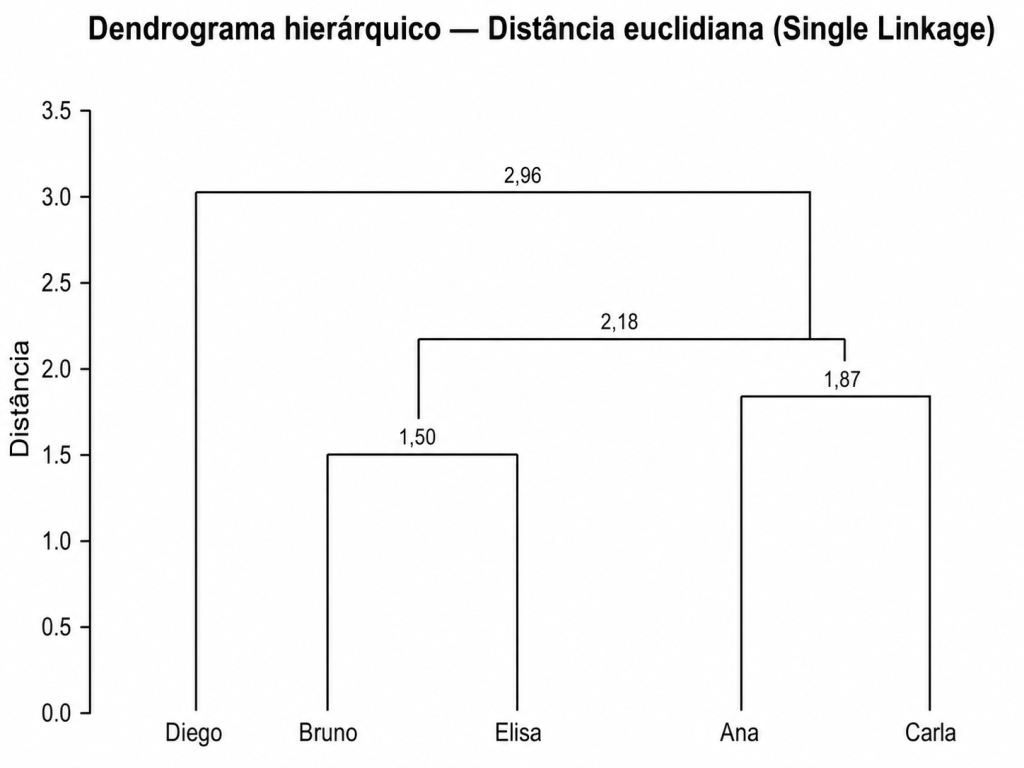
Por fim, vai unindo todas as observações, no exemplo acima todas as pessoas, até o fim, criando um Dendograma:
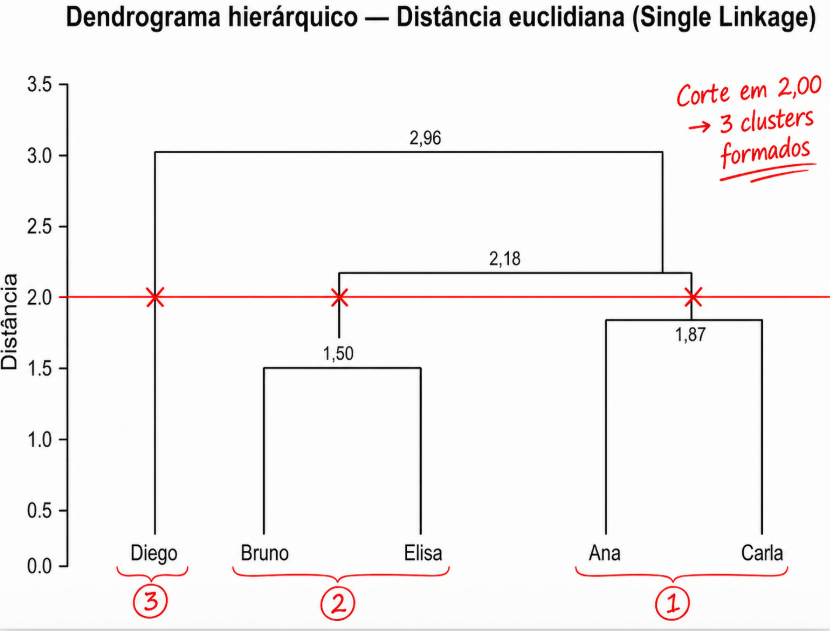
Estabelecer um corte, quantas barras verticais cortou ?
veja que verifico logo abaixo da minha linha de corte, quantas | barras tem logo abaixo, no caso são 3 | barras, exemplificada com X em vermelho.
Em Python posso criar uma variável categórica com o valor do cluster a qual aquela observação pertence:
Utiliza critério de minimização. Busca minimização a distância de cada observação até o centróide daquela observação.
K Clusters deve ser escolhidos antes, os centróides, cada centróide vai gerar 1 cluster.
Depois o k-means aloca as observações mais próximas desses centróides.
A solução final indica que a soma dos quadrados das distâncias entre cada observação e o centro do cluster ao qual ela foi alocada, conhecida como WCSS, foi minimizada. Essa solução é alcançada quando os centróides não se alteram mais significativamente entre as iterações.
Onde:
xi é a observação i;
μk é o centróide do cluster k;
zik indica se a observação i pertence ao cluster k;
K é o número de clusters.
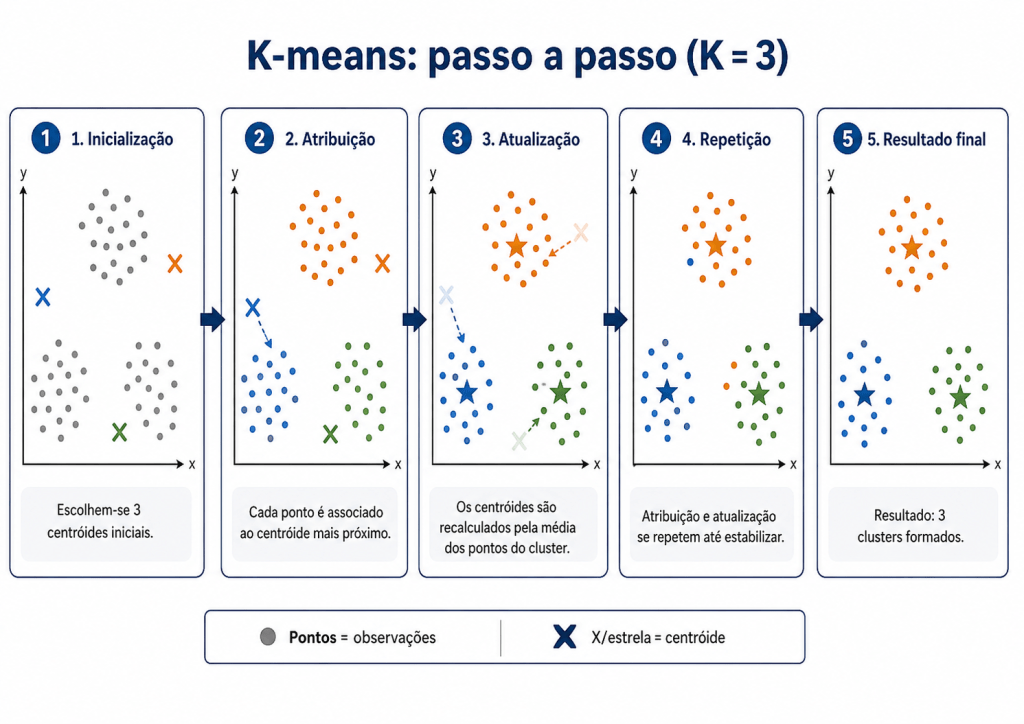
Como funciona o K-means?
Inicialização dos centróides O algoritmo começa escolhendo K centróides iniciais, que representam os centros provisórios dos grupos. Esses pontos podem ser escolhidos aleatoriamente no espaço dos dados.
Atribuição dos pontos aos clusters Em seguida, cada ponto do conjunto de dados é associado ao centróide mais próximo, de acordo com uma medida de distância, como a distância euclidiana. Assim, são formados os primeiros K clusters.
Atualização dos centróides Depois que os pontos são atribuídos aos clusters, o algoritmo recalcula a posição de cada centróide. O novo centróide passa a ser a média dos pontos pertencentes ao respectivo grupo.
Repetição do processo As etapas de atribuição dos pontos e atualização dos centróides são repetidas várias vezes. A cada iteração, os grupos tendem a ficar mais ajustados.
Critério de parada O processo termina quando os centróides deixam de mudar significativamente ou quando o algoritmo atinge um número máximo de iterações definido previamente.
Resultado final Ao final, cada ponto estará associado a um dos K clusters, de forma que os pontos dentro de um mesmo grupo sejam mais semelhantes entre si do que em relação aos pontos de outros grupos.
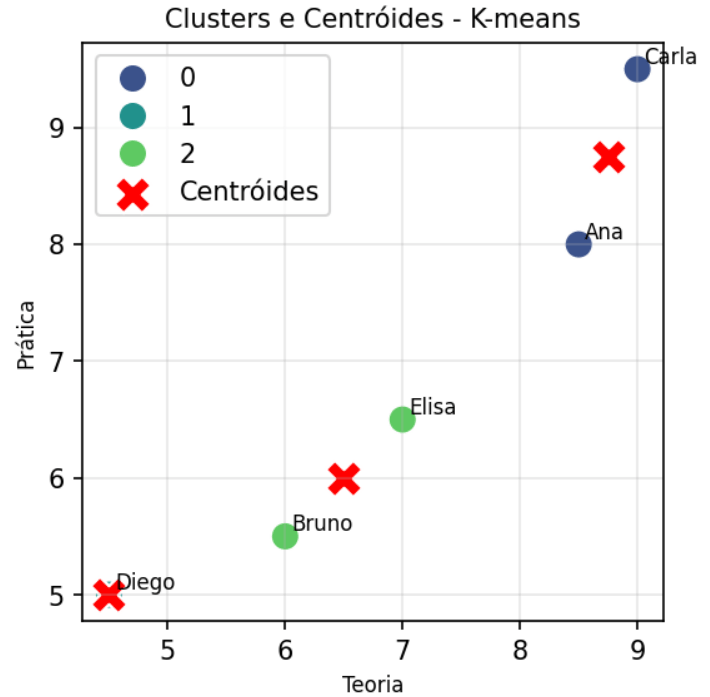
Conforme o mesmo exemplo de Métodos Hierarquicos Aglomerativos, abaixo estão a formação de clusters com K-means.
Como escolher quantos clusters ?
A definição do número de clusters, representado por K, é uma etapa importante no uso do algoritmo K-means. Como o modelo exige que esse valor seja informado previamente, algumas técnicas podem ajudar a identificar uma quantidade adequada de grupos.
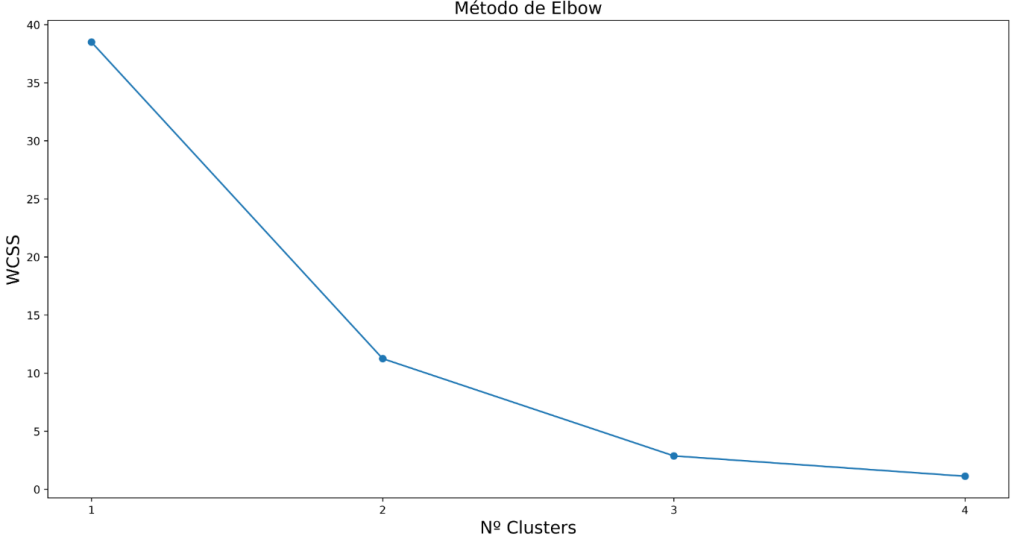
Método Cotovelo (Elbow):
O Método do Cotovelo avalia diferentes valores de K e calcula, para cada um deles, a soma dos quadrados das distâncias dentro dos clusters, conhecida como WCSS.
À medida que o número de clusters aumenta, a WCSS tende a diminuir, pois os grupos ficam menores e os pontos ficam mais próximos de seus respectivos centróides. No entanto, chega um momento em que aumentar o número de clusters gera pouca melhoria adicional.
No gráfico, esse ponto costuma aparecer como uma “dobra” ou “cotovelo”. Esse valor de K é considerado uma boa escolha, pois representa um equilíbrio entre simplicidade e qualidade do agrupamento.
O ponto onde a curva “dobra”.
No Método do Cotovelo, quanto menor o WCSS, mais próximos os pontos estão dos centróides de seus respectivos clusters.
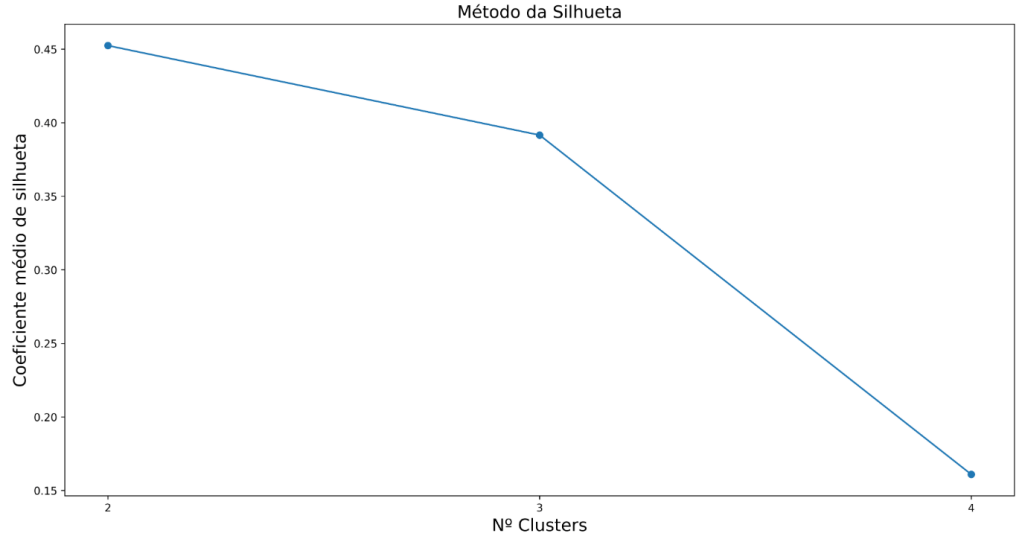
Método da Silhueta
O Método da Silhueta avalia o quanto cada observação está bem alocada dentro do seu cluster. Para isso, são consideradas duas medidas principais:
a: distância média da observação em relação aos pontos do cluster ao qual ela pertence;
b: distância média da observação em relação ao cluster mais próximo ao qual ela não pertence.
Com essas duas informações, calcula-se o coeficiente de silhueta para cada observação. Depois, obtém-se a média dos coeficientes de todas as observações.
Esse procedimento é repetido para diferentes valores de K. Em geral, quanto maior o coeficiente médio de silhueta, melhor tende a ser a separação entre os clusters.
Análise:
Entender quais variáveis ajudaram mais a diferenciar os grupos formados. Ou qual variavel mais influenciou na separação de pelo menos um dos Clusters.
A ANOVA pode ser utilizada como uma análise complementar para verificar quais variáveis mais diferenciam os clusters formados pelo K-means. Em geral, quanto maior a estatística F, maior a diferença entre as médias dos clusters em relação à variabilidade interna dos grupos.
*No exemplo há apenas 5 estudantes, com uma amostra tão pequena, o p-valor não deve ser interpretado com muita força estatística.
Uma forma de fazer essa análise é comparar a variabilidade existente entre os clusters com a variabilidade existente dentro dos clusters. A lógica é simples: uma variável tende a ser mais relevante para separar os grupos quando apresenta médias bem diferentes entre os clusters e, ao mesmo tempo, menor dispersão dentro de cada grupo.
Para isso, pode-se utilizar a análise de variância [ANOVA], por meio da estatística F:
Na prática, quanto maior o valor da estatística F, maior tende a ser a capacidade daquela variável em diferenciar os agrupamentos.
Os graus de liberdade utilizados nesse teste são:
Em que:
representa o número de clusters;
representa o tamanho da amostra.
Assim, após formar os clusters, é possível avaliar quais variáveis mais contribuíram para a separação dos grupos. As variáveis com maiores valores da estatística F, principalmente quando acompanhadas de significância estatística, tendem a ser as mais discriminantes na formação dos clusters.
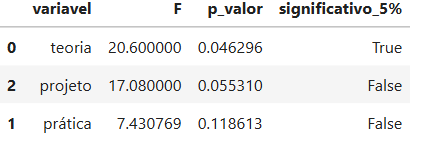
Variável mais discriminante: teoria Estatística F: 20.6000 p-valor: 0.0463
A variável teoria apresentou a maior estatística F, com valor de 20,60, e p-valor de 0,0463. Como esse p-valor é menor que 0,05, essa foi a única variável com diferença estatisticamente significativa entre os clusters, considerando o nível de significância de 5%.
A variável projeto também apresentou uma estatística F elevada, com valor de 17,08, mas seu p-valor foi 0,0553, ligeiramente acima de 0,05. Portanto, neste exemplo, ela ficou próxima da significância estatística, mas não seria considerada significativa pelo critério tradicional de 5%.
A variável prática apresentou estatística F menor, igual a 7,43, e p-valor de 0,1186, indicando menor evidência de diferença entre os clusters em comparação com as demais variáveis.
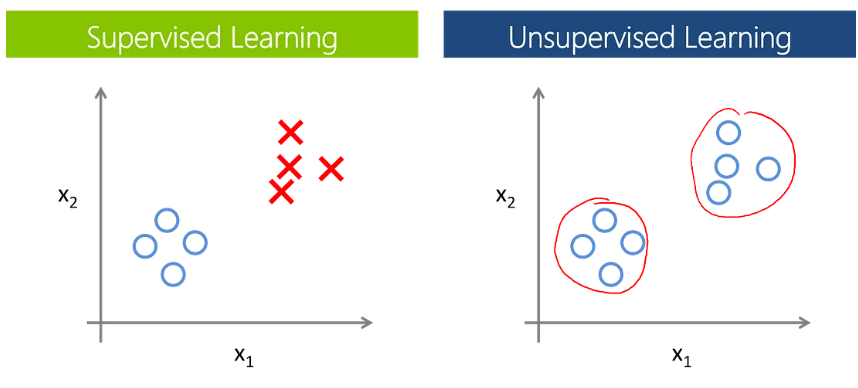
O aprendizado de máquina não supervisionado são algoritmos que pode encontrar padrões ocultos nos dados não rotulados. Ele basicamente agrupa pontos de dados que se assemelham, ou pode redizir a dimensionalidade dos dados, encontrar associações entre dados. Muito utilizado para redução de dimensionalidade, detectar anomalias, encontrar padrões, principalmente exploratória. Não existe variável resposta.
Em busca da mistura com menos custo, ou seja, minimizar o preço.
Notação matemática:
objetivo é achar as proporções dos ingredientes que respeitem os limites e chegue ao menor custo.
Modelo:
Exemplos de aplicações:
Exemplo 1)
Modelo: Alocação de Entregas com Capacidade
Contexto
Uma organização precisa distribuir entregas para centros regionais. Cada centro deve ser atendido por exatamente um veículo. Cada veículo tem um limite máximo de atendimentos.
O objetivo é minimizar a distância total percorrida.
from pulp import LpProblem, LpMinimize, LpVariable, lpSum, LpStatus, value, PULP_CBC_CMD