Em python no repositório:https://github.com/samantaleke/Unsupervised_PCA
Utiliza somente Variáveis Métricas (quantitativas), pois utiliza método/correlação de Person.
Objetivo é agrupamento em fatores.
Muito utilizado para diminuir a dimensão, a quantidade de variáveis, exemplo, de 200 variáveis métricas diminui para 102 variáveis métricas.
Exemplos de utilização:
- Criar um indicador/ranking que seja utilizado como critério de preço.
Um método exploratório sem fins preditivos.
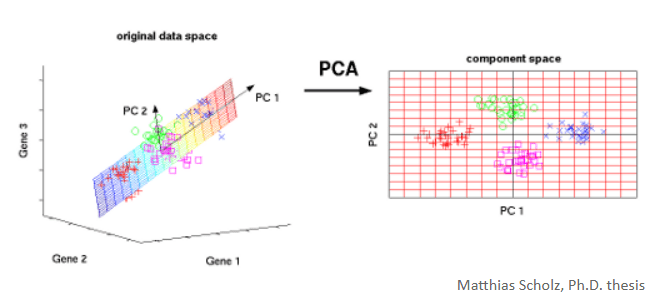
Análise de Construtos
- Identificação de Padrões: agrupando variáveis que medem o mesmo construto subjacente.
- Redução de quantidade de variáveis: Redução de quantidade de variáveis métricas.
- Eliminação de Redundância: Remove informações redundantes, mantendo a variabilidade principal dos dados de origem.
Funcionamento
Antes de iniciar
Análise preliminar, verifificar a correlação de Pearson (1) e esfericidade de Bartlett (2), antes de prosseguir com PCA.
- Correlação de Pearson.
PCA se basei nas correlações entre variáveis para criar os fatores, correlação de Pearson (relação linear entre 2 variáveis) e se são estatisticamente significantes.
O coeficiente de correlação de Pearson mede a intensidade e a direção da relação linear entre duas variáveis. Ele é calculado pela razão entre a covariância das variáveis e o produto dos seus respectivos desvios-padrão.
Em termos matemáticos:
De forma simplificada, podemos interpretar a fórmula como: Covariância de 2 variáveis, dividido pelo produto dos 2 desvios padrão.
ou seja:
A covariância, presente no numerador, indica se duas variáveis tendem a variar na mesma direção ou em direções opostas. Já os desvios-padrão, no denominador, padronizam essa relação, permitindo que o coeficiente fique limitado entre -1 e 1.
Assim:
Interpretação:
| Valor de (ρ) | Interpretação |
|---|---|
| Próximo de 1 | Forte correlação positiva |
| Próximo de -1 | Forte correlação negativa |
| Próximo de 0 | Baixa ou nenhuma relação linear |
No contexto do PCA, essa matriz é usada para entender como as variáveis se relacionam entre si. Quando há variáveis muito correlacionadas, o PCA consegue combinar essas informações em novos componentes principais, reduzindo a dimensionalidade dos dados sem perder muita informação.
2) Adequação Global da análise fatorial com método de Esfericidade de Bartlett
Após a construção da matriz de correlações de Pearson, foi aplicado o teste de esfericidade de Bartlett com o objetivo de avaliar a adequação global dos dados à análise fatorial/PCA.
No teste de esfericidade de Bartlett, a hipótese nula estabelece que a matriz de correlações de Pearson é igual à matriz identidade .
Isso significa que as correlações entre as variáveis fora da diagonal principal são nulas, indicando ausência de associação linear entre elas.
Já a hipótese alternativa afirma que a matriz de correlações é diferente da matriz identidade, ou seja, existe correlação entre pelo menos algumas variáveis, tornando a aplicação do PCA mais adequada.
No teste de esfericidade de Bartlett, as hipóteses são:
- Hipótese nula H0: A hipótese nula H0 afirma que a matriz de correlações de Pearson é igual à matriz identidade. Portanto, se não rejeitamos H0, entende-se que a matriz de correlações é próxima da identidade, indicando pouca ou nenhuma correlação entre as variáveis. Nesse caso, o PCA não é muito indicado.
- Hipótese alternativa H1: A hipótese alternativa H1 afirma que a matriz de correlações de Pearson é diferente da matriz identidade. Portanto, se rejeitamos H0, geralmente com p-valor < 0,05, conclui-se que a matriz de correlações difere significativamente da identidade, indicando que há correlação suficiente entre as variáveis para prosseguir com o PCA.
Ou seja, queremos testar se as variáveis são praticamente não correlacionadas entre si.
Se não rejeitamos H0H_0H0: a matriz de correlações é próxima da identidade → PCA não é muito indicado. Se rejeitamos H0H_0H0, com p-valor < 0,05: a matriz de correlações difere da identidade → há correlação suficiente para prosseguir com o PCA.
Se o resultado for a hipótese H1 (alternativa), ou seja, matriz de correlação de Person é diferente de uma matriz de identidade.
Iniciando PCA (extração dos fatores)
Autovalor
A dimensão da matriz sempre será quantidade de variáveis que tem, e a quantidade de autovalores tambem, ou seja, 4 observações = 4 dimensões de uma matriz e = 4 autovalores = 4 fatores.
A matriz de correlações de Pearson , com dimensão , possui autovalores , que são obtidos a partir da seguinte condição:
det(ρ−λI)=0
Essa expressão representa a equação característica da matriz. Ao resolver essa equação, encontramos suas raízes, que correspondem aos autovalores.
De forma expandida, temos a matriz:
No contexto do PCA, os autovalores indicam a quantidade de variância explicada por cada componente principal. Quanto maior o autovalor, maior é a parcela de informação dos dados originais representada por aquele componente.
Em outras palavras, os autovalores ajudam a identificar quais componentes concentram mais variabilidade e, portanto, quais são mais importantes para resumir a estrutura dos dados.
Exemplo:

Ou seja, percentual de variância dos dados originais, ou seja, a quantidade de informações está contida naquele Fator
Autovetor
Os autovetores indicam como as variáveis originais se combinam para formar cada componente principal. Cada autovetor está associado a um autovalor e representa uma direção de maior variação dos dados. No PCA, esses vetores mostram quais variáveis têm maior peso em cada componente, permitindo interpretar os padrões de correlação existentes entre elas.
Para cada autovalor eu tenho 1 autovetor. Ou seja, para cada autovalor encontrado, existe um autovetor correspondente que indica a direção do componente principal.
Após a obtenção dos autovalores da matriz de correlações de Pearson , calcula-se o respectivo autovetor associado a cada autovalor
Os autovetores são obtidos resolvendo o seguinte sistema:
Em forma matricial:
Ou seja, para cada autovalor encontrado, existe um autovetor correspondente que indica a direção do componente principal.
De forma expandida, o sistema pode ser representado como:
No contexto do PCA, os autovetores representam as combinações lineares das variáveis originais que formam os componentes principais.
Em outras palavras, eles indicam o peso de cada variável em cada componente. Assim, ajudam a entender quais variáveis contribuem mais para cada dimensão extraída pelo PCA.
Fatores
Para formar os fatores por combinação linear das variáveis originais, calculam-se os scores fatoriais. Em geral, pode-se obter até K scores, onde K corresponde ao número de variáveis do conjunto de dados. Esses scores são determinados com base nos autovalores e autovetores da matriz de correlações, representando os pesos utilizados na construção de cada fator.
Como, em resumo o valor do autovalor dividido pela raiz quadrada do respectivo autovetor.
De forma expandida:
Como neste exemplo foram utilizadas três variáveis — Atendimento, Preço e Qualidade — podem ser gerados até três scores fatoriais, um para cada componente principal.
Os scores fatoriais são obtidos pela divisão de cada elemento do autovetor pela raiz quadrada do respectivo autovalor.
| Variável | Score Fatorial 1 | Score Fatorial 2 | Score Fatorial 3 |
|---|---|---|---|
| Atendimento | 0,343 | 0,803 | 6,136 |
| Preço | -0,335 | 2,684 | 1,437 |
| Qualidade | 0,340 | 1,839 | -4,776 |
Esses valores foram obtidos a partir dos autovetores e autovalores do exemplo.
O Score Fatorial 1 é o mais importante para a interpretação inicial, pois está associado ao maior autovalor e, portanto, ao componente que explica a maior parte da variância dos dados.
Nesse primeiro fator, observamos que:
- Atendimento possui peso positivo;
- Qualidade possui peso positivo;
- Preço possui peso negativo.
Assim, o primeiro fator representa um contraste entre Atendimento/Qualidade e Preço. Em outras palavras, ele resume a principal estrutura dos dados: quanto maiores os valores associados a atendimento e qualidade, menor tende a ser o peso associado ao preço.
A ideia é:
Onde:
- Z representa a variável padronizada;
- s11,s21,s31 são os scores fatoriais do Fator 1.
| Variável | Score Fatorial 1 | Score Fatorial 2 | Score Fatorial 3 |
|---|---|---|---|
| Atendimento | 0,343 | 0,803 | 6,202 |
| Preço | -0,335 | 2,686 | 1,452 |
| Qualidade | 0,340 | 1,840 | -4,826 |
Fórmula do Fator 1
Como o primeiro fator é formado pela combinação linear das variáveis padronizadas, temos:
| Variável | Valor padronizado |
|---|---|
| Z_Atendimento | 0,935 |
| Z_Preço | -0,935 |
| Z_Qualidade | 1,154 |
Aplicando no Fator 1:
F1=0,343(0,935)−0,335(−0,935)+0,340(1,154)
Ou seja, a Observação 1 teria score aproximado de 1,026 no primeiro fator.
Após calcular os scores fatoriais, cada fator pode ser representado como uma combinação linear das variáveis padronizadas. No exemplo analisado, o primeiro fator foi formado pelos pesos de Atendimento, Preço e Qualidade. Como Atendimento e Qualidade possuem pesos positivos, enquanto Preço possui peso negativo, esse fator representa principalmente um contraste entre percepção de qualidade/atendimento e preço. Assim, cada observação passa a ter um novo valor no fator, calculado a partir da soma ponderada das variáveis padronizadas.
Carga Fatorial
Auxilia também na análise exploratória.
Correlação das observações com os fatores.
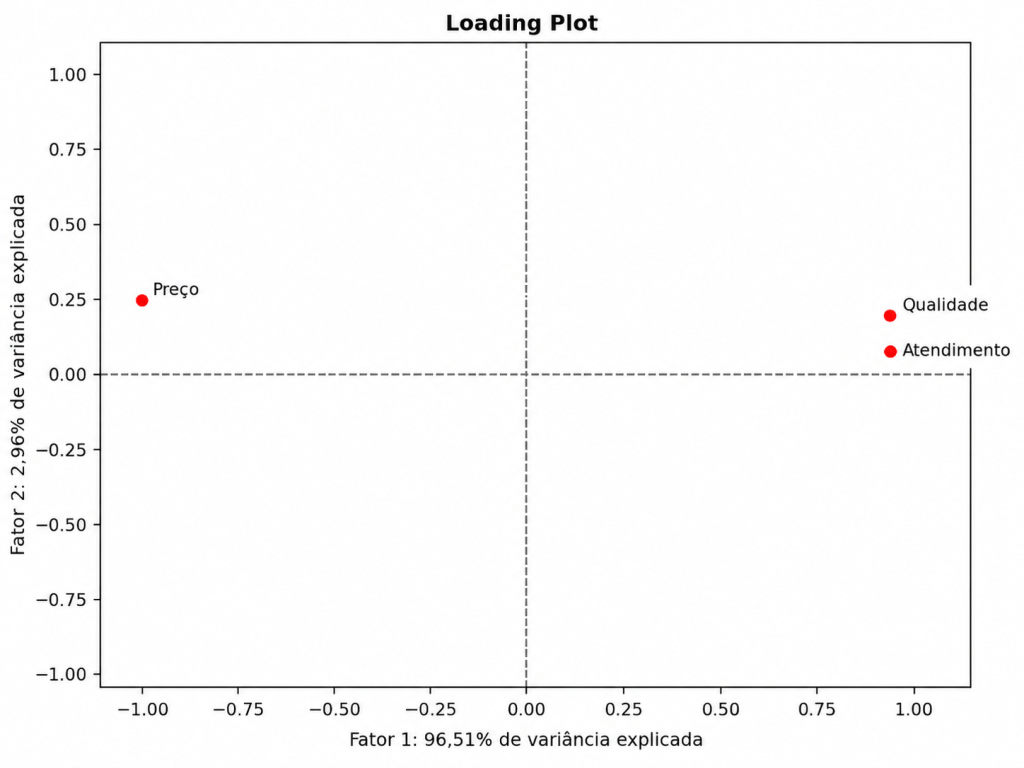
| Variável | Fator 1 | Fator 2 | Fator 3 | Comunalidades |
|---|---|---|---|---|
| Atendimento | 0,993 | 0,071 | 0,097 | 1,000 |
| Preço | -0,971 | 0,239 | 0,023 | 1,000 |
| Qualidade | 0,984 | 0,164 | -0,076 | 1,000 |
| Medida | Fator 1 | Fator 2 | Fator 3 |
|---|---|---|---|
| Autovalores | 2,895 | 0,089 | 0,016 |
| Variância explicada | 96,51% | 2,96% | 0,52% |
| Variância acumulada | 96,51% | 99,48% | 100,00% |
No Fator 1 concentra quase toda a informação dos dados, pois apresenta autovalor igual a 2,895 e explica aproximadamente 96,51% da variância total.
As maiores cargas fatoriais do Fator 1 aparecem em:
Atendimento=0,993
Preço=−0,971
Qualidade=0,984
Isso indica que o primeiro fator está fortemente associado a Atendimento e Qualidade, mas em sentido contrário ao Preço.
Como o Fator 2 e o Fator 3 possuem autovalores menores que 1, eles explicam pouca variância individualmente. Pelo critério de Kaiser, manteríamos apenas o Fator 1, pois:
Portanto, as cargas fatoriais indicaram que o primeiro fator possui forte associação positiva com Atendimento e Qualidade, enquanto a variável Preço apresentou associação negativa. Isso sugere que o Fator 1 resume uma dimensão relacionada à percepção de qualidade e atendimento em oposição ao preço. Como esse fator apresentou autovalor igual a 2,895 e explicou 96,51% da variância total, ele concentrou a maior parte da informação dos dados. Pelo critério de Kaiser, apenas esse fator seria mantido, pois foi o único com autovalor superior a 1.
Comunalidade
Quando você trabalha com todos os fatores possíveis, ou seja, quantidade de variáveis, não tenho nenhum tipo de perda de informação das variáveis originais.
Então nós dissemos que as comunalidade seriam a perda da variância se acaso retirar Fatores, quanto de informação perderiamos.
Ou seja,
| Fator | Autovalor | Variância explicada |
|---|---|---|
| Fator 1 | 2,895 | 96,51% |
| Fator 2 | 0,089 | 2,96% |
| Fator 3 | 0,016 | 0,52% |
Se manter apenas o Fator 1, a variância total explicada pelo modelo fica:
96,51%
E a parte que fica fora do modelo é:
100%−96,51%=3,49%
Ou seja, deixaria de explicar aproximadamente:
2,96%+0,52%=3,48%
Essa diferença é pequena, por isso manter só o Fator 1 faz sentido nesse exemplo.
Calcular o Fator e Score fatorial em cada observação
- Scores fatoriais / coeficientes do fator: são os pesos usados na fórmula.
- Valor do fator em cada linha: é o resultado da fórmula aplicada em cada observação.
No exemplo, mantendo apenas o Fator 1, a fórmula fica:
F1=0,343⋅ZAtendimento−0,335⋅ZPreco+0,340⋅ZQualidade
Ou seja, para cada linha da base, primeiro padronizamos as variáveis e depois aplicamos os pesos do fator.
1. Padronização das variáveis
Antes de calcular o fator, cada variável precisa ser transformada em valor padronizado Z:
Onde:
| Variável | Média | Desvio-padrão |
|---|---|---|
| Atendimento | 6,500 | 1,604 |
| Preço | 6,500 | 1,604 |
| Qualidade | 7,375 | 1,408 |
2. Fórmula do Fator 1
Após a padronização, aplicamos os pesos do Fator 1:
3. Exemplo calculado em uma linha
Para a Observação 1, os valores originais eram:
| Observação | Atendimento | Preço | Qualidade |
|---|---|---|---|
| 1 | 8 | 5 | 9 |
Os valores padronizados ficam aproximadamente:
| Variável | Valor padronizado |
|---|---|
| Z_Atendimento | 0,935 |
| Z_Preço | -0,935 |
| Z_Qualidade | 1,154 |
Aplicando na fórmula:
Portanto, a Observação 1 tem valor aproximado de 1,027 no Fator 1.
Resultado para todas as observações:
| Observação | Z_Atendimento | Z_Preço | Z_Qualidade | Fator 1 |
|---|---|---|---|---|
| 1 | 0,935 | -0,935 | 1,154 | 1,027 |
| 2 | 0,312 | 0,312 | 0,444 | 0,153 |
| 3 | 1,559 | -1,559 | 1,154 | 1,449 |
| 4 | -0,312 | -0,312 | -0,266 | -0,093 |
| 5 | 0,312 | -0,312 | 0,444 | 0,362 |
| 6 | -0,935 | 0,935 | -0,977 | -0,966 |
| 7 | -1,559 | 1,559 | -1,687 | -1,631 |
| 8 | -0,312 | 0,312 | -0,266 | -0,302 |
O valor do fator em cada linha representa uma nova pontuação criada a partir das variáveis originais padronizadas.
Essa pontuação resume o comportamento conjunto das variáveis em um único indicador.
No exemplo, o Fator 1 resume principalmente a relação positiva entre Atendimento e Qualidade e a relação oposta com Preço.
Seleção de fatores
Depois de calcular autovalores, cargas fatoriais, comunalidades e fatores, o próximo passo é decidir quantos fatores manter na análise.
Nem sempre usamos todos os fatores. A decisão pode ser feita observando a magnitude dos autovalores.
No nosso exemplo, os autovalores foram aproximadamente:
| Fator | Autovalor | Variância explicada |
|---|---|---|
| Fator 1 | 2,895 | 96,51% |
| Fator 2 | 0,089 | 2,96% |
| Fator 3 | 0,016 | 0,52% |
Pelo critério de Kaiser, mantemos apenas os fatores com autovalor maior que 1:
No exemplo acima:
Portanto, apenas o Fator 1 seria mantido.
O Fator 1 sozinho explica aproximadamente:
da variância total dos dados.
Isso significa que ele já resume quase toda a informação presente nas três variáveis originais. Os Fatores 2 e 3 explicam parcelas muito pequenas da variância e, por isso, não teriam tanta representatividade nesse exemplo.
Comunalidade após escolher alguns fatores
No exemplo acima, ao manter apenas o Fator 1, as comunalidades deixam de ser iguais a 1,000, pois os demais fatores foram retirados da análise.
Nesse caso, a comunalidade de cada variável representa a parcela da sua variância explicada somente pelo primeiro fator.
No exemplo analisado, o Fator 1 explicou 98,6% da variância de Atendimento, 94,3% da variância de Preço e 96,8% da variância de Qualidade, indicando que um único fator já representa muito bem as três variáveis originais.
Agora se escolher 2 fatores, ou seja, Fator 1 e Fator 2, a comunalidade de cada variável será a soma dos quadrados das cargas fatoriais desses dois fatores.
A fórmula fica:
Ou seja:
as cargas fatoriais eram aproximadamente:
| Variável | Fator 1 | Fator 2 |
|---|---|---|
| Atendimento | 0,993 | 0,071 |
| Preço | -0,971 | 0,239 |
| Qualidade | 0,984 | 0,164 |
Então, as comunalidades com 2 fatores ficam:
| Variável | Cálculo | Comunalidade |
|---|---|---|
| Atendimento | 0,9932+0,0712 | 0,991 |
| Preço | (−0,971)2+0,2392 | 1,000 |
| Qualidade | 0,9842+0,1642 | 0,995 |
Em percentual:
| Variável | Comunalidade com 2 fatores |
|---|---|
| Atendimento | 99,1% |
| Preço | 100,0% |
| Qualidade | 99,5% |
Comparando:
| Variável | Comunalidade com 1 fator | Comunalidade com 2 fatores |
|---|---|---|
| Atendimento | 0,986 | 0,991 |
| Preço | 0,943 | 1,000 |
| Qualidade | 0,968 | 0,995 |
Criação de ranking
Ponderação dos fatores e respectivas variâncias explicadas.
Dar maior peso aos fatores que explicam maior quantidade de variância dos dados.
A lógica é:
Cada observação recebe um valor em cada fator. Depois, esses fatores são combinados em uma única pontuação final, usando como peso a variância explicada por cada fator.
Ou seja, fatores que explicam mais variância recebem maior peso no ranking.
Fórmula geral
Se forem mantidos dois fatores, por exemplo:
Onde:
é o valor da observação no Fator 1, e:
é o valor da observação no Fator 2.
Já:
e:
são as variâncias explicadas por cada fator.
No exemplo
Como o Fator 1 explica:
e o Fator 2 explica:
a fórmula do ranking com dois fatores seria:
