Uma variável pode ser estatisticamente significativa quando analisada isoladamente, mas perder significância quando inserida em um modelo com outras variáveis altamente correlacionadas.
Em regressões múltiplas, a significância estatística de uma variável depende não apenas de sua relação com a variável resposta, mas também da informação compartilhada com as demais variáveis explicativas. Quando existe forte multicolinearidade, o modelo encontra dificuldades para separar os efeitos individuais dos preditores, aumentando os erros-padrão dos coeficientes e reduzindo sua significância estatística.
Quanto da variabilidade de Y foi explicada pelo modelo?
❷ Teste F
Pergunta:
O modelo como um todo possui capacidade explicativa?
Hipóteses:
Nesse exemplo:
Prob(F-statistic) = 0.000001
Logo:
✅ Rejeita H₀
✅ Pelo menos um β é significativo
α (Intercepto)
Linha:
Intercept
Coeficiente:
10.52
Interpretação:
Quando:
esperamos:
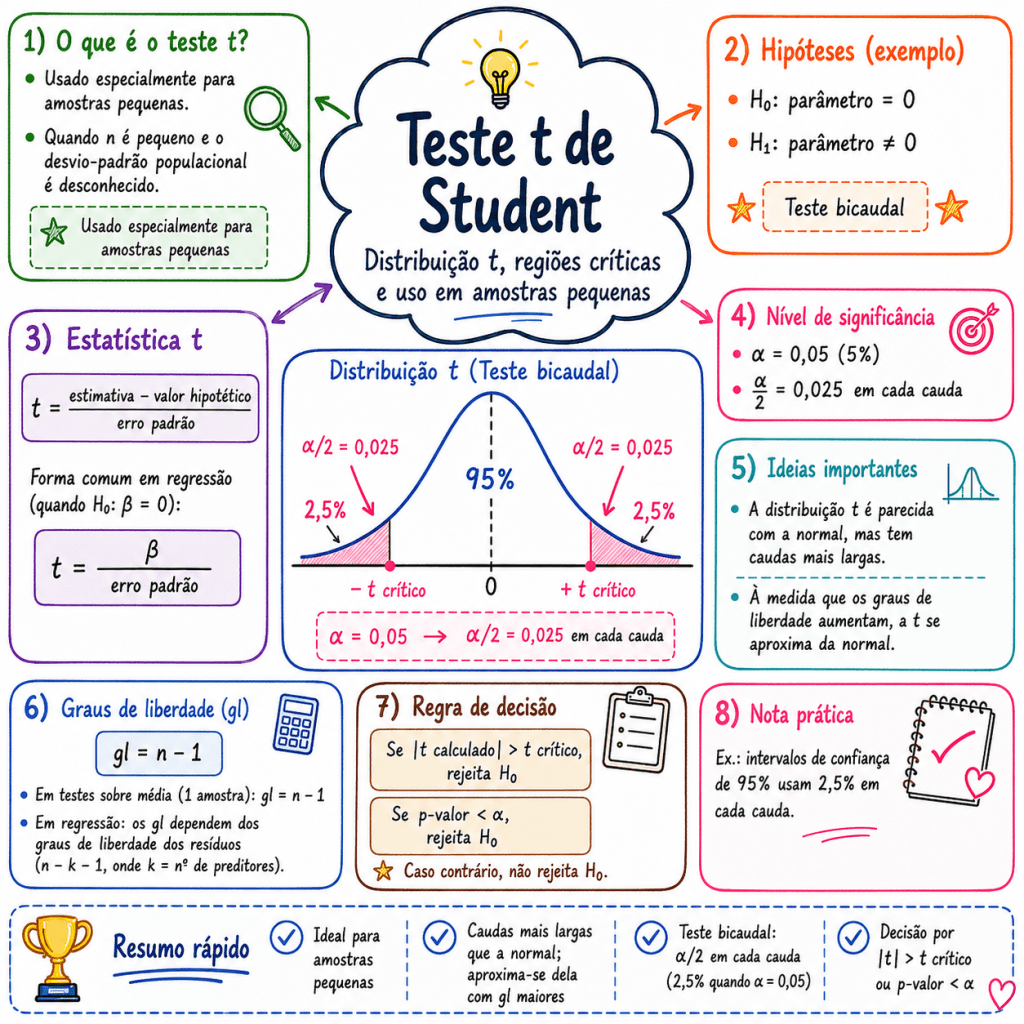
Teste t
Cada linha de variável possui um teste t próprio.
Exemplo:
X1coef = 2.31t = 5.50p-value = 0.000
Hipóteses:
Como:
p-value < 0,05
✅ X1 é significativa.
Resumo visual
SUMMARY
│
├── R²
│ Quanto Y foi explicado?
│
├── Teste F
│ Modelo funciona?
│
├── α (Intercept)
│ Valor esperado de Y quando X=0
│
├── β
│ Efeito de cada variável
│
├── Teste t
│ β é significativo?
│
├── p-value
│ Evidência estatística
│
└── IC95%
Faixa plausível para o coeficiente
Teste F → avalia o modelo inteiro
Teste t → avalia cada β individualmente
α → é apenas mais um coeficiente, mas representa o intercepto da reta/plano de regressão.
Multicolinearidade
Um dos sintomas clássicos da multicolinearidade ocorre quando o teste F indica que o modelo é globalmente significativo, mas os testes t individuais não identificam coeficientes significativos. Nessa situação, as variáveis explicativas possuem forte correlação entre si, dificultando a separação de seus efeitos individuais sobre a variável resposta. Como consequência, os erros-padrão aumentam, as estatísticas t diminuem e os p-values tornam-se elevados, mesmo quando o conjunto de variáveis explica adequadamente Y.
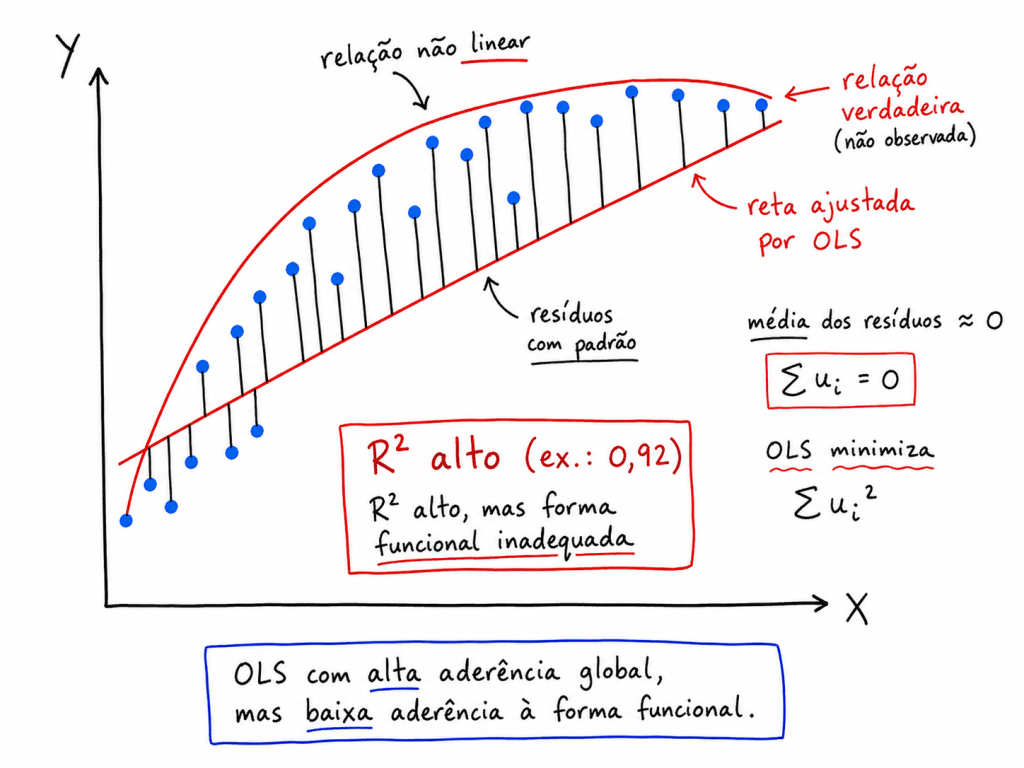
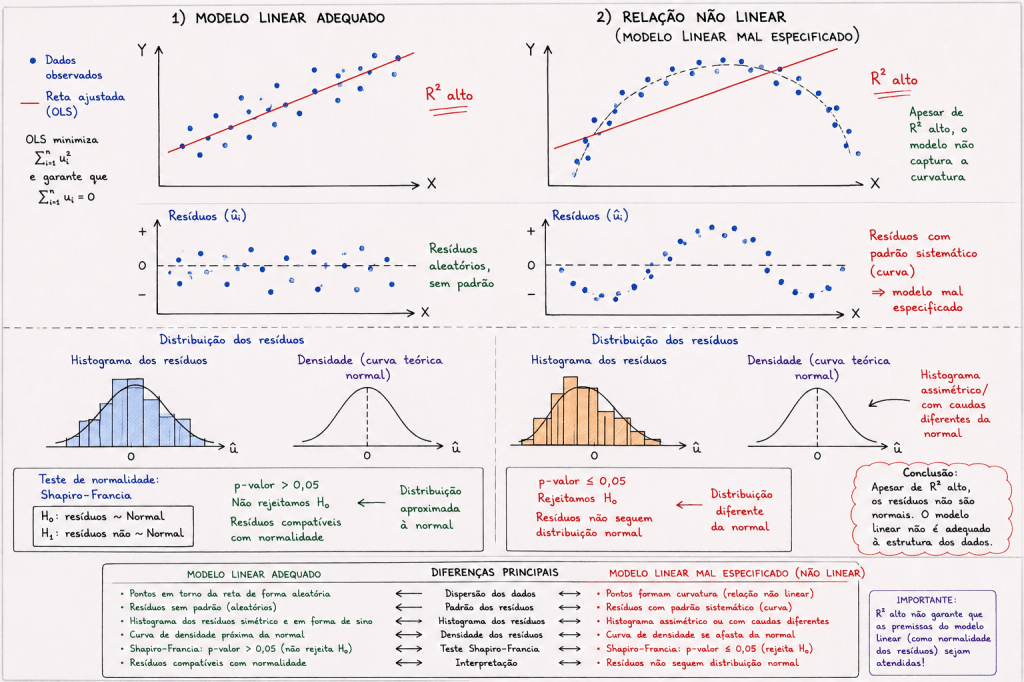
Resíduos não aderentes a normalidade, por determinado teste estatístico, provavelmente a distribuição de dados é não linear.
Exemplo de Teste estatístico para verificar se os resíduos estão aderentes a normalidade.
Shapiro-Wilk: Amostras pequenas (50 observações)
Shapiro-Francia: Amostras maiores.
O teste de Shapiro–Francia é um teste estatístico utilizado justamente para verificar essa hipótese de normalidade.
Hipóteses do teste
O teste trabalha com duas hipóteses:
Ou seja:
representa a hipótese de normalidade;
representa a hipótese alternativa, indicando violação da normalidade.
Interpretação do p-valor
Após executar o teste, obtém-se um valor chamado p-value.
A regra geral é:
Se:
não rejeitamos .
Assim, há evidências de que os resíduos possuem aderência à normalidade.
Se:
rejeitamos .
Nesse caso, conclui-se que os resíduos não seguem distribuição normal.
Normalização/Transformação box-cox (transformação da variável dependente)
O Box-Cox não transforma os resíduos diretamente. Primeiro transformamos , ajustamos o modelo com , e só depois avaliamos se os novos resíduos ficaram mais aderentes à normalidade.
Qual melhor Lambda que maximiza a aderência a normalidade.
Na transformação Box-Cox, quando ainda não existe um modelo ajustado, não avaliamos os termos de erro, pois os resíduos só existem após a estimação do modelo. Nesse caso, a transformação é aplicada diretamente sobre a variável resposta Y, com o objetivo de aproximar sua distribuição da normalidade e estabilizar sua variância.
O parâmetro da transformação Box-Cox é escolhido de forma a tornar a variável resposta transformada o mais próxima possível de uma distribuição normal. Assim, antes de ajustar o modelo, buscamos uma escala mais adequada para , aumentando a chance de que os resíduos do modelo apresentem melhor comportamento estatístico.
A transformação é:
quando:
E quando:
usa-se:
A ideia é testar vários valores de λ, por exemplo:
e escolher aquele que maximiza a aderência de à distribuição normal.
É usada quando a variável resposta é contínua e aproximadamente simétrica.
Erros comuns, importante:
Intercepto não significativo não invalida o modelo. Não remover o intercept/alfa do modelo. Ele apenas indica que, com a amostra disponível, não há evidência suficiente de que o intercepto seja diferente de zero. Forçar sem justificativa pode gerar viés e piorar a interpretação do modelo.
R2 ajustado é para comparar modelos.
Cuidado com ponderação arbitrária, exemplo transformar variável qualitativa em LabelEncoder int(64), o correto é dummizar, deixar como string.
Alguns exemplos utilizados corretamente.
Prever o valor de um imóvel com base em área, localização e número de quartos.
Nesse caso, a resposta pode assumir vários valores numéricos contínuos.
Funcionamento:
Em modelos OLS a somatória dos termos de erro é igual a zero.
Modelo GLM
Distribuição
Tipo da variável dependente
Quando usar
Forma aproximada da distribuição
Regressão Linear
Normal
Quantitativa contínua
Quando a resposta é contínua e aproximadamente simétrica
🔔 Curva em sino
Olhamos o nível de significância do Beta.
A regressão linear simples busca modelar a relação entre uma variável dependente e uma variável independente .
A equação geral é:
Yi=β0+β1Xi+εi
Onde:
Termo
Significado
(Y_i)
Valor observado da variável dependente para a observação (i)
(X_i)
Valor da variável independente para a observação (i)
(\beta_0)
Intercepto da reta, ou seja, valor esperado de (Y) quando (X = 0)
(\beta_1)
Inclinação da reta, ou seja, quanto (Y) varia quando (X) aumenta 1 unidade
(\varepsilon_i)
Termo de erro, isto é, a diferença entre o valor observado e o valor estimado
Uma forma mais didática também é escrever:
Nesse caso:
representa o intercepto da reta, ou seja, α é o ponto onde a reta corta o eixo ;
representa a inclinação da reta;
representa o erro da observação iii.
Então, a nomenclatura:
Valor estimado pelo modelo
O modelo não prevê exatamente . Ele calcula um valor estimado, chamado de :
Onde:
é o valor previsto pelo modelo.
Termo de erro
O erro é a diferença entre o valor real observado e o valor previsto pelo modelo:
Substituindo:
Esse erro mostra o quanto o modelo errou para cada observação.
Ideia do algoritmo
O algoritmo da regressão linear procura encontrar a melhor reta possível para os dados.
Essa melhor reta é aquela que minimiza a soma dos erros ao quadrado:
Como:
temos:
Esse método é chamado de Mínimos Quadrados Ordinários — Ordinary Least Squares[OLS].
Fórmula da inclinação da reta
A inclinação pode ser calculada por:
Ela mede o quanto tende a mudar quando aumenta uma unidade.
Fórmula do intercepto
Depois de calcular , calculamos o intercepto :
Onde:
é a média dos valores de ;
é a média dos valores de .
Interpretação prática
Imagine o modelo:
Nesse caso:
A interpretação é:
Quando , o valor esperado de é 10.
E:
Quando aumenta 1 unidade, espera-se que aumente 2 unidades.
Exemplo:
Se o valor real observado fosse:
então o erro seria:
Ou seja, o modelo subestimou o valor real em 3 unidades.
A Regressão Linear busca encontrar uma reta que melhor representa a relação entre e . Essa reta é definida por um intercepto e uma inclinação. O intercepto indica o valor esperado de quando , enquanto a inclinação indica quanto muda quando aumenta uma unidade. O termo de erro representa a diferença entre o valor observado e o valor previsto pelo modelo. O algoritmo estima os coeficientes minimizando a soma dos erros ao quadrado.
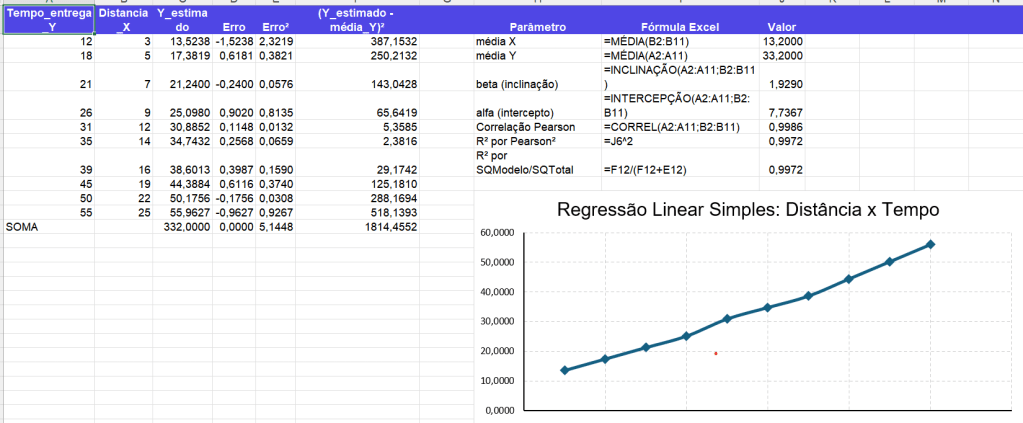
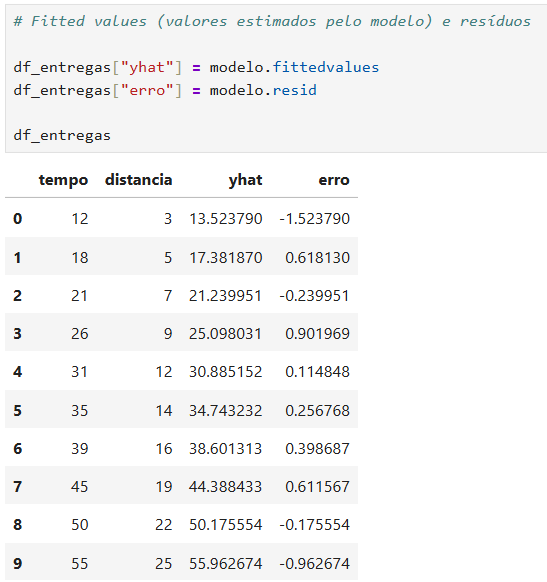
Exemplo:
Y: tempo de entrega;
X: distância;
cálculo de , , erro, erro², , , correlação de Pearson e ;
Tempo entrega Y
Distância X
Y estimado
Erro
Erro²
(Y^−Yˉ)2
12
3
13,5238
-1,5238
2,3219
387,1532
18
5
17,3819
0,6181
0,3821
250,2132
21
7
21,2400
-0,2400
0,0576
143,0428
26
9
25,0980
0,9020
0,8135
65,6419
31
12
30,8852
0,1148
0,0132
5,3585
35
14
34,7432
0,2568
0,0659
2,3816
39
16
38,6013
0,3987
0,1590
29,1742
45
19
44,3884
0,6116
0,3740
125,1810
50
22
50,1756
-0,1756
0,0308
288,1694
55
25
55,9627
-0,9627
0,9267
518,1393
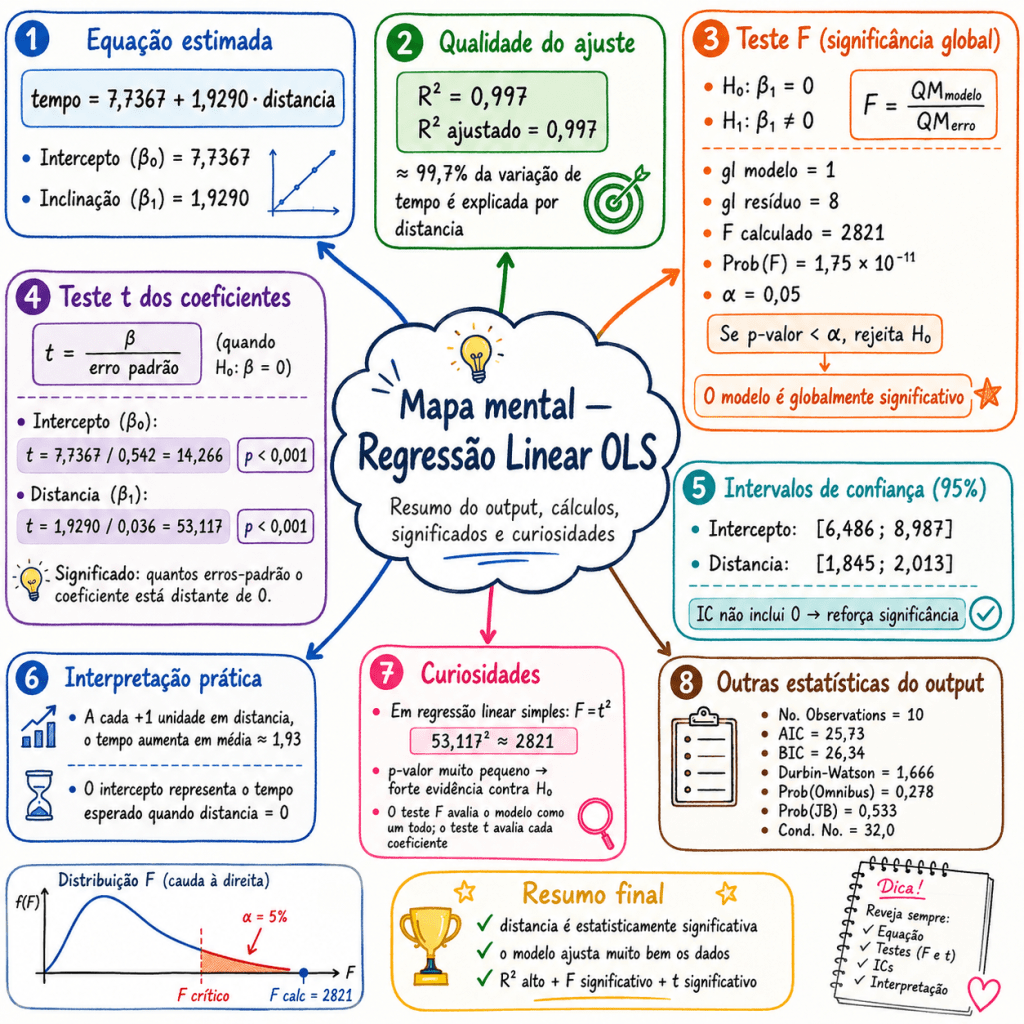
Modelo encontrado
A reta estimada ficou:
Y^=7,7367+1,9290X
Ou seja:
α=7,7367
A interpretação é:
A cada aumento de 1 unidade na distância, o tempo de entrega aumenta, em média, aproximadamente 1,9290 unidades.
Tabelas de parâmetros:
Parâmetro
Fórmula Excel
Valor
média X
=MÉDIA(B2:B11)
13,2000
média Y
=MÉDIA(A2:A11)
33,2000
beta
=INCLINAÇÃO(A2:A11;B2:B11)
1,9290
alfa
=INTERCEPÇÃO(A2:A11;B2:B11)
7,7367
Correlação Pearson
=CORREL(A2:A11;B2:B11)
0,9986
R² por Pearson²
=J6^2
0,9972
R² por soma dos quadrados
=F12/(F12+E12)
0,9972
A regressão linear simples encontra a melhor reta para explicar a relação entre e . O cálculo pode ser visto como um problema de otimização, pois o objetivo é minimizar a soma dos erros ao quadrado:
α,βmini=1∑n(Yi−Y^i)2
Como:
Y^i=α+βXi
então:
α,βmini=1∑n(Yi−α−βXi)2
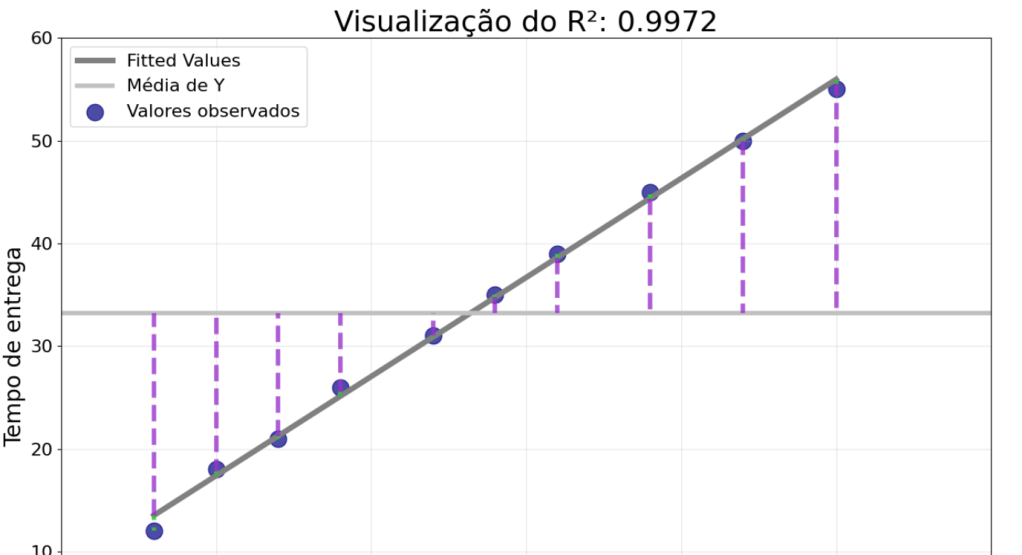
Nesse exemplo, o modelo apresentou:
R2=0,9972
Isso significa que aproximadamente 99,72% da variação do tempo de entrega foi explicada pela distância.
E como é uma regressão linear simples, com apenas uma variável , vale a curiosidade:
R2=r2
onde é a correlação de Pearson entre e .
Python
Utilizando o modelo OLS (Ordinary Least Squares, ou Mínimos Quadrados Ordinários), já tenho como premissa que a variável Y ou dependente é quantitativa, que a somatório dos erro é igual 0 e a somatória dos erros ao quadrado será a mínima possível.
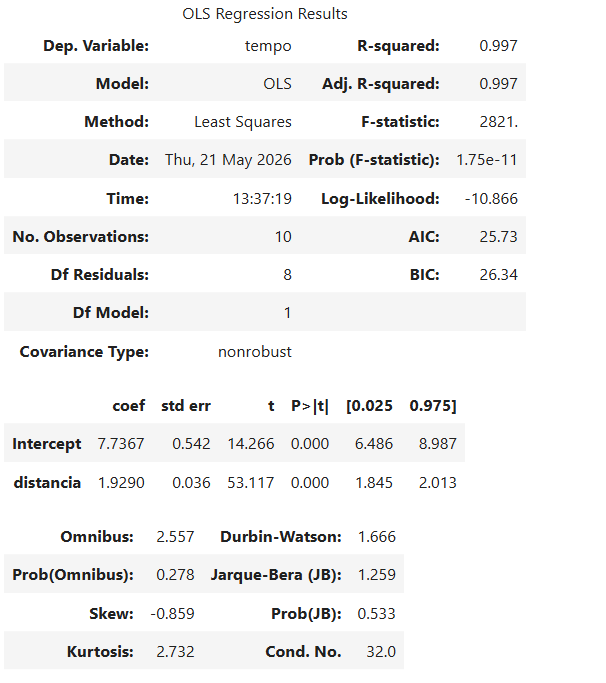
Correspondência entre a saída do Python e a equação da regressão
A regressão linear simples estimada pelo Python aparece no formato:
No nosso exemplo:
Ou seja:
Saída no Python
Nome estatístico
Nome didático
Valor no nosso exemplo
Interpretação
R-squared
(R^2)
R-quadrado
0,997
Percentual da variação de (Y) explicado por (X)
Intercept
(\alpha) ou (\beta_0)
Intercepto / Alfa
7,7367
Valor estimado de tempo quando a distância é zero
distancia
(\beta) ou (\beta_1)
Beta / Inclinação
1,9290
Quanto o tempo aumenta quando a distância cresce 1 unidade
Equação do modelo
A partir da tabela de coeficientes:
Variável
Coeficiente
Intercept
7,7367
distancia
1,9290
A equação fica:
Onde:
Portanto:
Interpretação do intercepto
O intercepto é o valor esperado de Y quando X=0.
Neste exemplo:
Isso significa que, quando a distância é igual a zero, o tempo estimado pelo modelo seria aproximadamente:
Na prática, nem sempre o intercepto tem uma interpretação realista. Ele é principalmente necessário para posicionar a reta no gráfico.
Interpretação do beta
O coeficiente da variável distancia é:
Isso significa que, para cada aumento de 1 unidade na distância, o tempo de entrega aumenta, em média, aproximadamente:
unidades de tempo.
Em linguagem simples:
Quanto maior a distância, maior tende a ser o tempo de entrega.
Interpretação do R-quadrado
O R-squared aparece como:
Isso significa que aproximadamente:
da variação do tempo de entrega é explicada pela distância no modelo linear simples.
Ou seja, nesse exemplo fictício, a distância explica quase totalmente a variação do tempo.
Coluna
Significado
Fórmula
tempo
Valor real observado de (Y)
(Y_i)
distancia
Variável explicativa (X)
(X_i)
yhat
Valor estimado pelo modelo
(\hat{Y}_i)
erro
Resíduo do modelo
(Y_i – \hat{Y}_i)
A coluna yhat representa os fitted values, ou seja, os valores previstos pela reta de regressão.
Como o modelo estimado foi:
para cada linha, o Python calcula:
Já a coluna erro representa o resíduo:
Ou seja, é a diferença entre o tempo real observado e o tempo estimado pelo modelo.
Exemplo prático
Para a primeira linha, supondo:
o valor estimado é:
Então o erro é:
Como o erro ficou negativo, significa que o modelo estimou um valor maior do que o valor observado.
Resumo e entendimento para o exemplo:
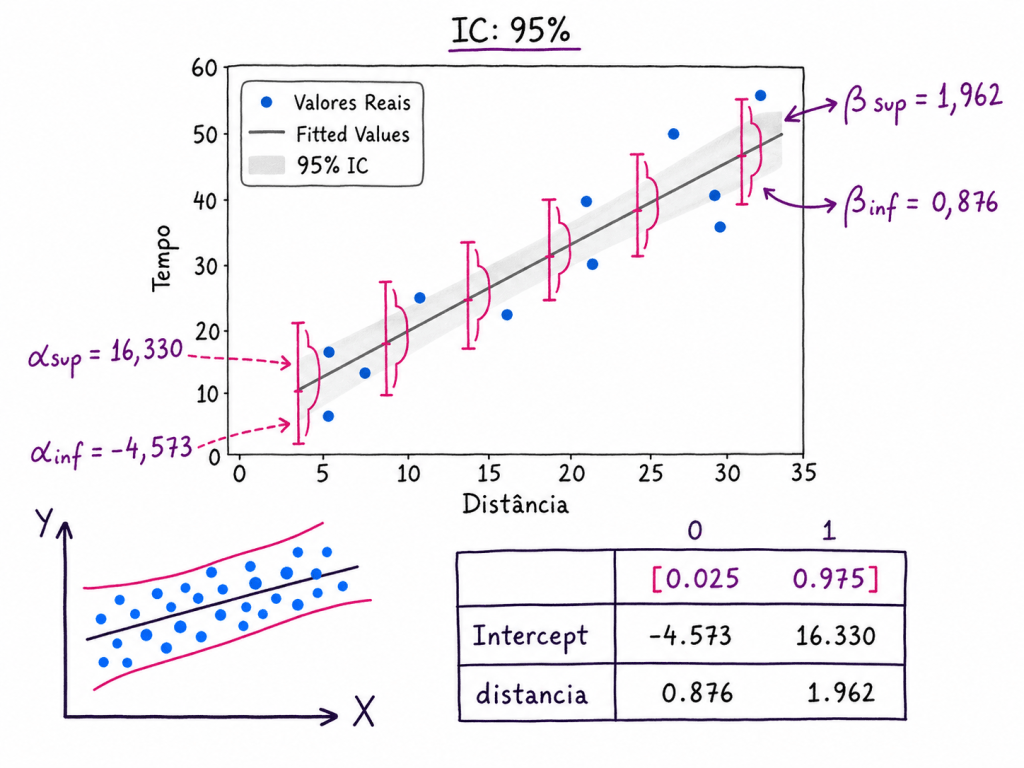
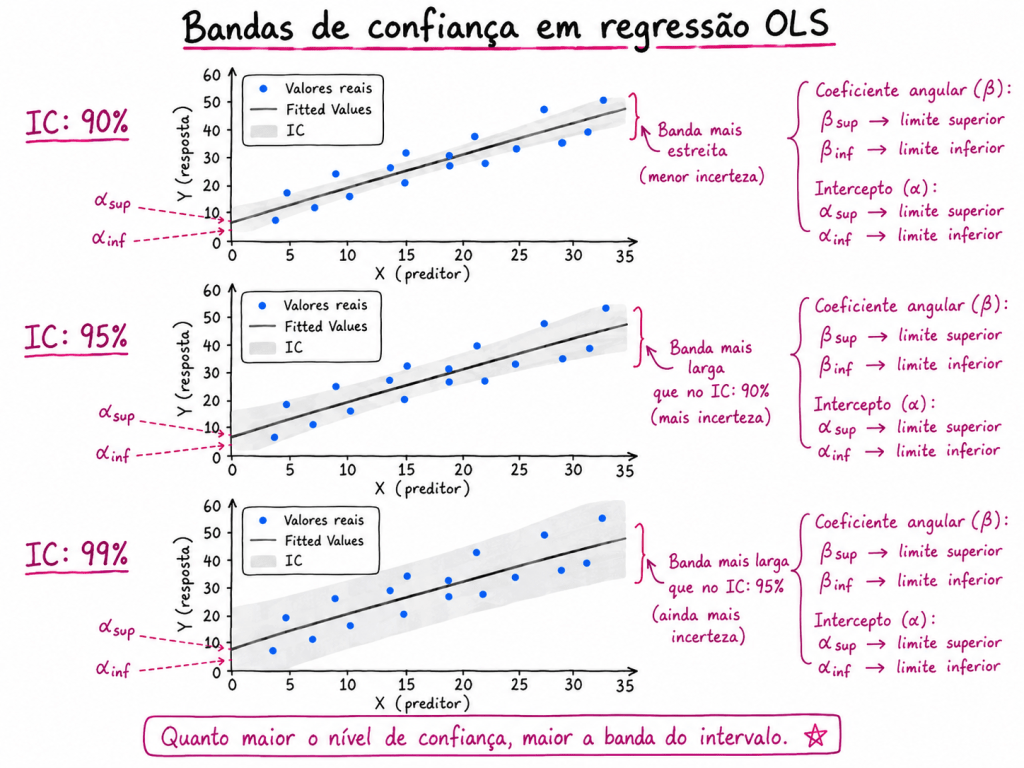
Pontos importantes sobre significância, intervalos de confiança e intercepto na Regressão OLS
Ao interpretar um modelo de regressão linear estimado por OLS, é comum olhar para os coeficientes, os p-valores e os intervalos de confiança. Porém, alguns cuidados são importantes para evitar interpretações erradas.
Resumo dos pontos principais
Ponto
Interpretação
Intervalos de confiança aumentam quando elevamos o nível de confiança
Um IC de 99% tende a ser mais largo que um IC de 95%
A significância depende do nível de significância adotado
Um coeficiente pode ser significativo a 5%, mas não a 1%
Em modelos preditivos, p-valor não é tudo
Métricas de erro e validação também são essenciais
Amostras pequenas aumentam a incerteza
O erro padrão pode crescer e reduzir a significância dos coeficientes
Intercepto não significativo não deve ser removido automaticamente
Forçar a reta pela origem pode gerar viés
1. Quanto maior o nível de confiança, maior será o intervalo do coeficiente
O intervalo de confiança de um coeficiente representa uma faixa provável de valores para o verdadeiro parâmetro populacional.
De forma simplificada:
Onde:
é o coeficiente estimado pelo modelo;
é o erro padrão do coeficiente;
é o valor crítico da distribuição t.
Quando aumentamos o nível de confiança, por exemplo de 95% para 99%, o modelo precisa construir uma faixa mais ampla para aumentar a chance de conter o verdadeiro valor do parâmetro.
2. Um coeficiente pode ser significativo em um nível e deixar de ser em outro
A significância estatística depende diretamente do nível de significância adotado, geralmente representado por α.
Por exemplo:
Isso significa que, ao aumentar o nível de confiança, o teste fica mais rigoroso.
Imagine um coeficiente com:
Se adotarmos α=0,05, esse coeficiente será considerado estatisticamente significativo, pois:
Mas, se adotarmos α=0,01, ele deixará de ser significativo, pois:
Resumo:
Situação
p-valor
Nível de significância
Interpretação
Confiança de 95%
0,03
5%
Significativo
Confiança de 99%
0,03
1%
Não significativo
Então, um mesmo coeficiente pode ser significativo a 95%, mas não significativo a 99%.
Esse ponto é importante porque mostra que a significância estatística não é uma característica absoluta do coeficiente. Ela depende do critério adotado na análise.
3. Em modelos preditivos, significância estatística não deve ser analisada isoladamente
Em problemas de predição, o objetivo principal não é apenas saber se um coeficiente é estatisticamente diferente de zero, mas avaliar se o modelo consegue prever bem novos dados.
Por isso, além dos p-valores, é importante observar métricas como:
erro médio absoluto, MAE;
raiz do erro quadrático médio, RMSE;
;
análise dos resíduos;
desempenho em dados de teste;
validação cruzada, quando aplicável.
Um coeficiente individual pode não ser estatisticamente significativo e, ainda assim, o modelo pode apresentar bom desempenho preditivo.
Por outro lado, um modelo pode ter coeficientes estatisticamente significativos e ainda assim não ser bom para previsão, principalmente se não generalizar bem para novos dados.
Portanto, para fins preditivos, significância estatística é útil, mas não deve ser o único critério de decisão.
4. Amostras pequenas podem dificultar a significância dos parâmetros
O tamanho da amostra tem grande impacto na inferência estatística.
A estatística t de um coeficiente é calculada por:
No caso do intercepto, também chamado de , temos:
Quando a amostra é pequena, o erro padrão tende a ser maior. Isso reduz o valor da estatística t e pode aumentar o p-valor.
A lógica é:
Ou seja, com poucas observações, o modelo pode não ter evidência estatística suficiente para indicar que determinado parâmetro é diferente de zero.
5. Intercepto não significativo não significa que ele deve ser removido automaticamente
Um erro comum em modelos regressivos é remover o intercepto apenas porque ele não apresentou significância estatística.
Isso pode ser perigoso.
O intercepto representa o valor esperado de quando as variáveis explicativas são iguais a zero. Dependendo do problema, esse ponto pode nem ter interpretação prática, mas ainda assim o intercepto ajuda a ajustar corretamente a reta de regressão.
Remover o intercepto força a reta a passar pela origem:
Em vez de permitir:
Essa imposição pode gerar viés no modelo, principalmente quando não existe justificativa teórica para assumir que quando .
Portanto, intercepto não significativo deve ser analisado com cuidado, e não removido automaticamente.
Em regressão OLS, a interpretação dos coeficientes não deve se limitar ao p-valor. O nível de confiança, o tamanho da amostra, o erro padrão e o objetivo do modelo — explicação ou predição — influenciam diretamente a análise. Além disso, a ausência de significância estatística do intercepto não é, por si só, justificativa para removê-lo do modelo.
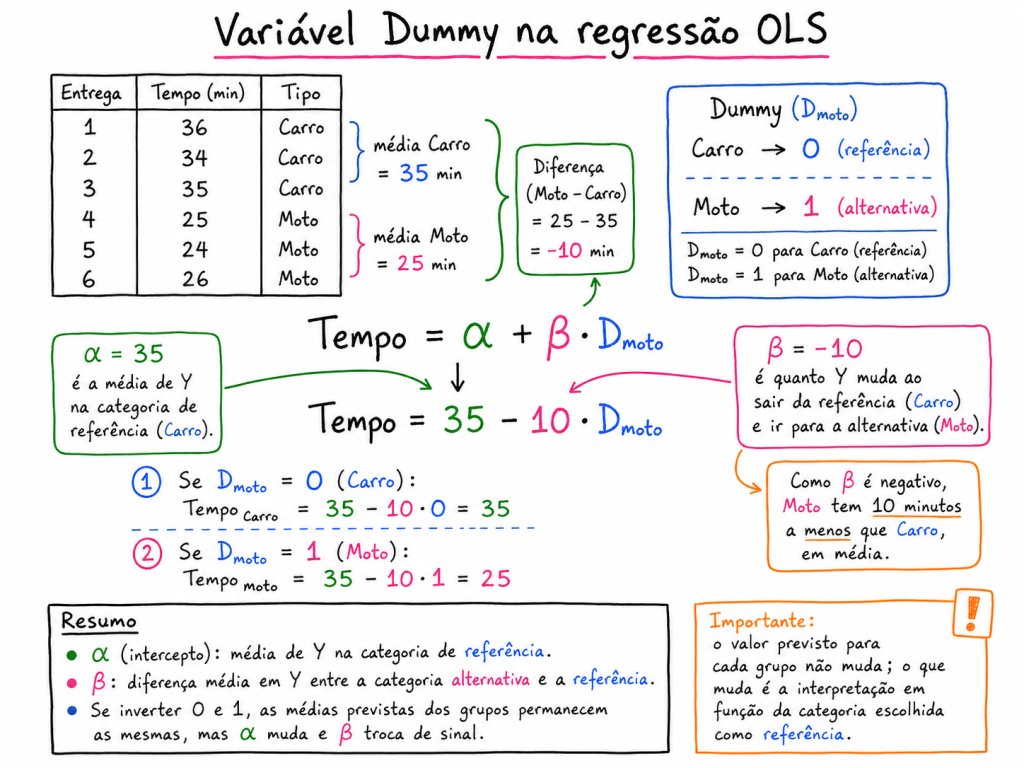
Pontos Importantes sobre variáveis categóricas Dummy
Em modelos regressivos, uma variável dummy indica o efeito médio de pertencer a uma determinada categoria em comparação com uma categoria de referência. Quando a dummy assume valor 0, a observação pertence ao grupo base. Quando assume valor 1, pertence ao grupo alternativo. Assim, o coeficiente da dummy representa o incremento ou redução média esperada em Y ao mudar da categoria de referência para a categoria alternativa, mantendo as demais variáveis constantes.
Uma variável dummy representa uma mudança média em quando saímos da categoria de referência e vamos para a categoria alternativa, mantendo as demais variáveis constantes.
Ou seja:
Dummy em regressão: mede quanto muda, em média, quando passamos da categoria de referência para a categoria alternativa .
O alfa nas variáveis Dummys é o valor medio de Y de quem está na categoria de referência.
O Beta é o quanto se altera de Y quando se passa da categoria de referencia para categorias alternativa. (0 categoria referencia e 1 categoria alternativa). Não importa qual vai ser 0 ou qual categoria será 1, sempre retorna o mesmo valor.
Por exemplo:
Onde:
A interpretação de é:
Quando a observação pertence à categoria alternativa , o valor esperado de muda em média unidades em relação à categoria de referência , mantendo constante.
Exemplo simples
Imagine um modelo para explicar o tempo de entrega:
Onde:
Se o modelo estimou:
A interpretação seria:
Entregas feitas por motoboy têm, em média, 8 minutos a menos no tempo de entrega em relação às entregas feitas por carro, considerando a mesma distância.
Se fosse:
A interpretação seria:
Entregas feitas por motoboy têm, em média, 5 minutos a mais no tempo de entrega em relação às entregas feitas por carro, considerando a mesma distância.
Com 3 categorias se cria 2 Dummies , utilizando One-Hot-encoding.
O valor da Y (variável dependente) vai dizer qual modelos podemos utilizar.
Modelos são correlacionais, não causais, não sei se as variáveis X causam a Y. Correlação não implica causalidade.
Os GLM (modelos lineares generalizados) ampliam a ideia dos modelos lineares tradicionais, permitindo analisar diferentes tipos de variável resposta, não apenas variáveis contínuas com distribuição Normal.
A lógica central continua sendo a mesma: construir um preditor linear a partir das variáveis explicativas. Porém, os GLMs introduzem dois elementos importantes:
Componente aleatório
Nos modelos lineares clássicos, geralmente assumimos que a variável resposta segue uma distribuição Normal. Já nos GLMs, essa exigência é flexibilizada.
A variável resposta pode seguir distribuições pertencentes à família exponencial, como:
Normal: para dados contínuos aproximadamente simétricos;
Poisson: para dados de contagem;
Binomial: para respostas binárias ou proporções;
Gama: para dados contínuos positivos e assimétricos.
Isso torna os GLMs úteis para situações em que a variável resposta não se comporta bem como uma variável Normal.
Função de ligação
A função de ligação conecta a média esperada da variável resposta ao preditor linear do modelo.
De forma geral:
g(μ)=η
Onde:
η=β0+β1X1+β2X2+⋯+βpXp
Aqui:
μ representa a média esperada da variável resposta;
g(μ) é a função de ligação;
η é o preditor linear;
β0,β1,…,βp são os coeficientes do modelo;
X1,X2,…,Xp são as variáveis explicativas.
A função de ligação permite modelar a relação entre a resposta e os preditores de forma adequada à distribuição escolhida. Por exemplo, em modelos de contagem, ela ajuda a garantir que os valores previstos sejam sempre positivos; em modelos binomiais, garante que as probabilidades previstas fiquem entre 0 e 1.
Uma forma simples de resumir é:
O GLM mantém a estrutura linear nos parâmetros, mas permite trabalhar com diferentes distribuições da variável resposta por meio de uma função de ligação adequada.
Exemplos de modelos GLM:
Modelo GLM
Tipo da variável dependente
Tipo de resposta
Distribuição usada
Função de ligação comum
Exemplo
Regressão Linear
Quantitativa contínua
Valores numéricos contínuos e aproximadamente simétricos
Normal
Identidade
Valor de imóvel, altura, temperatura
Regressão Logística
Qualitativa nominal binária
Duas categorias, como sim/não ou 0/1
Binomial
Logit
Aprovação/reprovação, doente/não doente
Regressão de Poisson
Quantitativa discreta
Contagem de eventos
Poisson
Log
Número de reclamações, número de atendimentos
Regressão Binomial Negativa
Quantitativa discreta
Contagem com superdispersão
Binomial Negativa
Log
Número de internações com alta variabilidade
Regressão Gama
Quantitativa contínua positiva
Valores positivos e assimétricos à direita
Gama
Log ou inversa
Custo hospitalar, tempo de internação
OBS:
observação importante:
A Regressão Logística trabalha com uma variável dependente qualitativa nominal binária, porque a resposta representa categorias, como:Y={1,0,simna˜o
Já modelos como Poisson e Binomial Negativa usam variáveis dependentes quantitativas discretas, pois a resposta é uma contagem:Y=0,1,2,3,…
E modelos como Linear e Gama usam variáveis dependentes quantitativas contínuas, pois a resposta representa medidas numéricas em escala contínua.
Distribuição característica:
Modelo GLM
Distribuição
Tipo da variável dependente
Quando usar
Forma aproximada da distribuição
Regressão Linear
Normal
Quantitativa contínua
Quando a resposta é contínua e aproximadamente simétrica
🔔 Curva em sino
Regressão Logística
Binomial
Qualitativa nominal binária
Quando a resposta possui duas categorias, como 0/1, sim/não
⚫ ⚪ Dois resultados possíveis
Regressão de Poisson
Poisson
Quantitativa discreta
Quando a resposta representa contagem de eventos
▂▅█▆▃ Barras de contagem
Regressão Binomial Negativa
Binomial Negativa
Quantitativa discreta
Quando há contagem com variância maior que a média
▂▃▆█▅▃ Cauda mais longa
Regressão Gama
Gama
Quantitativa contínua positiva
Quando a resposta é positiva e assimétrica à direita