Função pipeline()
Funcionamento:
Biblioteca função pipeline(), conecta os passos do seu modelo, exemplo abaixo:
Esse modelo utiliza um modelo pré-treinado e ajustado(fine-tuned) e analisa sentimentos dos textos em ingles.

Na função pipeline() exitem outras funcionalidades, como:
feature-extraction(pega a representação vetorial do texto)fill-mask(preenchimento de máscara)ner(reconhecimento de entidades nomeadas)question-answering(responder perguntas)sentiment-analysis(análise de sentimentos)summarization(sumarização)text-generation(geração de texto)translation(tradução)zero-shot-classification(classificação “zero-shot”)
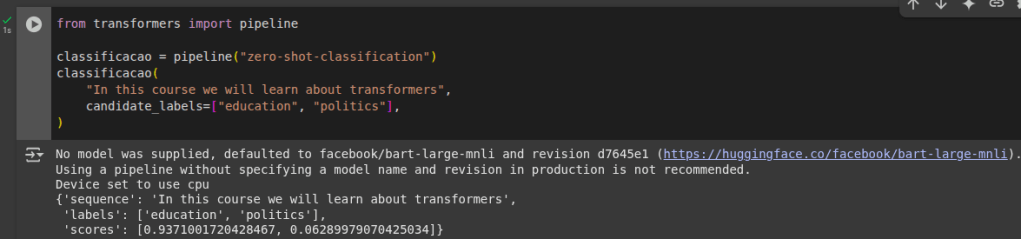
Exemplo da função pipeline com zero-shot. Essa pipeline zero-shot você especifica quais rotulos deseja utilizar, escolhendo especificamento nos modelo já treinados, sem precisar fazer ajuste fino do modelo nos seus dados e já retorna os scores na lista de rótulos que você escolheu.

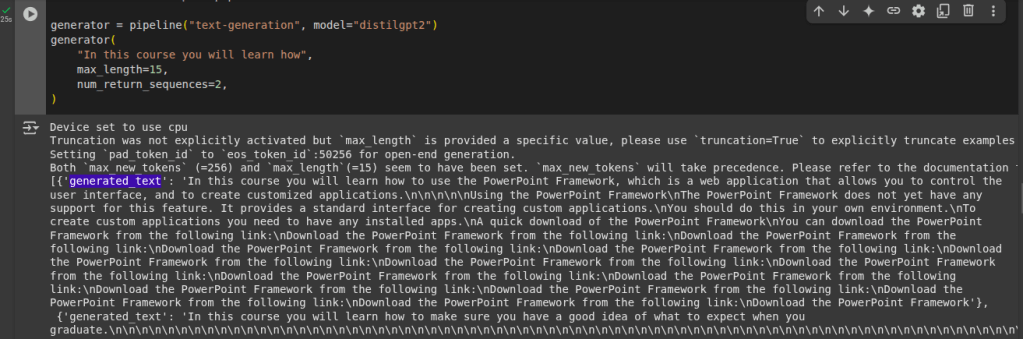
Text-generation (geração de texto):
Nesse pipeline text-generation você passa um trecho de um texto e o modelo irá completar o restante.
Pode adicionar tambem os argumentos num_return_sequences (a quantidade de diferentes sequências são geradas) e o argumento max_length (tamanho máximo da saida-output).

Escolha de modelo no HuggingFace: https://huggingface.co/models
filtrar modelos por tarefas especificas:

Tarefas especificas e em outro idioma ou multi-lingual:


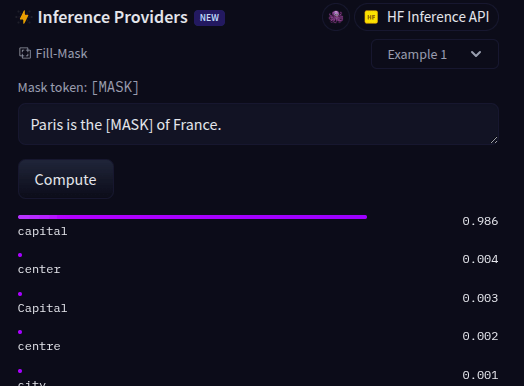
Fill-mask (preenchimento de máscara)
O pipeline mask-filling preenche algum espaço em branco por um texto:
OBS: a variavel <mask>, pode variar o modo como é chamada, exemplo no modelo bert é [MASK], verifique no modelo API antes https://huggingface.co/models?pipeline_tag=fill-mask&sort=trending


Exemplo em portugues:

NER (Reconhecimento de Entidades Nomeadas)
Reconhece as entidades, como nome, cidade, local trabalho.
no ner a função “grouped_entities=True” diz para agrupar em uma unica palavra uma entidade em uma, exemplo: “Data Science”
PER:Pessoa/Nome
LOC: Local

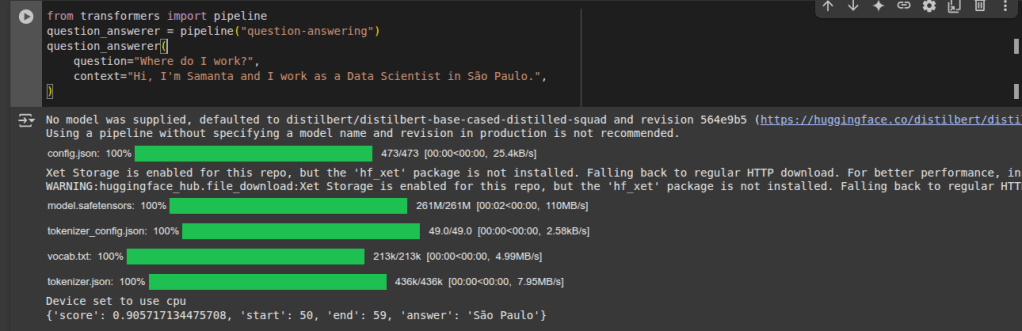
question-answering (extrai a resposta da pergunta)
summarization (sumarização)
Reduz o texto para um texto menor, o resumo escolhe partes importantes do texto

Tradução (translation)

Todos os códigos estão no github: https://github.com/samantaleke/LLM/blob/main/pipeline.py
