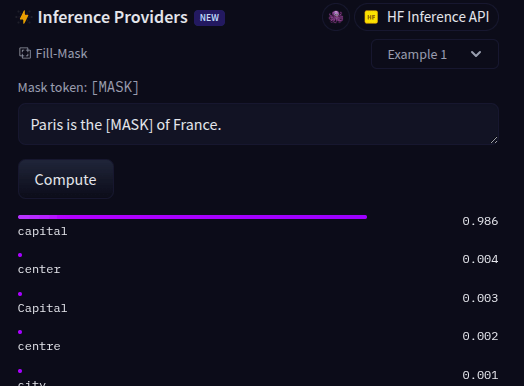
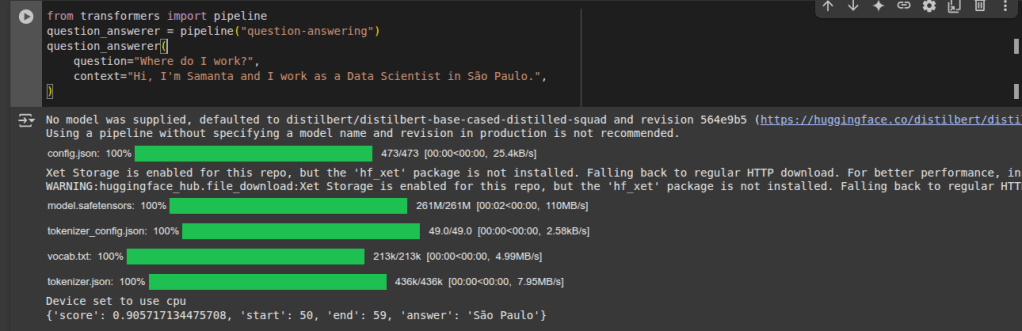
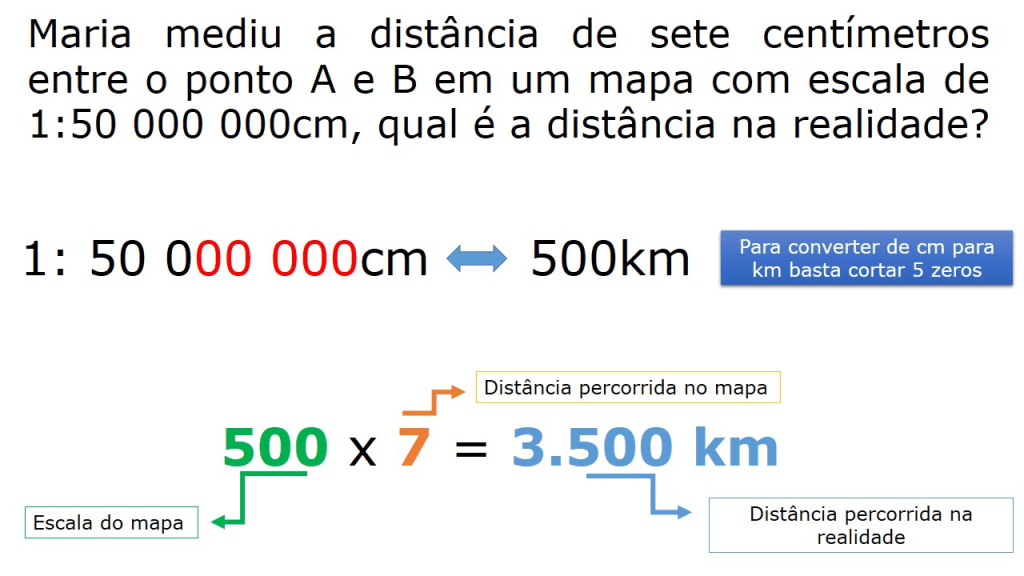
A Programação Linear é um dos pilares da Pesquisa Operacional.
Otimização Linear, ou Programação Linear (PL), é um método matemático para tomar a melhor decisão em um problema, maximizando ou minimizando um objetivo (como lucro ou custo) sujeito a um conjunto de restrições representadas por equações lineares. Ela é aplicada na pesquisa operacional para resolver situações complexas do mundo real, como planejamento de produção, definindo as quantidades ideais de produtos a fabricar para otimizar o lucro, ou criando misturas com o menor custo possível, respeitando a disponibilidade de componentes.
Função Objetivo é linear: min ou max da função linear abaixo.
Restrições tambem linear: Limitações de recursos (materiais, tempo, mão de obra), expressas como inequações (<= ou >=) ou equações (=) lineares.
s.a.: Ax >= bx>=0
Objetivo: Maximizar o lucro ou minimizar custos, expresso como uma função linear .
Elementos Principais:
Função Objetivo:Uma função matemática (linear) que expressa o objetivo do problema, como maximizar o lucro ou minimizar o custo.
Variáveis de Decisão:As variáveis que precisam ser determinadas para atingir o objetivo (ex: quantidade de cada produto a ser produzida).
Restrições:Condições que limitam as variáveis de decisão, expressas como igualdades ou desigualdades lineares (ex: disponibilidade de ingredientes, demanda máxima ou mínima de um produto).
Objetivos exemplos:
Ter unico otimizador global.
Ter infinitos otimizadores globais
Ser infactivel.
Ser factivel, mas sem otimizador.
em python podemos utilizar as bibliotecas linprog, mip, pub
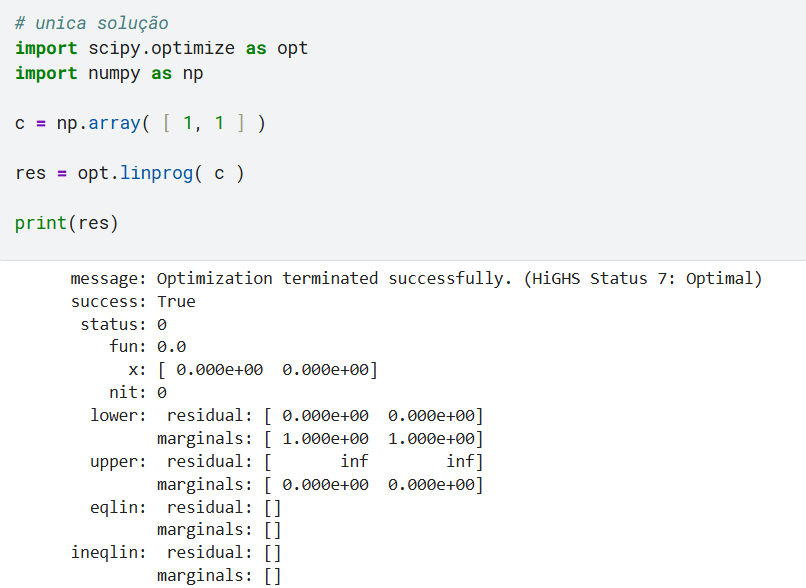
1) Unica solução:
Obs: por padrao no linprog bounds = ( 0, None ), que são as restrições da “Unica solução”
2) Infinitas soluções:
Obs.: Aqui as restrições acima estão em A_eq e b_eq
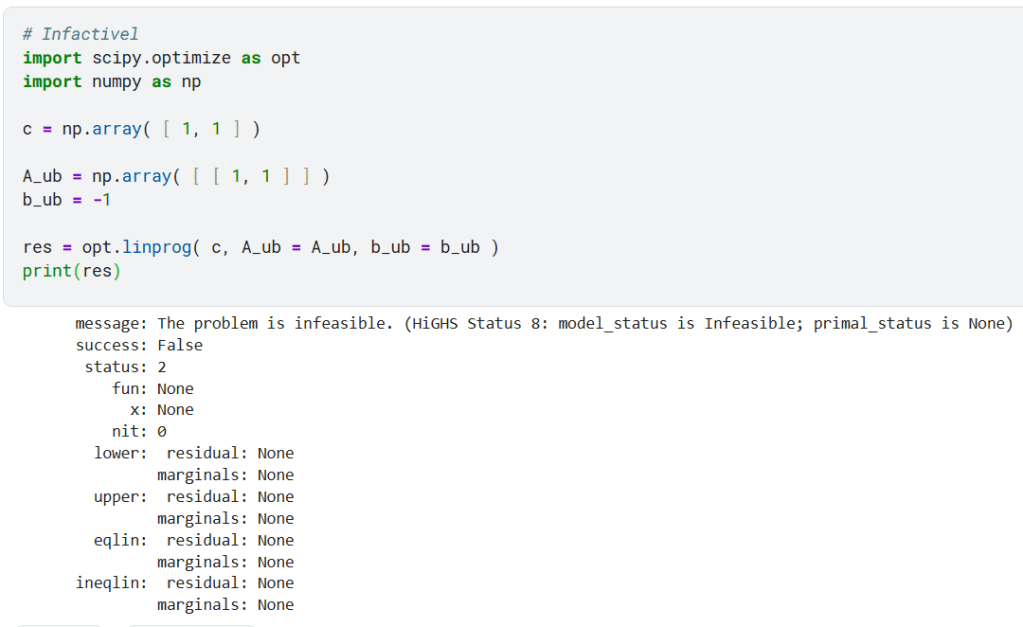
3) Infactivel
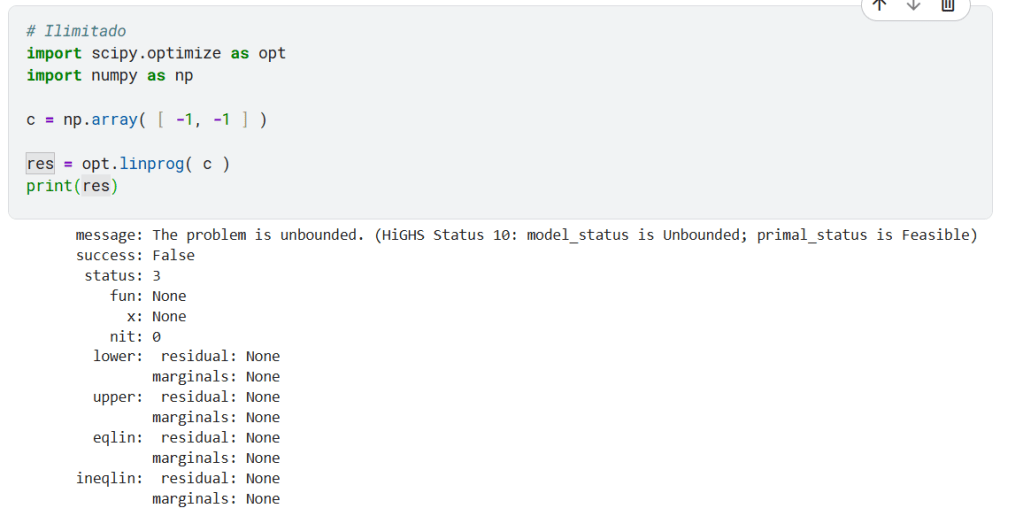
4) Ilimitado
Alguns Exemplo de otimizador em python:
com a biblioteca do scipy.optimize.minimize_scalar extraimos o minimo e no código abaixo adicionamos um intervalo de limite para ele achar o minímo.
*Observação: o exemplo acima não representa um problema de otimização linear, pois a função objetivo não é linear e não há restrições lineares explícitas.
Trata-se apenas de uma demonstração do uso da biblioteca scipy.optimize para ilustrar como algoritmos numéricos encontram mínimos de funções.
A variância influencia fortemente a significância.
1. Conceito de significância estatística
A significância vem de testes de hipótese.
Ela mede se um efeito observado (ex.: diferença entre médias, coeficiente de regressão, correlação) é provável de ter ocorrido por acaso ou se é um efeito consistente.
É expressa por meio do valor-p: quanto menor o valor-p, maior a evidência contra a hipótese nula (de “não efeito”).
2. Papel da variância
A variância dos dados afeta o erro padrão (desvio padrão da média ou do estimador).
Quanto maior a variância, maior a dispersão dos dados → maior o erro padrão → o teste estatístico perde poder → é mais difícil encontrar significância.
Quanto menor a variância, os dados ficam mais concentrados → menor o erro padrão → aumenta a chance de detectar um efeito como significativo (se ele existir).
Em fórmulas simplificadas, um teste t é:
E o erro padrão depende da variância:
Ou seja: se a variância (σ²) é alta, o erro é grande → t cai → p-valor aumenta → menor chance de significância.
O que são dados paramétricos?
São dados que seguem uma distribuição conhecida, geralmente a distribuição Normal (Gaussiana), ou que podem ser transformados para se aproximar dela (por exemplo, usando Box-Cox).
Quando dizemos que uma análise é paramétrica, significa que:
Faz suposições sobre os parâmetros da população (média, variância, etc.);
Assume que os dados vêm de uma distribuição específica (na maioria das vezes, normal);
Usa fórmulas matemáticas que dependem dessas premissas.
🔹 Exemplos de testes paramétricos
Teste t de Student (médias)
ANOVA (comparação de médias entre grupos)
Correlação de Pearson
Regressão linear
🔹 Características dos dados paramétricos
Normalidade – os dados seguem (ou aproximadamente seguem) distribuição normal.
Homocedasticidade – variâncias dos grupos comparados são iguais ou semelhantes.
Independência – as observações não podem estar correlacionadas indevidamente.
Escala intervalar ou de razão – precisam ser dados numéricos contínuos (ex.: altura, tempo, tamanho de banco de dados em GB).
🔹 Comparação com dados não paramétricos
Paramétricos: mais poderosos, mas exigem que os pressupostos sejam atendidos.
Não paramétricos: usados quando os dados não seguem normalidade ou não têm variâncias iguais (ex.: teste de Mann-Whitney, teste de Kruskal-Wallis).
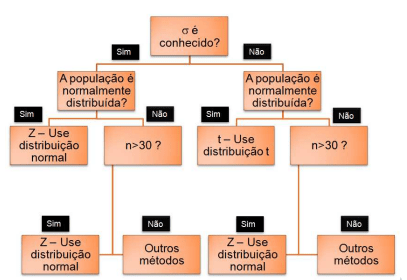
Testes de Hipótese para dados Paramétricos (pressupõem normalidade dos dados):
OBS: para utilizar testes paramétricos , antes deve realizar teste de normalidade !!! (Ex. Shapiro-wilk-amostras pequenas < 30)
Teste para a média (com variância conhecida)
Teste para a média (com variância desconhecida)
Teste para a variância
Teste t pareado (comparação de médias em duas amostras dependentes)
Teste t independente (comparação de médias em duas amostras independentes)
ANOVA (comparação de médias em três ou mais grupos independentes)
Teste para comparação de variâncias
No quadro de decisão em testes de hipótese em formato de imagem, com destaque visual:
Erro Tipo I (α) em vermelho claro → rejeitar H₀ quando ela é verdadeira.
Erro Tipo II (β) em amarelo claro → não rejeitar H₀ quando ela é falsa.
As demais situações mostram as decisões corretas.
🚀 Passos para Realizar um Teste de Hipóteses
Definir a variável em estudo
Identificar qual parâmetro será avaliado (média, variância, proporção etc.).
Definir as hipóteses
Hipótese nula (H₀): não há efeito/diferença (hipótese padrão).
Hipótese alternativa (H₁): existe efeito/diferença.
Escolher o nível de significância (α)
Probabilidade de cometer Erro Tipo I.
Valor comum: α = 0,05 (5%).
Selecionar o teste estatístico
Depende do tipo de dado e do problema:
Teste z → variância conhecida e amostra grande.
Teste t → variância desconhecida ou amostra pequena.
ANOVA, Qui-quadrado, F de Snedecor, etc.
Calcular a estatística de teste
Usar a fórmula do teste escolhido.
Comparar com valores críticos ou p-valor.
🧪 Testes de Hipótese para a Média Populacional:
Distribuição usada:
Se σ (variância populacional) é desconhecida → teste t de Student (mais comum).
Se σ é conhecida → pode-se usar o teste Z.
Para verificar se a média populacional μ é igual a um valor específico μ0:
🔹 Teste bicaudal (duas caudas)
H₀: μ=μ0
H₁: μ≠μ0 👉 Usado quando queremos detectar qualquer diferença (maior ou menor).
🔹 Teste unicaudal superior (uma cauda à direita)
H₀: μ=μ0
H₁: μ>μ0 👉 Usado quando queremos verificar se a média é maior que μ0.
🔹 Teste unicaudal inferior (uma cauda à esquerda)
H₀: μ=μ0
H₁: μ<μ0 👉 Usado quando queremos verificar se a média é menor que μ0.
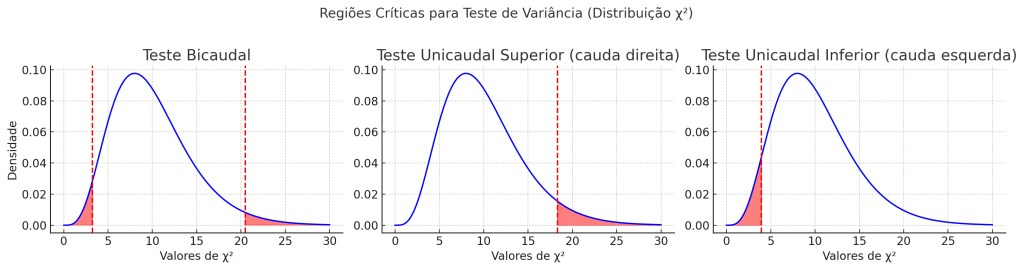
🧪 Teste para a Variância Populacional (qui-quadrado):
Ele é a versão análoga ao que vimos para a média, mas aqui usamos como estatística de teste a qui-quadrado .
Distribuição usada:
Porem assumimos que a média é conhecida e a variância que é desconhecida.
Seguem os gráficos das regiões críticas para o teste de variância usando a distribuição qui-quadrado:
Teste unicaudal inferior → rejeita H0 se χ2 cair na cauda esquerda.
Teste bicaudal → rejeita H0 se χ2 cair nas extremidades (caudas vermelhas).
Teste unicaudal superior → rejeita H0 se χ2 cair na cauda direita.
Estimador é uma função da amostra, ele é uma variável aleatória que varia com a amostra.
Distribuição amostrais dos estimadores.
Exemplo:
Suponha que temos uma população com distribuição normal cuja média μ e desvio-padrão σ .
Abaixo vamos ver:
Viés;
Consistência;
Eficiência.
Distribuição amostral média:
É a distribuição de probabilidades de todas as médias amostrais possíveis de um certo tamanho (n) retiradas de uma população .
Exemplo: Se você tirar várias amostras de tamanho 10 de uma população, você obterá várias médias. A distribuição dessas médias é a distribuição amostral da média.
Exercicio:
Definição da População: Considera-se uma urna contendo três bolinhas numeradas de 1, 2 e 3. Esta é a população.
Definição da Amostra: . É retirada uma amostra aleatória com reposição de duas bolinhas da urna.O tamanho da amostra é n=2.
Possíveis Amostras e Suas Médias:
Listagem das Amostras: . Todas as combinações possíveis de duas bolinhas com reposição são listadas.
O espaço amostral 𝑆 é dado por:
S={(1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3)} O número total de amostras possíveis é :
Estimador não viesado:
Um estimador é não enviesado , se em média, não está tedendo a superestimar ou subestimar o verdadeiro valor do parâmetro.
A distribuição amostral da média, ou média amostral (X̄), é a distribuição de todas as médias possíveis de amostras aleatórias de um determinado tamanho (n) extraídas de uma população. Este estimador é não viesado porque o seu valor esperado é igual à média populacional (µ). A distribuição amostral da média, graças ao Teorema do Limite Central, tende a ser aproximadamente normal, mesmo que a população original não seja normal, especialmente para amostras grandes.
Por que a média amostral (X̄) é um estimador não viesado?
Um estimador é não viesado (ou não viciado) se o seu valor esperado é igual ao parâmetro populacional que ele está a tentar estimar.
No caso da média, o valor esperado da média amostral é igual à média populacional (E(X̄) = µ).
Isso significa que, em média, a média amostral não tende a superestimar ou subestimar a verdadeira média da população.
Consistência do Estimador:
Definição: Um estimador é consistente se, ao aumentar o tamanho da amostra (n), o seu valor se aproxima cada vez mais do valor real do parâmetro populacional que ele tenta estimar.
Como funciona: Para um estimador da média ser consistente:
A esperança (valor esperado) deve tender ao parâmetro: Ou seja, em média, o estimador deve se aproximar do valor real da média populacional, mesmo com a variabilidade natural das amostras.
A variância deve tender a zero: À medida que n aumenta, a dispersão dos valores do estimador deve diminuir, indicando que os valores obtidos com amostras maiores estão mais concentrados em torno do parâmetro populacional.
Em resumo:
Estimador Não Viesado, mas Não Consistente
Definição: Um estimador não viesado tem o seu valor esperado igual ao verdadeiro parâmetro populacional (E(T) = θ). Um estimador não consistente tem a sua variância que não tende a zero à medida que o tamanho da amostra cresce.
Exemplo: Considere a variância de uma população, σ². Um estimador para ela pode ser obtido usando a média de frequência amostral, que é o estimador de variância tendencioso do livro e sua amostra.
Estimador Viesado, mas Consistente
Definição: Um estimador viesado tem um viés não nulo, ou seja, o seu valor esperado não é igual ao parâmetro real. Um estimador consistente tem a sua variância que tende a zero à medida que o tamanho da amostra se aproxima do infinito.
Exemplo: Um estimador da variância populacional, σ², usando o denominador de n, pode ser usado para a variância da amostra. Este estimador tem um viés, mas é consistente.
Como Identificar Estimadores Não Viesados e Consistentes
Um estimador é não viesado se E(T) = θ, e é consistente se a variância de T tende a zero quando o tamanho da amostra n tende ao infinito.
Em geral, os estimadores não viesados e consistentes são preferíveis, pois fornecem estimativas mais precisas e não tendem a subestimar ou superestimar o parâmetro ao longo do tempo.
Variância Pequena (Eficiência): Um bom estimador deve ser consistente e ter uma variância pequena, significando que a variância do estimador tende a zero quando o tamanho da amostra é grande.
Eficiência do Estimador:
Variância Pequena (Eficiência): Um bom estimador deve ser consistente e ter uma variância pequena, significando que a variância do estimador tende a zero quando o tamanho da amostra é grande.
Erro quadratico médio (MSE):
Soma da variância do estimador + o viés ao quadrado do estimador, fornecendo uma maneira útil de calcular o MSE e implicando que, no caso de estimadores não tendenciosos, o MSE e a variância são equivalentes. MSE ( θ ^ ) = Var θ ( θ ^ ) + Bias ( θ ^ , θ ) 2.
O quadrado do vies: o quanto o estimador está longe do valor verdadeiro.
A variância: o quanto o estimador pode variar em diferentes amostras da população.
Máxima Verossimilhança (MLE):
A “máxima verossimilhança” (ou Estimativa de Máxima Verossimilhança – MLE) é um método estatístico para estimar os parâmetros de um modelo probabilístico, procurando os valores que tornam os dados observados o mais prováveis possível.
o principio da verossimilhança afirma que devemos escolher aquele valor do parâmetro desconhecido que maximiza a probabilidade de obter a amostra particular observada, ou seja, o valor que torna aquela amostra a “mais provável”. Exemplo de Verossimilhança: A função de verossimilhança para estimar a probabilidade de um pouso de uma moeda sem conhecimento prévio de seu lançamento.
Verossimilhança vs. Probabilidade
“Não confunda verossimilhança com probabilidade. Enquanto a probabilidade mede a chance de observar dados específicos dado um conjunto de parâmetros, a verossimilhança mede a plausibilidade de um conjunto de parâmetros dado os dados observados. Em outras palavras, a verossimilhança é uma função dos parâmetros, enquanto a probabilidade é uma função dos dados. Essa distinção é crucial para a correta aplicação de métodos estatísticos.”
“O intervalo de confiança é um intervalo numérico construído ao redor da estimativa de um parâmetro. Ele utiliza um procedimento que, ao ser repetido em várias amostras hipotéticas, gera intervalos contendo o valor verdadeiro do parâmetro em X% dos casos.
Vamos dividir essa definição em partes. Primeiramente, o intervalo de confiança possui limites inferior e superior, calculados ao redor da estimativa de um parâmetro, θ-chapéu.”
Intervalo de confiança para média com variância conhecida:
Para um intervalo de confiança da média populacional (μ) com variância (σ²) conhecida, utiliza-se a distribuição normal e a fórmula: x̄ ± Z * (σ/√n), onde x̄ é a média amostral, Z é o valor crítico da distribuição normal para o nível de confiança desejado (ex: 1,96 para 95% de confiança), σ é o desvio padrão populacional e n é o tamanho da amostra.
Intervalo de confiança para média com variância desconhecida:
Para construir um intervalo de confiança para a média populacional com variância desconhecida, usa-se a distribuição t de Student em vez da distribuição normal padrão, pois a variância populacional é desconhecida e, geralmente, trabalha-se com amostras pequenas. A fórmula do intervalo é a média amostral mais ou menos o produto do valor t de Student (determinado pelo nível de confiança e graus de liberdade) pela margem de erro, que é o desvio padrão amostral dividido pela raiz quadrada do tamanho da amostra.
Passos para calcular o intervalo de confiança:
Determinar o nível de confiança: Geralmente são 90%, 95% ou 99%.
Calcular os graus de liberdade (gl): Em geral, gl = n – 1, onde n é o tamanho da amostra.
Encontrar o valor t de Student: Utilize uma tabela t de Student ou software estatístico com base no nível de confiança e nos graus de liberdade.
Calcular o desvio padrão amostral (s): Esta é a medida da variabilidade da amostra.
Calcular o erro padrão da média: Divida o desvio padrão amostral pela raiz quadrada do tamanho da amostra (n).
Calcular a margem de erro: Multiplique o valor t de Student pelo erro padrão da média.
Construir o intervalo: Some e subtraia a margem de erro da média amostral (x̄) para obter os limites inferior e superior do intervalo.
Exemplo prático: Assumindo que você tem uma amostra de tamanho n, com média x̄ e desvio padrão s, e deseja um intervalo de confiança de 95%:
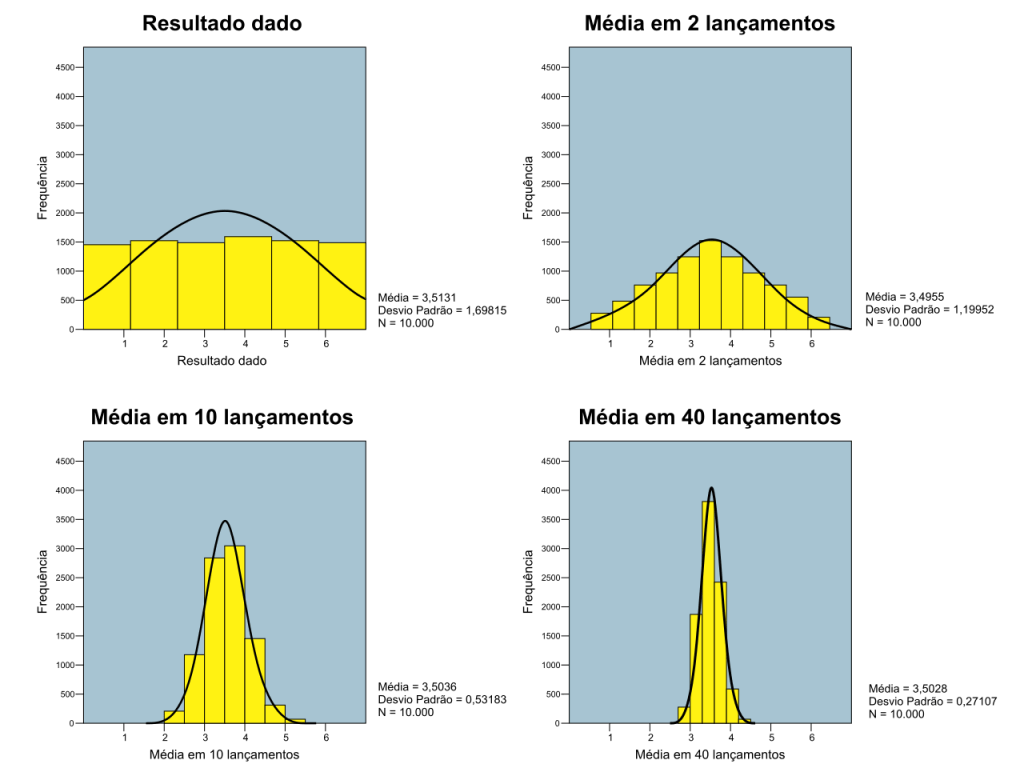
“O Teorema Central do Limite nos diz que conforme o tamanho da amostra aumenta, a distribuição amostral da média aproxima-se cada vez mais de uma distribuição normal. Portando a ideia é retirar várias amostras de uma mesma população, tomando a média de cada uma delas. A distribuição dessas médias é que tenderá a uma distribuição normal.” site: https://cursos.alura.com.br/forum/topico-teorema-do-limite-central-explicacao-148382, acesso 16 de setembro de 2025.
Principais Conceitos
Distribuição Amostral da Média: É a distribuição de todas as possíveis médias amostrais que podem ser obtidas ao tirar amostras de uma população.
Independência e Distribuição Idêntica: As variáveis aleatórias devem ser independentes umas das outras e terem a mesma distribuição.
Distribuição Normal: Uma distribuição de probabilidade simétrica em forma de sino, caracterizada por sua média e desvio padrão.
Condições do Teorema
O tamanho da amostra deve ser suficientemente grande. Geralmente, uma amostra com 30 ou mais observações é considerada adequada.
A população da qual as amostras são tiradas deve ter uma média e um desvio padrão bem definidos.
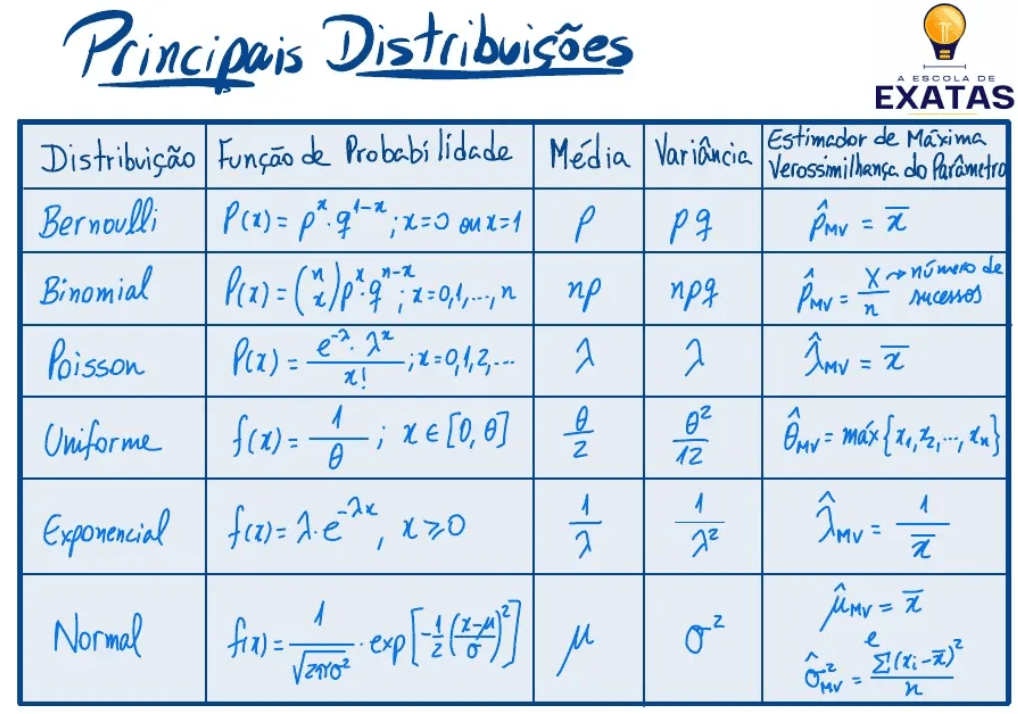
Bernoulli – 1 ou 0 (Ex. sim ou não ou sucesso ou não sucesso):
A probabilidade de X assumir um determinado valor x (0 ou 1) é dada por P(X = x) = px(1-p)1-x
Exemplo:
Um inspetor de qualidade extrai uma amostra aleatória de 10 tubos armazenados num depósito onde, de acordo com os padrões de produção, se espera um total de 20% de tubos defeituosos. Qual é a probabilidade de que não mais do que 2 tubos extraídos sejam defeituosos? Se X denotar a variável “número de tubos defeituosos em 10 extrações independentes e aleatórias”, qual o seu valor esperado? Qual a variância?
Note que a variável aleatória X = número de tubos defeituosos em 10 extrações tem distribuição binomial, com parâmetros n = 10 e p = 0,2. Portanto, “não mais do que dois tubos defeituosos” é o evento {X ≤ 2}. Sabemos que, para X ∼ b(10 , 0,2)
Se X ∼ b(n, p), então E(X) = np Var(X) = np(1 − p) Basta então aplicar os valores fornecidos para vermos que o n´umero esperado de tubos defeituosos num experimento com 10 extrações é de 2, e que a variância é de 1,6.
Binomial:
A distribuição binomial é usada para calcular a probabilidade de obter um certo número de “sucessos” em um número fixo de “tentativas” (ensaios de Bernoulli), onde cada tentativa tem apenas dois resultados possíveis e os resultados são independentes.
Fórmula:
n: O número total de tentativas.
k: O número de sucessos desejados.
p: A probabilidade de sucesso em uma única tentativa.
q (ou 1-p): A probabilidade de fracasso em uma única tentativa.
Como usar a fórmula:
A fórmula geral da distribuição binomial é: P(X=k) = C(n, k) * p^k * q^(n-k)
Onde:
P(X=k): A probabilidade de obter exatamente k sucessos.
C(n, k): O coeficiente binomial, que representa o número de combinações de escolher k sucessos em n tentativas.
p^k: A probabilidade de k sucessos.
q^(n-k): A probabilidade de (n-k) fracassos.
Poisson:
média e variância valores iguais.
Resumo:
A Distribuição de Bernoulli descreve o resultado de um único ensaio com dois resultados possíveis (sucesso ou fracasso);
A Distribuição Binomial modela a soma de vários ensaios de Bernoulli independentes, contando o número de sucessos;
A Distribuição de Poisson lida com a probabilidade de um certo número de eventos ocorrerem num intervalo fixo de tempo ou espaço, sendo útil para eventos raros.
Continuos
Uniforme: é um modelo de probabilidade onde cada resultado possível dentro de um determinado intervalo tem a mesma probabilidade de ocorrer.
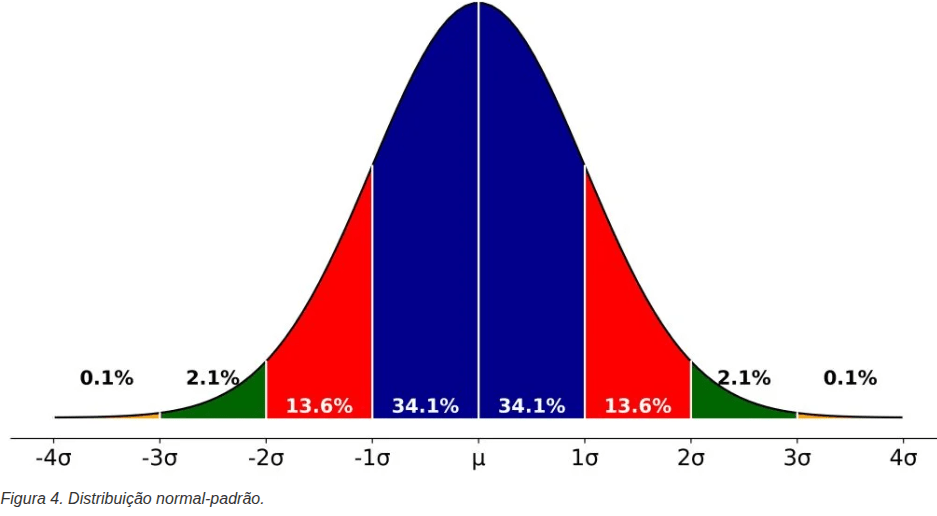
Distribuição normal: uma distribuição contínua e simétrica ao redor da média, a maioria dos valores tende a se agrupar ao redor da média e valores que se afastam da média (para mais ou para menos) tendem a ser menos frequentes.
Normal padrão:uma distribuição normal teórica especial, cuja média é 0 e o desvio-padrão é 1.
Exponencial:
É uma distribuição de probabilidade contínua que modela o tempo até a ocorrência de um evento em um processo de Poisson, ou seja, eventos que acontecem de forma independente e a uma taxa constante. Ela descreve a probabilidade de um evento ter uma duração ou ocorrer dentro de um certo tempo, sendo muito usada em áreas como análise de confiabilidade (tempo de vida de componentes) e tempos de espera.
Exemplo: você quer saber a probabilidade de um aparelho eletrônico continuar funcionando após 3 anos, sabendo que, em média, ele dura 2 anos. A probabilidade de ele continuar funcionando diminui com o passar do tempo, o que é uma característica da distribuição exponencial.
Parecida com a normal , mas com a cauda mais “pesada”, indicando uma maior probabilidade de ocorrerem valores extremos, mas aproxima-se da distribuição normal à medida que o número de graus de liberdade aumenta.
É uma distribuição de probabilidade em forma de sino, semelhante à distribuição normal, mas utilizada quando se trabalha com amostras pequenas ou com a variância populacional desconhecida.
Amostras pequenas: É a escolha ideal quando o tamanho da amostra é pequeno (geralmente inferior a 30 observações).
Variância populacional desconhecida: Utiliza-se quando não se sabe o desvio padrão ou a variância da população.
Qui-quadrado
é uma distribuição de probabilidade contínua usada em inferência estatística para testes de hipóteses, especialmente para avaliar se os dados observados se ajustam a uma distribuição esperada (teste de aderência) ou para testar a independência entre variáveis categóricas. Caracteriza-se por ser assimétrica à direita e definida por um parâmetro chamado graus de liberdade (k).
F de Fisher-Snedecor
é uma distribuição de probabilidade de variáveis contínuas, definida como a razão de duas variáveis aleatórias independentes com distribuição qui-quadrado, divididas pelos seus respetivos graus de liberdade. É usada principalmente para inferência sobre a razão entre duas variâncias e em técnicas estatísticas como a Análise de Variância (ANOVA), onde compara a variabilidade entre grupos com a variabilidade dentro dos grupos.
Assimetria: É uma distribuição assimétrica à direita, com valores que assumem apenas valores positivos.
Graus de Liberdade: É caracterizada por dois parâmetros: os graus de liberdade do numerador e do denominador, que influenciam a forma da distribuição.
Objetivo é encontrar a melhor solução possível, onde quantifica a qualidade da solução:
Onde transforma um vetor em um numero real.
Função objetivo:
Direção de otimização, maximizar (solução fornece o maior valore possível) ou minimizar (minimiza o custo), exemplo minimizar o tempo de viagem, ou maximizar o lucro.
Otimizador Global: busca a melhor entre todas as soluções viáveis, onde busca o minimo ou maximo global.
Otimizador Local: não tão complexo comparado a achar o otimizador global (minimo ou maximo), em muitos casos buscamos o minimo ou maximo local.
Restrições:Condições que limitam as variáveis de decisão, expressas como igualdades ou desigualdades lineares (ex: disponibilidade de ingredientes, demanda máxima ou mínima de um produto).
Subconjunto dentro do espaço amostral. Representado por conjunto. Subconjunto do espaço amostral normalmente contem os elementos que estamos tentando calcular a probabilidade dos mesmos.
Evento certo (1%) e evento impossível (0%), exemplo de evento impossível seja dado honesto a probabilidade de cair numero maior que 6 = 0%.
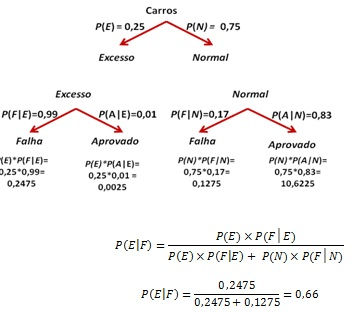
Utilizada para calcular a probabilidade do evento ocorrer dado que outro evento já aconteceu.
P(A|B) = (P(B|A) * P(A)) / P(B)
Sendo:
P(A|B): é a probabilidade do evento A ocorrer dado que o evento B já ocorreu.
P(B|A): é a probabilidade do evento B ocorrer dado que o evento A já ocorreu.
P(A): é a probabilidade inicial do evento A acontecer (probabilidade a priori).
P(B): é a probabilidade do evento B ocorrer.
Exemplo:
Em uma cidade em que os carros são testados para emissão de poluentes, 25% deles emitem quantidade considerada excessiva. O teste falha para 99% dos carros que emitem excesso de poluentes, mas resulta positivo para 17% dos carros que não emitem quantidade excessiva. Qual é a probabilidade de um carro que falha no teste realmente emitir quantidade excessiva de poluentes?
Função massa de probabilidade (FMP) ou (PMF):
Função de massa de probabilidade de uma variável aleatória discreta X é definida como:
Para variaveis aleatórias discretas, que assumem uma contagem.
X é uma variável aleatória discreta,
x é um valor que X pode assumir,
p(x) é a probabilidade de que X seja igual a x.
Com as condições:
Valores não negativos: 0 ≤ P(X=x) ≤ 1 para qualquer valor x possível da variável.
Soma igual a 1: A soma das probabilidades de todos os valores possíveis de X é igual a 1 (∑P(X=x) = 1).
Exemplo:
É lançado duas moedas. Seja 𝑋 = número de caras. Qual a função massa de probabilidade (ou fmp) de X?
Espaço Amostral (Ω)
Todas as combinações possíveis ao lançar duas moedas (cada uma pode dar cara (C) ou coroa (K)): Ω={(C,C), (C,K), (K,C), (K,K)}
Vamos contar quantas caras aparecem em cada resultado:
Resultado
Número de Caras (X)
(C, C)
2
(C, K)
1
(K, C)
1
(K, K)
0
Então, os valores possíveis para X são:
X∈{0,1,2}
Função Massa de Probabilidade (fmp) de X
A função massa de probabilidade P(X=x)P(X = x)P(X=x) nos dá a probabilidade de cada valor de XXX:
x
P(X = x)
Justificativa
0
1/4
só (K, K) tem 0 caras
1
2/4=1/2
(C, K) e (K, C) têm 1 cara
2
1/4
só (C, C) tem 2 caras
import matplotlib.pyplot as plt
# Passo 1: Definir os valores possíveis da variável aleatória X
# X representa o número de caras ao lançar duas moedas
valores_x = [0, 1, 2]
# Passo 2: Definir as probabilidades associadas a cada valor de X
# P(X = 0) = 1/4, P(X = 1) = 2/4, P(X = 2) = 1/4
probabilidades = [1/4, 1/2, 1/4]
# Passo 3: Plotar a função massa de probabilidade (fmp)
plt.figure(figsize=(6, 4)) # Tamanho da figura
plt.stem(valores_x, probabilidades, basefmt=" ", use_line_collection=True)
# Passo 4: Adicionar título e rótulos aos eixos
plt.title('Função Massa de Probabilidade (fmp) de X\nX = número de caras ao lançar 2 moedas')
plt.xlabel('x (número de caras)')
plt.ylabel('P(X = x)')
plt.xticks(valores_x) # Marcar apenas os valores de x possíveis
plt.ylim(0, 0.6) # Ajuste do limite superior do eixo y
plt.grid(True, axis='y', linestyle='--', alpha=0.6)
# Passo 5: Mostrar os valores de probabilidade acima das barras
for x, p in zip(valores_x, probabilidades):
plt.text(x, p + 0.02, f'{p:.2f}', ha='center')
# Exibir o gráfico
plt.tight_layout()
plt.show()
Função de Densidade de Probabilidade (fdp)ou (pdf):
f(x) ≥ 0 ∫f(x)dx = 1
Variáveis aleatórias contínuas usamos a função de densidade de probabilidade (PDF).
“Densidade de uma variável aleatória contínua, é uma função que descreve a verossimilhança de uma variável aleatória tomar um valor dado. A probabilidade da variável aleatória cair em uma faixa particular é dada pela integral da densidade dessa variável sobre tal faixa – isto é, é dada pela área abaixo da função densidade mas acima do eixo horizontal e entre o menor e o maior valor dessa faixa. A função densidade de probabilidade é não negativa sempre, e sua integral sobre todo o espaço é igual a um. A função densidade pode ser obtida a partir da função distribuição acumulada a partir da operação de derivação (quando esta é derivável).”
A variável aleatória contínua X representa a altura (em metros) de uma planta em crescimento, e segue a distribuição normal
, ou seja:
Média μ=1.5\mu = 1.5μ=1.5 m
Desvio padrão σ=0.1\sigma = 0.1σ=0.1 m
Pergunta:
Qual a probabilidade de que uma planta tenha entre 1.4 m e 1.6 m de altura?
from scipy.stats import norm
# Média e desvio padrão
mu = 1.5
sigma = 0.1
# Limites
a = 1.4
b = 1.6
# Cálculo da probabilidade
prob = norm.cdf(b, mu, sigma) - norm.cdf(a, mu, sigma)
print(f'P(1.4 ≤ X ≤ 1.6) = {prob:.4f}')
# P(1.4 ≤ X ≤ 1.6) = 0.6827
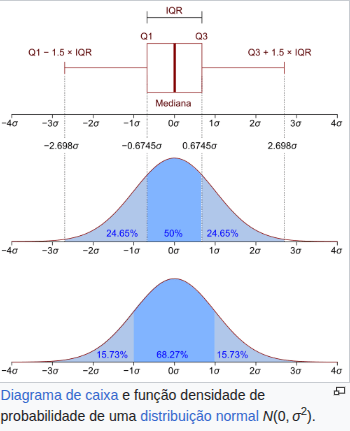
A probabilidade de que uma planta escolhida ao acaso tenha entre 1.4 m e 1.6 m de altura é aproximadamente 68,27%, o que faz sentido — corresponde a uma faixa de ±1 desvio padrão da média numa distribuição normal.
Diferenças entre PMF e PDF:
Tipo
Valores possíveis
Exemplos de variáveis
Discreta
Valores inteiros contáveis
nº de filhos, nº de erros, nº de caras
Contínua
Valores decimais (reais) infinitos em um intervalo
altura, tempo, temperatura, peso
Valor Esperado (Esperança matemática):
“representa o valor médio “esperado” de uma experiência se ela for repetida muitas vezes”.
Para ilustrar o conceito de Valor Esperado, considere um jogo de dados em que um jogador ganha R$10 se tirar um número par e perde R$5 se tirar um número ímpar. As probabilidades de tirar um número par ou ímpar em um dado de seis lados são ambas de 1/2. O cálculo do Valor Esperado seria: (E(X) = (10 cdot frac{1}{2}) + (-5 cdot frac{1}{2}) = 5 – 2.5 = 2.5). Isso significa que, em média, o jogador pode esperar ganhar R$2,50 por rodada, o que ajuda a avaliar se o jogo é vantajoso ou não.
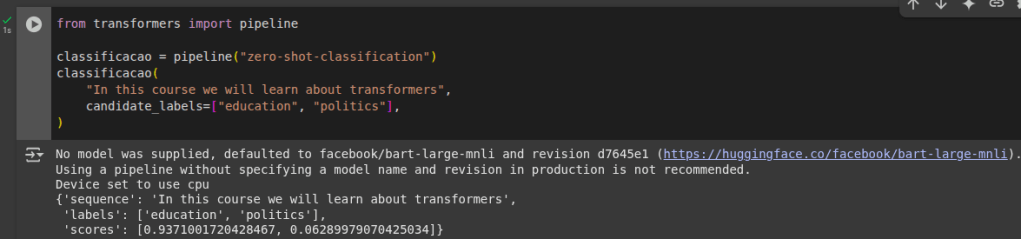
Exemplo da função pipeline com zero-shot. Essa pipeline zero-shot você especifica quais rotulos deseja utilizar, escolhendo especificamento nos modelo já treinados, sem precisar fazer ajuste fino do modelo nos seus dados e já retorna os scores na lista de rótulos que você escolheu.
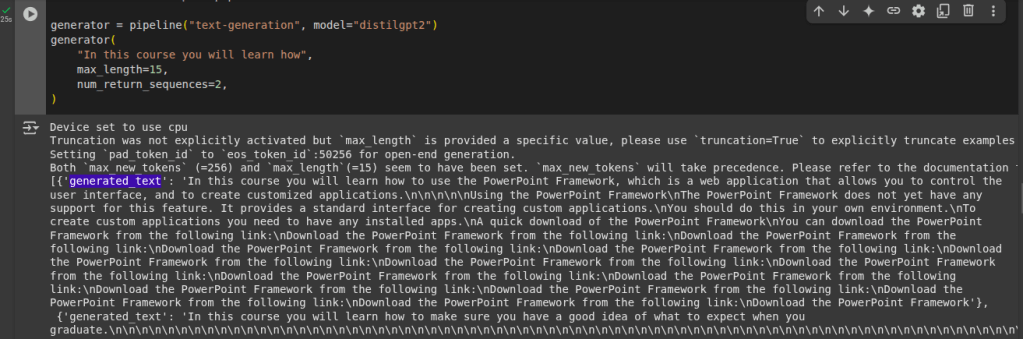
Text-generation (geração de texto):
Nesse pipeline text-generation você passa um trecho de um texto e o modelo irá completar o restante.
Pode adicionar tambem os argumentos num_return_sequences (a quantidade de diferentes sequências são geradas) e o argumento max_length (tamanho máximo da saida-output).
“A cartografia é a ciência e arte de criar, estudar e comunicar informações espaciais por meio de mapas, cartas e outras representações gráficas da superfície terrestre. É uma disciplina que combina conhecimentos de geografia, matemática, informática e outras áreas, para representar e analisar dados espaciais de forma precisa e eficaz. “. Site: https://pt.wikipedia.org/wiki/Cartografia, acesso 15 de maio de 2025.
“Geotecnologia, conjunto de tecnologias para coleta, processamento, análise e disponibilização de informação geográfica. A Geotecnologia envolve aplicação de tecnologias da informação e comunicação para a aquisição, processamento, análise e visualização de dados geoespaciais. Este campo interdisciplinar desempenha um papel crucial em diversas áreas do conhecimento, incluindo geografia, cartografia, geologia, biologia, agricultura, planejamentourbano e gestão de recursos naturais.”. Site: https://pt.wikipedia.org/wiki/Cartografia, acesso 15 de maio de 2025.
Escolha do sistemas de coodenadas.
é uma superfície matematicamente definida que se aproxima do geoide, a verdadeira figura da Terra ou qualquer outro corpo planetário
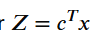

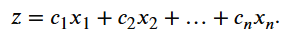
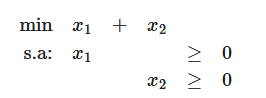
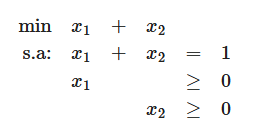

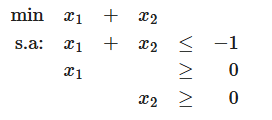
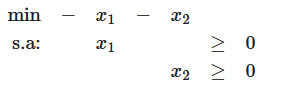



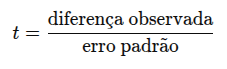






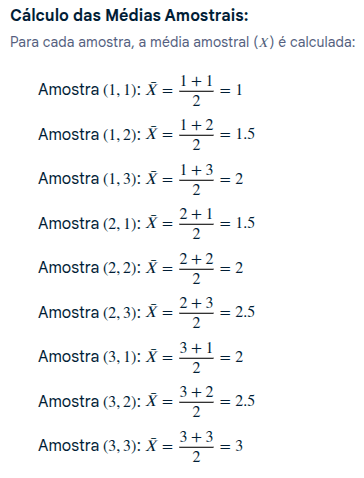





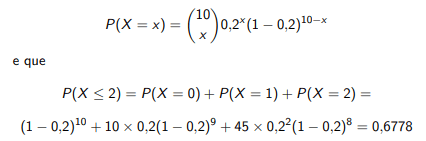
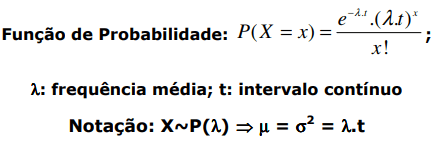






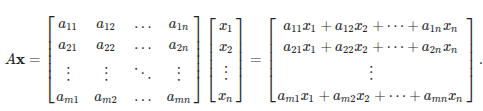








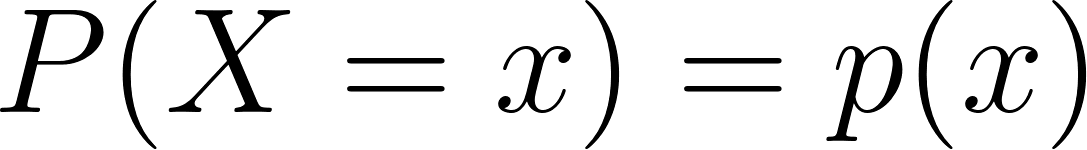
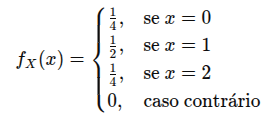

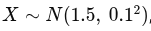

![{\displaystyle E[X]=\sum _{i=1}^{\infty }x_{i}p(x_{i})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ec388d4b85f116933ba7cefbc748c07513518e00)
![{\displaystyle E[X]=\int _{-\infty }^{\infty }xf(x)dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2a6dfe82bf0def7e07f046133a6fcaed082a574)