O virtualenv seria uma VM na sua maquina, ou em um host, para centralizar o projeto de ML , ajudando na administração, gerenciamento e compartilhamento.
Para criar uma virtualenv é simples (utilizo nesse caso tambem o vscode/terminal):
--Criar ambiente virtual - virtualenv
mkdir venv_streamlit
cd venv_streamlit
$ sudo apt-get install -y python3-pip
$ sudo apt-get install build-essential libssl-dev libffi-dev python3-dev
$ sudo apt-get install -y python3-venv
--criar novo ambiente-virtual chamado ambiente-virtual
python3 -m venv ambiente-virtual
--abrir ambiente-virtual
cd ~/Área de Trabalho/venv_streamlit/ambiente-virtual/bin
source activate
--fechar
deactivate
Visualização principalmente com biblioteca python pandas, numpy, seaborn, matplotlib.pyplot.
Abaixo alguns exemplos muito utilizados.
dados_tempo.info()
# object = variável de texto
# int ou float = variável numérica (métrica)
# category = variável categórica (qualitativa)
# Selecionando com base nas posições (1º arg.: linhas, 2º arg.: colunas)
# ATENÇÃO: Linhas iniciam-se em zero! no Python
dados_tempo.iloc[3,] #Somante 3 linha
dados_tempo.iloc[:,4] # Todas as linhas e somente 4 coluna
dados_tempo.iloc[2:5,] # somente a partir da 2 linha até a 5 e todas colunas
dados_tempo.iloc[:,3:5] # todas as linhas, 3 e 5 coluna
Para não ter ponderação arbitraria, exemplo categorizar uma variavel metrica:
## Em certas circunstancias sera necessario trocar o tipo da variável
# Para evitar a ponderação arbitrária, vamos alterar o tipo
df_numeros['novo_perfil'] = df_numeros['novo_perfil'].astype('category')
df_numeros.info()
## categorizar aplicando critérios detalhados por meio de condições
dados_tempo['faixa'] = np.where(dados_tempo['tempo']<=20, 'rápido',
np.where((dados_tempo['tempo']>20) & (dados_tempo['tempo']<=40), 'médio',
np.where(dados_tempo['tempo']>40, 'demorado',
'demais')))
## Ou tambem categorizar eh por meio dos quartis de variaveis (q=4)
dados_tempo['quartis'] = pd.qcut(dados_tempo['tempo'], q=4, labels=['1','2','3','4'])
Matriz de correlações de Pearson
Lembrando que correlação de pearson varia de 1 a -1, onde 0 é sem correlação, 1 grande correlação e -1 grande correlação negativa, negativa é se 1 variável sobe a outra desce.
Correlação mosta Direção e Força e Teste de Hipótese mostra a Confiança.
Finalidade:
Verificar a variância, o quanto varia em relação a média e o desvio padrão
Dependendo do tamanho da base de dados/população, utilizamos a amostra para analise.
Para testar o parâmetro de interesse da amostra, utilizamos os teste de hipótese estatísticas.
Resumo:
Hipótese Nula (H₀): Afirma que não há efeito ou diferença.
Hipótese Alternativa (H₁): Afirma que há um efeito ou diferença significativa.
Nível de Significância (α): Limite para rejeitar H₀, geralmente 0,05 (5%).
Valor-p (p-value): Probabilidade de obter os resultados observados (ou mais extremos), assumindo que H₀ seja verdadeira.
Se p ≤ α: Rejeita-se a hipótese nula; os resultados são considerados estatisticamente significantes.
Se p > α: Não há evidências suficientes para rejeitar H₀.
Testes de hipóteses tradicionais:
Teste t de Student: Compara as médias de dois grupos.(amostra menores)
ANOVA (Análise de Variância): Verifica diferenças entre três ou mais grupos.
Qui-quadrado (χ²): Avalia associações entre variáveis categóricas.
Teste de Wilcoxon e Mann-Whitney: Testes não paramétricos para comparar medianas entre grupos.
Alguns Exemplo de Uso:
Modelos de regressão:
Nos modelos de regressão (linear, logística, etc.), a significância é usada para avaliar se os coeficientes das variáveis independentes são estatisticamente diferentes de zero. Isso ajuda a determinar se essas variáveis têm uma relação significativa com a variável dependente.
Modelos de correlação:
Em análises de correlação (como o coeficiente de Pearson ou Spearman), a significância indica se a associação entre duas variáveis é relevante ou pode ser fruto do acaso.
Testes em machine learning:
Em técnicas como testes de permutação ou validações cruzadas, a significância estatística é usada para avaliar a performance de modelos em comparação a uma distribuição aleatória.
Explicação mais detalhada:
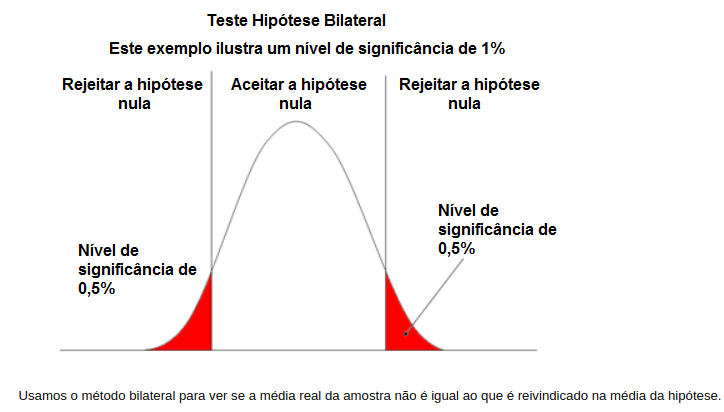
Teste bilateral (bicaudal): teste bilateral, o interesse é testar.
Hipótese Nula (H0): declara que não há relação entre dois fenômenos de interesse. Não ao efeito.
Hipótese alternativa (H1): é estatisticamente diferente de certo valor de interesse. Afirmação e evidencia, podemos tratá-la como uma “novidade” ou “nova”. Ou seja, é a situação em que há algo de diferente.
Sendo necessário ter definido o nível de significância (α) desejado para a análise.
α = 1% (ou seja, o nível de confiança do seu teste é de 99% = 1- α)
α = 5% (ou seja, o nível de confiança do seu teste é de 95% = 1- α)
α = 10% (ou seja, o nível de confiança do seu teste é de 90% = 1- α)
Ou seja, o nível de confiança do teste é definido como 1 – α
P-valor e teste de hipótese
p-valor e nível de significância:
t critico, verificar qual o valor, que a direita é região critica, ou seja, região com 5%. RC região critica é a região de rejeição H0.
Quando o p-valor < α: Rejeita H0.
Quando o p-valor > α: Não Rejeita H0.
Teste Z para médias de uma amostra:
Quando utilizar teste Z:
Quando eu conheço o desvio padrão populacional (banco de dados) .
Quando a variável tem a aderência a normal.
Ou quando estou utilizando para grandes amostras.
Distribuição relevante para os valores críticos é a normal padrão.
Teste t para médias de uma amostra:
Para amostras, bem parecido com teste Z, porem normalmente aplico o teste t quando não conhece o desvio padrão populacional , então utilizo o desvio padrão amostral.
Distribuição t é usado com n-1 grau de liberdade.
Teste t para correlações:
Após estimado o coeficiente de correlação (r) entre variáveis quantitativas, é possível testar a significância do parâmetro estimado.
Distribuição relevante é a t de student com n-2 graus de liberdade.
Exemplo, imagina que encontrei a correlação, o coeficiente de correlação entre 2 variáveis quantitativas e agora quero ver se esse coeficiente de correlação é estatisticamente significante. Exemplo abaixo utilizado correlação de pearson, veja:
Com nível de significância de 5%, o exemplo acima é bicaudal será 2,5% para a esquerda do gráfico e 2,5% a direita do gráfico, o calculo do valor crítico revelou ser 2,048 (com n-2 grau de liberdade):
conclusão, o coeficiente de correlação “matemática-física” é estatisticamente diferente de 0 e é estatisticamente significante.
Teste qui-quadrado para uma amostra:
Aplicado quando tenho 1 variável categóricas onde ela pode assumir 2 ou mais categorias (k), objetivo é verificar se há diferenças entre as frequências observadas e esperada.
Exemplo de aplicação: Uma loja verificar se vende mais dependendo do dia da semana. Se acaso forem estatisticamente significante 5%, ou seja, no lado Não Critico do gráfico, não há evidencias que dependendo do dia da semana influencie na quantidade das vendas.
Teste F para comparação de variâncias:
Para comparar as variâncias de duas amostras independentes.
Distribuição relevante é a F de Snedecor, com n-1 graus de liberdade no numerados e n-1 graus de liberdade no denominador.
Intervalo de confiança
Intervalo de confiança para a média:
Quando obtemos a estimativa para a média populacional a partir de uma amostra, tambèm podemos construir seu intervalo de confiança, isto é, um intervalo de valores possíveis para o parâmetro populacional.
É necessario estabelecer o nível de confiança da análise (exemplo 95%)
Z e t são valores bicaudais, na distribuição t utiliza-se n-1 graus de liberdade.
Exemplo: Imagine tendo a média amostral, mas você queira ter uma faixa de valores para conter os valores populacionais, a partir da sua média amostral. Pode usar a Z ou a T, a Z para grandes amostras conhecendo a média populacional, e a t para pequenas amostras e não conhecendo a média e desvio padrão.
Resumos Geral: (mais utilizados)
🔹 Testes Paramétricos (quantitativos e devem ter normalidade)
Teste t de Student (uma média, duas médias independentes ou emparelhadas)
ANOVA (Análise de Variância) e suas extensões (para comparar três ou mais médias)
Testes de normalidade: Kolmogorov-Smirnov, Shapiro-Wilk (amostra pequena), Shapiro-Francia
Testes de homogeneidade de variâncias: Bartlett, Cochran, Hartley, Levene
🔹 Testes Não Paramétricos (qualitativos ou ocorre violação de suposições paramétricas)
Qui-quadrado (χ²): para variáveis nominais ou ordinais, em uma ou mais amostras
Teste Binomial: para variáveis binárias (sucesso/fracasso)
Teste dos Sinais: para dados ordinais, em uma ou duas amostras emparelhadas
Teste de Wilcoxon: comparação de duas amostras emparelhadas
Mann-Whitney U: comparação de duas amostras independentes ordinais
Teste de McNemar: variáveis binárias emparelhadas
Friedman: k amostras emparelhadas (ordinais)
Kruskal-Wallis: k amostras independentes (ordinais)
Variáveis aleatórias discretas: sem valores decimais, são valores inteiros. Exemplo: quantidade de filhos.
Variáveis aleatórias continua: qualquer valor contidos nos números reais. Exemplo: salário, distância entre cidades.
Variáveis discretas
Distribuição de probabilidade:
Uniforme
Bernoulli
Binomial
Binomial negativa
Poisson
Distribuição uniforme discreta: Todos os valores possíveis têm a mesma probabilidade de ocorrência. Exemplo: As probabilidades dos resultados possíveis ao lançar 1 DADO são: 1,2,3,4,5 ou 6. A probabilidade de tirar 1 desses números pode ser modelada pela distribuição uniforme discreta, pela formula ficaria: p(Xi) = 1/n ==> p(x=1)=1/6 , p(x=2)=1/6,… sempre 1/6 é a probabilidade de tirar 1 desses números no DADO.
Distribuição de Bernoulli (Logística binária): os valores da variáveis podem assumir apenas 2 resultados, sendo sucesso (x=1) ou fracasso (x=0), ou Sim (x=1) e Não (x=0). Formula: ( P(X = x) = p^x (1 – p)^{1 – x} ), onde ( x ) pode ser 0 ou 1.
Distribuição binomial (Logística multinomial): A variável do modelo binominal indica a quantidade de sucesso (k) nas (n) repetições. Onde você tem 3 ou mais resultados. Formula: P(X = x) = (n x) p^x (1 – p)^(n-x).
Distribuição binomial negativa: A probabilidade de sucesso(p) é constante em todos os ensaios realizados. A variável no modelo binomial negativa indica a quantidade de ensaios (x). A diferença entre a binomial, é que na binomial você tem a quantidade de repetições e você analisa quantos sucessos ocorrem nessas n repetições, já na binomial negativa você analise quantos ensaios são necessários para atingir aquele sucesso estabelecidos.
Distribuição poisson: A probabilidade de ter (k) sucessos, mas agora você deve definir a exposição contínua.
Exemplo exposição contínua: tempo e área.
Variáveis contínuas
Distribuição de probabilidade:
Normal
Qui-quadrado
t de Student
F de Snedecor
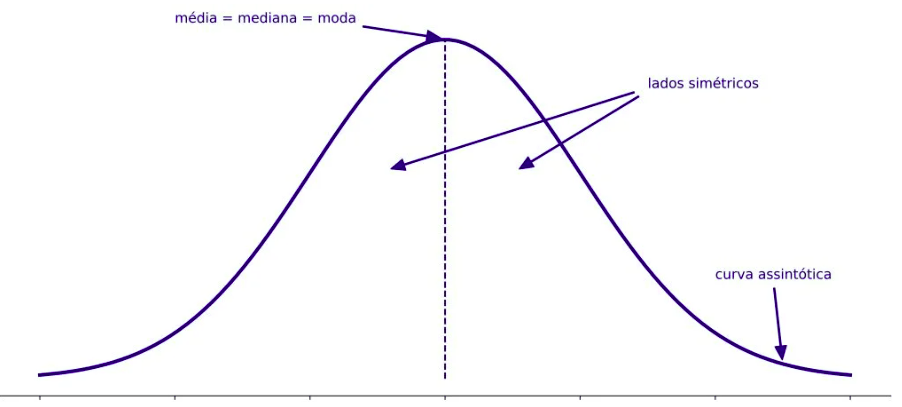
Distribuição normal: Gaussiana, com curva em formato de sino. Baseada na média e do desvio padrão da variável. É simétrica em torno da média. Quanto menor o desvio padrão, mais concentrados estão os valores em torno da média.
No centro temos a média. Ou seja, são simétricas em torno da média, ou seja, metade das probabilidades estão acima da média e a outra metade abaixo da média.
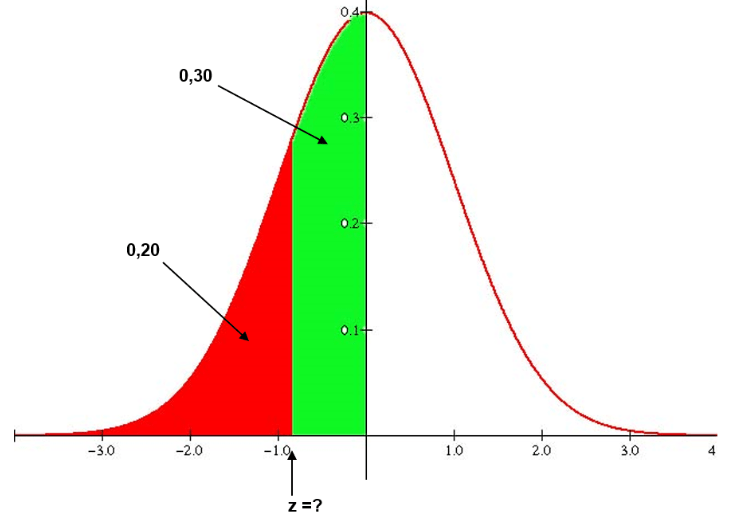
z-score, para transformar em uma distribuição normal padrão. indica a distância de um valor em relação à média de um conjunto de dados, calculando os dados em uma distribuição com média 0 e desvio padrão 1.
São utilizados em diversas áreas, ele descreve a relação entre um valor e a média de um grupo de valores. Podem ser tanto negativos, quanto positivos os Z-Scores. O valor positivo mostra que a pontuação está acima da média e a pontuação negativa mostra que está abaixo dessa média. Em finanças, por exemplo podem ser utilizados como medidas de variabilidade de uma observação e ajudar traders a determinar a volatilidade do mercado.
Com o z-score conseguimos achar as area do grafico, que são as Zs:
Exemplo de exercícios que conseguimos achar nas áreas Z:
“O salário semanal dos operários de construção civil de certo país é distribuído normalmente em torno da média de $ 80, com desvio padrão de $5.
a) Qual é o valor do salário para escolhermos 10% dos operários com maiores remunerações?
b) Qual é o maior salário correspondente aos 20% dos trabalhadores que ganham menos?”
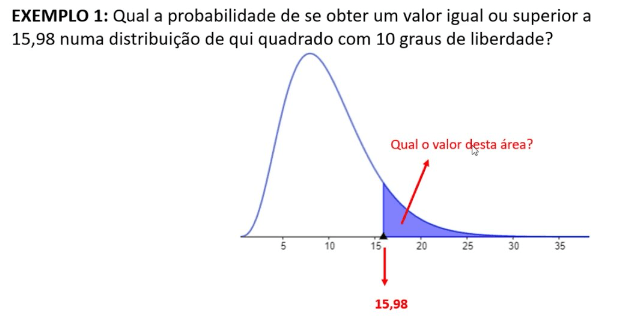
Distribuição qui-quadrado: Diferente da distribuição normal, a qui-quadrado depende de 1 parâmetro chamado de grau de liberdade.
A distribuição tem curva assimétrica e positiva para valores mais baixos nos graus de liberdade. Utilizado em testes de associação entre variáveis categóricas. Exemplo: Achar valores críticos e probabilidades associadas á distribuição qui-quadrado.
Gráfico assimétrica positiva é com cauda alongada para direita:
Distribuição t-studente: Parece muito com a normal padrão, forma de sino e é simétrica em torno da média.Porem a t-student tem a cauda mais alongada, ou seja, permite visualizar valores mais nos extremos e dependem do grau de liberdade.
Distribuição F de Snedecor (distribuição de Fischer): Muito utilizado para analise de variância. Forma assimétrica e positiva quando os graus de liberdades são pequenos. São 2 parâmetros graus de liberdade no numerador e grau de liberdade no denominador, a forma da curva depende do grau de liberdade.
Tipos de variáveis, são importantes para evitar ponderações arbitrarias e para escolher o modelos correto, pois a escolha do modelos de machine learning dependem do tipo de variável resposta ser qualitativa/categórica ou quantitativa.
Tipo de variável quantitativa são números e são para medir quantidade, podem ser continuas ou discretas, onde discretas são valores inteiros (1,2,3..100), exemplos quantidade de filhos. Continuas são categóricas, exemplos classes, faixas.
Frequência – Estatística Descritiva
Tabela de frequência exemplo:
Medidas de posição para variáveis métricas:
Média
Mediana (ponto central da variável, bom para verificar se a média esta equilibrada)
Moda (analisar elementos centrais, qual valor que mais de repete, o valor com mais frequência)
Percentis (divide em 100 partes iguais, em ordem crescente)
Quartis (divide em 4 partes iguais, 1 quartil=25%, 2 quartil=50%…, em ordem crescente)
Decis (divide em 10 partes iguais, 1 decil=10%, ….8 decil=80%, em ordem crescente)
Medidas de dispersão:
Amplitude (diferença entre valor máximo e valor minimo)
Variância (mostra a dispersão dos valores em relação a média)(o quanto esta distante da media, valores muito alto, variância muito alta,valores muitos dispersos , maior a variância) (se eu tiver valores muito próximo da media a variância será pequena)
Desvio padrão (calculado em cima do valor da variância)(maior o desvio padrão, mais dispersos estão os valores)
Erro padrão: é o desvio padrão da média da variável (quanto maior a minha amostra (n) menor o erro padrão, mais precisa é a media estimada)(utiliza o valor do erro padrão para os cálculos da inferência)
Coeficiente de variação: é uma medida de dispersão relativa, pois relaciona o desvio padrão e a média da variável. Pode ser utilizada para comparação de amostras. Quanto menor o CV mais homogêneo os valores da variável.
Medidas de formas
Curtose
Assimetria: local de concentração da distribuição
curva simétrica: média = mediana = moda
curva assimétrica direita: média > mediana
curva assimétrica esquerda: média < mediana
coeficiente de assimetria de fisher
coeficiente de curtose de fisher
medidas com visões na parte gráfica
Relação entre variáveis
Covariância:
medida de variabilidade conjunta entre duas variáveis aleatórias.
é uma medida de variabilidade conjunta entre duas variáveis aleatórias.
Correlação é essa medida de associação linear padronizada, de forma que assuma valores entre -1 e 1.
O sinal da covariância e da correlação indica se as variáveis se associam de forma positiva ou negativa.
Relação entre 2 variáveis.
Qualitativas: relação entre elas por meio de associação pelo teste qui-quadrado(χ²) e
Quantitativas: analise de correlação por meio da covariância e coeficiente de correlação de Pearson.
Teste qui-quadrado(χ²):
Relação entre 2 variáveis Qualitativas – é um teste de hipótese, baseado no qui-quadrado. Sempre o teste qui-quadrado em pares (2 variáveis descritivas)
Quando falamos de teste de hipótese, no caso qui-quadrado, falamos de 2 hipótese:
Hipótese Nula
Inicia pela tabela tabela de contingencia (tabela classificação cruzada), por frequência:
Agora o teste qui-quadrado de variável qualitativa, vamos avaliar a associação entre as 2 variáveis.(Teste qui-quadrado ou χ²: serve para avaliar quantitativamente a relação entre o resultado de um experimento e a distribuição esperada para o fenômeno) – Fonte: https://pt.wikipedia.org/wiki/Qui-quadrado
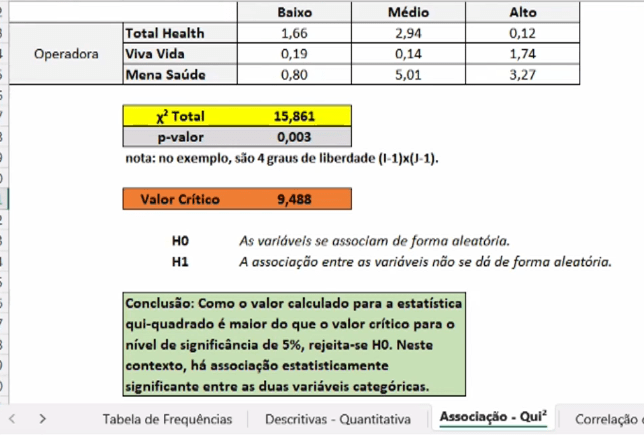
a soma de todos os qui-quadrado individuais é a estatística de teste que irá dizer se à ou não associação. Ex:
Veja que existem 2 Hipoteses, a Hipotese Nula H0 e a Hipotese H1.
Onde o H0 fica na Região Critica (RC) e H1 fica na Região de Não Rejeição (RN):
O qui-quadrado final, associação entre duas variáveis, vou verificar em qual região está, na RC ou na RN, na RN existe associação. Porem para essa decisão tenho que ter o valor critico e o valor critico muda em relação ao grau de liberdade, o valor do grau da liberdade depende do teste estatístico, no teste qui-quadrado o calculo é:
Valor critico, depende do nível de significância, normalmente utiliza-se 5%:
Ou seja, Quando o valor da estatística Qui-quadrado é maior > que o valor crítico, a hipótese nula é rejeitada, indicando uma associação significativa entre as variáveis (com 4 graus de liberdade).
p-valor: é a Área (0,003) a direita do teste estatístico qui-quadrado (15.86). Como o p-valor é menor que o nível de significância 0,05, então rejeito H0, ou seja existe associação entre as 2 variáveis.
Coeficiente de Correlação de Pearson
Sempre entre 2 variáveis, utilizado para avalizar a correlação de 2 variáveis quantitativa.
Inicia-se o calculo pela covariância entre as 2 variáveis, depois obtêm-se o coeficiente de pearson.
“A covariância é uma medida estatística que permite comparar duas variáveis, entendendo como elas se relacionam entre si” (Fonte: https://www.suno.com.br/artigos/covariancia/, acessado em 28 outbro 2024).
Exemplo, covariância positiva elas “caminham” pelo mesmo lado, ou seja, quando uma esta positiva a outra também está, quando uma está acima da média, a outra também esta acima da média.
Ou se a covariância for negativa quer dizer que as 2 variáveis andam em sentido opostos, ou seja, em quanto uma está acima da media a outra esta abaixo da media e vice-versa.
Coeficiente de Correlação de Pearson igual a Zero, sem correlação entre as 2 variáveis. Proximo do zero, também quer dizer que não é uma correlação tão intensa.
Podemos ver também em uma matriz de correlação de pearson: