Preparação dos dados para análise e modelos.
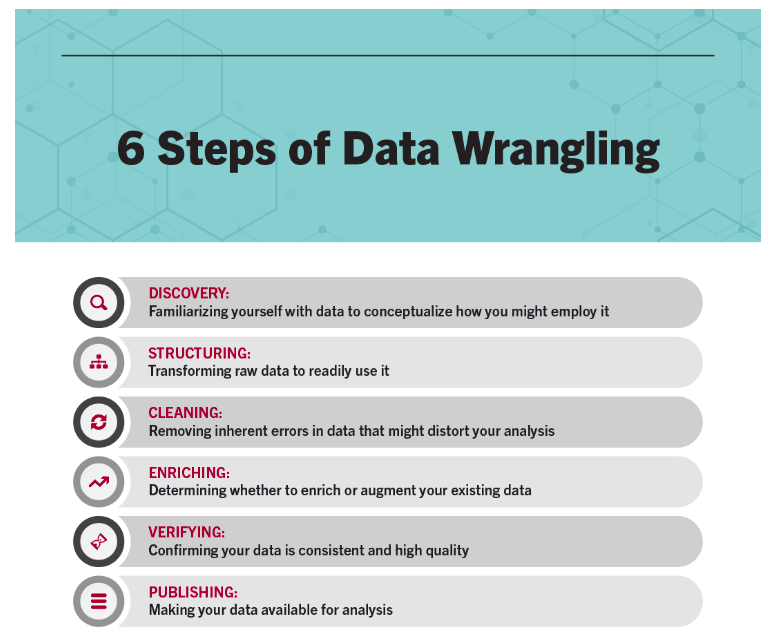
Descoberta:
Visualização principalmente com biblioteca python pandas, numpy, seaborn, matplotlib.pyplot.
Abaixo alguns exemplos muito utilizados.
dados_tempo.info()
# object = variável de texto
# int ou float = variável numérica (métrica)
# category = variável categórica (qualitativa)
# Selecionando com base nas posições (1º arg.: linhas, 2º arg.: colunas)
# ATENÇÃO: Linhas iniciam-se em zero! no Python
dados_tempo.iloc[3,] #Somante 3 linha
dados_tempo.iloc[:,4] # Todas as linhas e somente 4 coluna
dados_tempo.iloc[2:5,] # somente a partir da 2 linha até a 5 e todas colunas
dados_tempo.iloc[:,3:5] # todas as linhas, 3 e 5 coluna
Para não ter ponderação arbitraria, exemplo categorizar uma variavel metrica:
## Em certas circunstancias sera necessario trocar o tipo da variável
# Para evitar a ponderação arbitrária, vamos alterar o tipo
df_numeros['novo_perfil'] = df_numeros['novo_perfil'].astype('category')
df_numeros.info()
## categorizar aplicando critérios detalhados por meio de condições
dados_tempo['faixa'] = np.where(dados_tempo['tempo']<=20, 'rápido',
np.where((dados_tempo['tempo']>20) & (dados_tempo['tempo']<=40), 'médio',
np.where(dados_tempo['tempo']>40, 'demorado',
'demais')))
## Ou tambem categorizar eh por meio dos quartis de variaveis (q=4)
dados_tempo['quartis'] = pd.qcut(dados_tempo['tempo'], q=4, labels=['1','2','3','4'])
Matriz de correlações de Pearson
Lembrando que correlação de pearson varia de 1 a -1, onde 0 é sem correlação, 1 grande correlação e -1 grande correlação negativa, negativa é se 1 variável sobe a outra desce.
dados_tempo[[‘tempo’, ‘distancia’, ‘semaforos’]].corr()
Tabela de frequências para variáveis qualitativas
dados_tempo[‘periodo’].value_counts() # frequências absolutas
dados_tempo[‘perfil’].value_counts(normalize=True) # frequências relativas
Tabela de frequências cruzadas para pares de variáveis qualitativas
pd.crosstab(dados_tempo[‘periodo’], dados_tempo[‘perfil’])
pd.crosstab(dados_tempo[‘periodo’], dados_tempo[‘perfil’], normalize=True)
