“A cartografia é a ciência e arte de criar, estudar e comunicar informações espaciais por meio de mapas, cartas e outras representações gráficas da superfície terrestre. É uma disciplina que combina conhecimentos de geografia, matemática, informática e outras áreas, para representar e analisar dados espaciais de forma precisa e eficaz. “. Site: https://pt.wikipedia.org/wiki/Cartografia, acesso 15 de maio de 2025.
“Geotecnologia, conjunto de tecnologias para coleta, processamento, análise e disponibilização de informação geográfica. A Geotecnologia envolve aplicação de tecnologias da informação e comunicação para a aquisição, processamento, análise e visualização de dados geoespaciais. Este campo interdisciplinar desempenha um papel crucial em diversas áreas do conhecimento, incluindo geografia, cartografia, geologia, biologia, agricultura, planejamentourbano e gestão de recursos naturais.”. Site: https://pt.wikipedia.org/wiki/Cartografia, acesso 15 de maio de 2025.
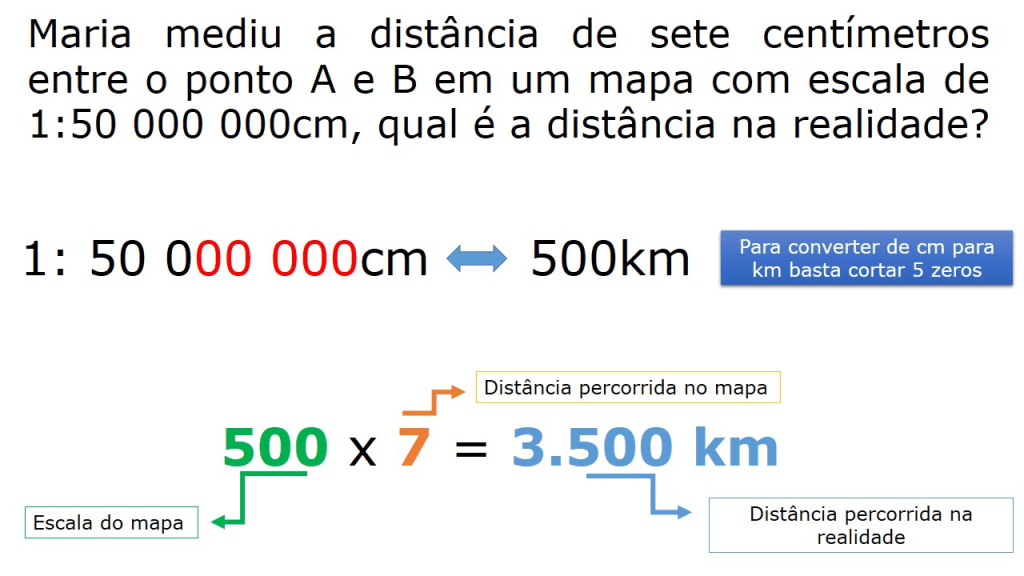
Escolha do sistemas de coodenadas.
é uma superfície matematicamente definida que se aproxima do geoide, a verdadeira figura da Terra ou qualquer outro corpo planetário
Variações regulares e periódicas na média da série, repetições ao longo de um dia, uma semana ou um ano são comuns.
As variações geralmente são ocorrem devido a aspectos do comportamento humano ou ciclos naturais ou comportamentos convencionais da sociedade. Ex. Transito durante a semana e horários de picos.
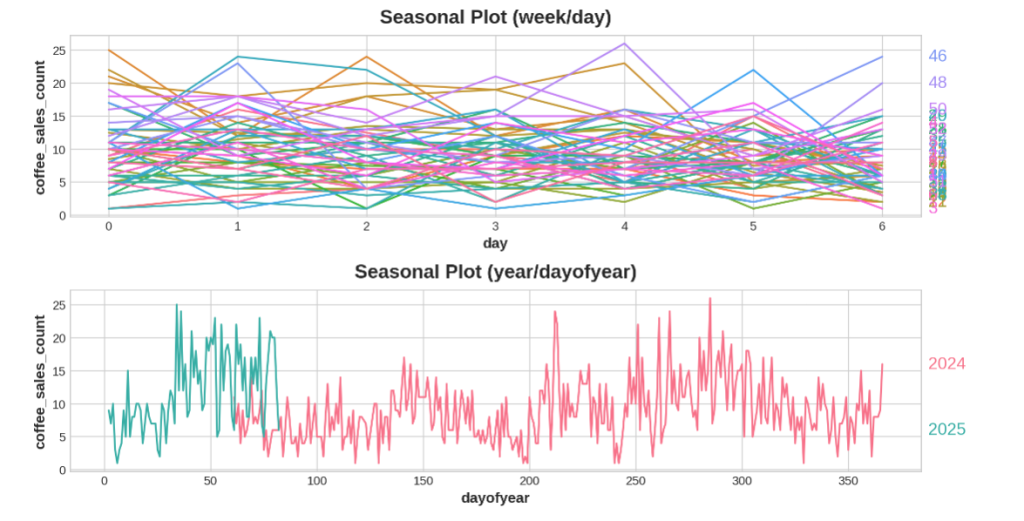
Assim como um plot da Média Móvel para descobrir a Tendência, utilizamos o Plot sazonal para descobrir a sazonalidade.
Fourier e Periodograma
A Feature Fourier tenta capturar a forma geral da curva sazonal, ao invés de tentar capturar para cada data.
Abaixo um gráfico de venda de café, podemos ver movimentos para cima e para baixo em alguns momentos do ano.
Essas frequências que tantamos visualizar com a Feature de Fourier. As curvas são das funções trigonométricas seno e cosseno.
São pares de curvas de seno e cosseno, um par para cada frequência potencial, iniciando pela mais longa. Os pares de Fourier que modelam a sazonalidade anual teriam frequências: uma vez por ano, duas vezes por ano, três vezes por ano e assim por diante.
Extrair informações importantes de textos, em .csv, banco de dados e de informação de grandes volumes textuais, análise de sentimentos, classificação de texto, detecção de fraudes e spam..
A maior parte são dados não estruturados, muita informação, com o Text Mining consegue-se extrair informações relevantes sobre todo esse volume de dados.
Onde pode ser utilizado?
Saúde e pesquisa.
Atendimento ao cliente.
Gestão de Riscos.
Pesquisa acadêmica.
Análise de sentimento.
Filtragem de Spam.
Pré-processamento
Tokenização: Transforma cada palavra ou frase em token
Stopwords: Utiliza somente as palavras importantes. Ex: “e”,”de,”um,”as”, …(português)
Lemmatization: Palavras importantes, aposto do stemming, precisão semantica, deixa a palavra no formato correto: ctz –> para –> certeza
lowercasing – minusculas
remover pontuação – se acaso não tiver valor semantico, se tiver valor semantico não remover.
stemming – reduz a palavra a sua raiz. Ex. fez, fazem, fazer –> para –> fazer.
Dica: iastudio.google.com – mostra quantos token com a pergunta e com a resposta (deixa mais barato a quantidade de token em um modelo generativo):
Área da linguistica e aprendizado de maquina (ML) relacionado ao entendido de linguagem humana.
Objetivo do NLP
Classificação de sentimento, identificar spam, se tem verbo, substativo, preencher lacunas de textos, extrair respostats baseadas em uma pergunta passada, traduzir o texto para outro idioma.
Tambem engloba outros desafios, como visão computacional, geração da transcrição de áudio e descrição de imagem.
Multiplicação de matrizes, com os pesos corretos, ótimo predict.
Função de Ativação:
Mais utilizada é a ReLu (classificação 1 ou 0):
Outra função de ativação bem conhecida é a sigmoide.
Função Custo:
Mostra o quanto errou a sua rede, exemplo de função de custo é o erro quadrático médio, mas existem muitas outras funções de custo.
Descida do Gradiente:
Encontrar o menor valor da função custo com base nos seus pesos. Esse método se chama Backpropagation.
Por trás é baseado em calculo diferencial.
*Empiricamente as Redes Neurais Artificiais aprendem melhor com dados Normalizados, como o método min-max normalization (valor fica entre 0 e 1), aprendem melhor com numeros “menores”, provavel devido a backpropagation. Intuitivamente se eu tiver valores muito grandes terei erros muito grandes e vou propagar ele durante a rede, a ideia de normalizar é ter uma descida de gradiente mais suave, e buscar o melhor valor do vale com menor função custo.
Algoritmos suscetível a “overfitting”, por isso é recomendável realizar validação cruzada (“cross validation”).
Achar o tamanho “ideal” da árvore para assim diminuir sua complexidade e dimunuir também o overfitting, ao mesmo tempo maximizando a qualidade do modelo.
Variável resposta quantitativa e qualitativa
Visualmente parece uma árvore com uma cascata de perguntas e probabilidade, cada pergunta é uma quebra, a ultima pergunta é a folha, e a quantidade de perguntas é a profundidade da árvore.
Impurezas: o algoritmo busca minimizar o indicador de “impureza”, testa todas as possíveis quebras binárias com todas as variáveis disponíveis. Com menor impureza. Até um critério de parada, até impureza zero por exemplo, ou só faço mais quebra se tiver 30 sobreviventes no caso do titanic sobreviventes.
Exemplo de 2 tipos para definição de impureza: (como a árvore encontra a melhor quebra)
Gini
Entropia de Shannon
Hiperparâmetros: são parâmetros que controlam o algoritmo como:
Número mínimo de observações por folha
Profundidade máxima
CP – Custo de complexidade
CP – Custo da complexidade, deixar a arvore mais generica.
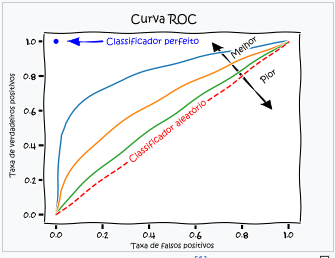
Em uma árvore para cada ponto de corte Curva-ROC tenho uma nova matrix confusão, consequentemente uma nova sensitividade e especificidade, Curva-ROC.
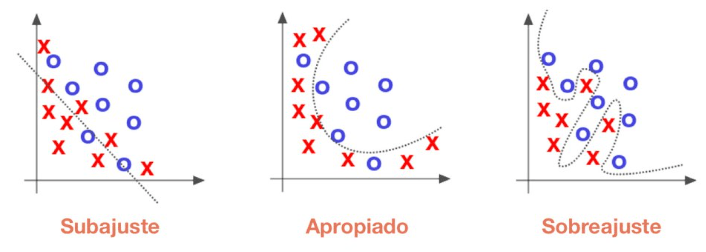
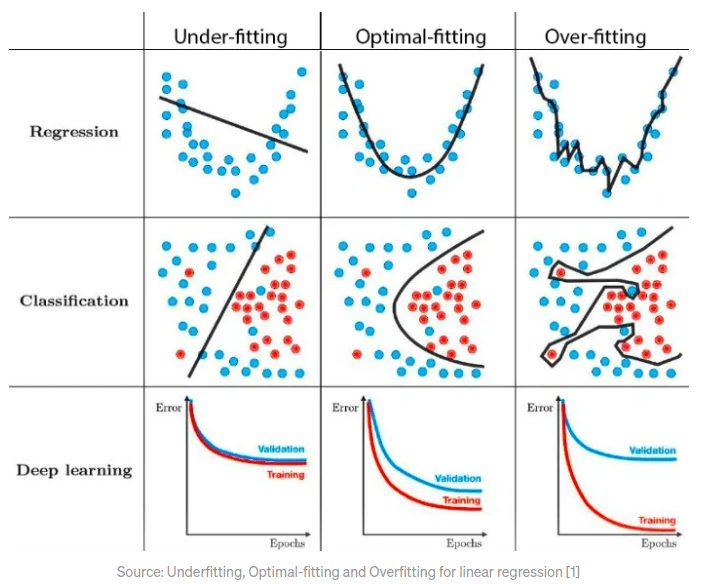
Primeiro identificar se o modelo está subajustado ou superajustado conforme o erro na predição dos dados de validação e treinamento. Quanto maior o erro, maior a variância, a variância é o erro do modelo para os dados de teste; já o viés, é o quão bem um modelo se adequa aos dados de treino, o quanto ele é generalista.
O ideal é um modelo que tem baixo viés e baixa variância, ou seja, ele se adéqua a qualquer dados e erra pouco.
Sobreajustado (overfitting): quer dizer um modelo não generalista, ou seja, ele memorizou os dados, acertou os dados de treinamento, mas obteve uma alta taxa de erros nos dados de validação.
Sobajustado (underfitting): é um modelo que erra bastante na predição dos dados de treinamento, tem baixo desempenho, uma das causas é que o modelo escolhido seja muito simples para o descrever e obter a variável dependente.
Balanceado (balanced): é um modelo ideal, com pouco erro para os dados de teste e um modelo generalista.
Objetivo é achar os melhores valores para os hiperparametros (tunning do modelo) e ter uma expectativa mais acurada da qualidade do nosso modelo (Exemploe melhor AUC)
Divide a amostra em Treino e teste, onde treino será onde o modelo será desenvolvido e o teste será onde o modelo será avaliado.
Ou
Divide a amostra em Treino , Validação e teste, onde treino será onde o modelo será desenvolvido e o validação será onde o modelo será avaliado e teste o “valendo” onde será a real performance do modelo.
Performanceclassificador binário – 0 não evento e 1 evento
O eixo “Taxa de verdadeiros positivos” é o acerto do evento e no eixo horizontal “Taxa de falsos positivos” é o erro do não-evento
GINI: (não é o mesmo gini de árvore)
Acurácia: medida mais intuitiva e mais simples
Matrix de confusão, vemos o total de positivos que foram classificados como positivos e total de negativos que foram classificados como negativos, soma ambos e divide pelo total da amostra, esse será o valor% da acurácia.
Porem, é apenas para 1 ponto de corte (50% – 50%).
Sensitividade: Acerto dos positivos
Especificidade: Acertos do não evento
Em uma árvore para cada ponto de corte Curva-ROC tenho uma nova matrix confusão, consequentemente uma nova sensitividade e especificidade, Curva-ROC.
K-fold:
Ele divide a base de treino em k grupos, separa um para validação, treina para os demais e avalia o modelo, e vai trocando os grupos , e depois calcula a media, acaba fazendo a validação com toda base de dados, e com a validação cruzada faz uma validação melhor.
Utilizado para comparar e validar os hiperparametros, o melhor é o que tem melhor acurácia.
Aqui terá um pouco sobre Time Series Forecasting , onde terá previsões do futuro em conjunto com aprendizado de maquina com series temporais, com objetivos de obter previsões mais precisas.
Series temporais são sequenciais e se correlacionam com os dados vizinhos, dias anteriores,
Objetivo series temporais:
podem ser para verificar padrões como sazonalidade, tendências, outliers (a principio não remover outliers em series temporais) (valores discrepantes).
prever o futuro (tentar prever o futuro) dos comportamentos das variáveis conforme os valores daquela serie.
Pode tambem com a previsão de uma serie, tentar entender em conjunto com outra serie temporal e verificar se uma tem influência sobre a outra. Variação multivariada.
Iniciando Series temporais com modelo de regressão linear.
Detalhes dos modelos de regressão linear estão descritos em outro post, mas em resumo o modelo aprende como fazer a soma ponderada a partir das observações de entradas. Onde no treino o modelo de regressão aprende os valores para os pesos e tendencias (fit) que mais se ajusta ao alvo (o modelo de regressão linear costuma ser chamado de mínimos quadrados ordinários, pois escolhe valores que minimizam o erro quadrático entre o alvo e as previsões.).
Os pesos para cada entrada, tambem podem ser chamados de coeficiente de regressão (regression coefficients) e o viés (bias) tembém pode ser chamado de intercept (interceptação), pois mostra onde o gráfico desta função cruza o eixo y.
Exemplo do algoritmo de regressão linear, com 2 entradas (feature) e seus pesos (weight):
Steps: existem dois tipos de Time Step, de tempo e de atraso, onde o de tempo derivam do time index, o mais básico time index é um indice do inicio da Serie até o Fim:
Regressão Linear com tempo:
target = weight * time + bias
A Regressão de tempo nos permite ajustar curvas a séries temporais em um gráfico temporal, onde o Tempo forma o eixo x.
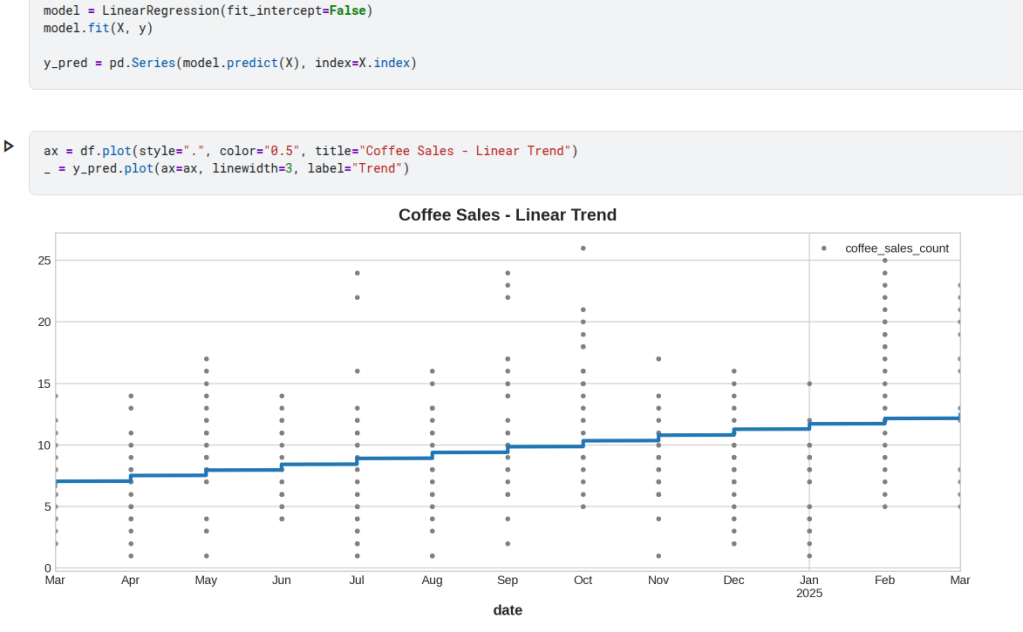
Os time-steps feature permitem modelar a dependência do tempo. Uma série depende do tempo se seus valores puderem ser previstos a partir do momento em que ocorreram. Acima é uma serie de vendas, podemos verificar teve um aumento nas vendas durante o ano.
Lag features Para criar uma característica de atraso, deslocamos as observações da série alvo para que pareçam ter ocorrido mais tarde no tempo. Aqui criamos um recurso de atraso de 1 etapa, embora também seja possível mudar em várias etapas.
Uma série temporal tem dependência serial quando uma observação pode ser prevista a partir de observações anteriores.
Regressão linear com feature de Lag:
target = weight * lag + bias
Abaixo o gráfico de Lag, onde cada observação da série é plotada em relação à observação anterior.
Vemos no gráfico de Lag, que as vendas de Coffee estão correlacionadas com as vendas do dia anterior, com isso vemos que o Lag será útil para nós. Tendência linear crescente: conforme o valor de Lag_1 aumenta, o valor de coffee_sales_count também tende a aumentar.
Com isso vemos que tem dependência serial na série, pois vimos acima que a observação pode ser prevista a partir de observações anteriores. No exemplo acima vemos que podemos prever que vendas altas em 1 dia, significam vendas altas no próximo dia.
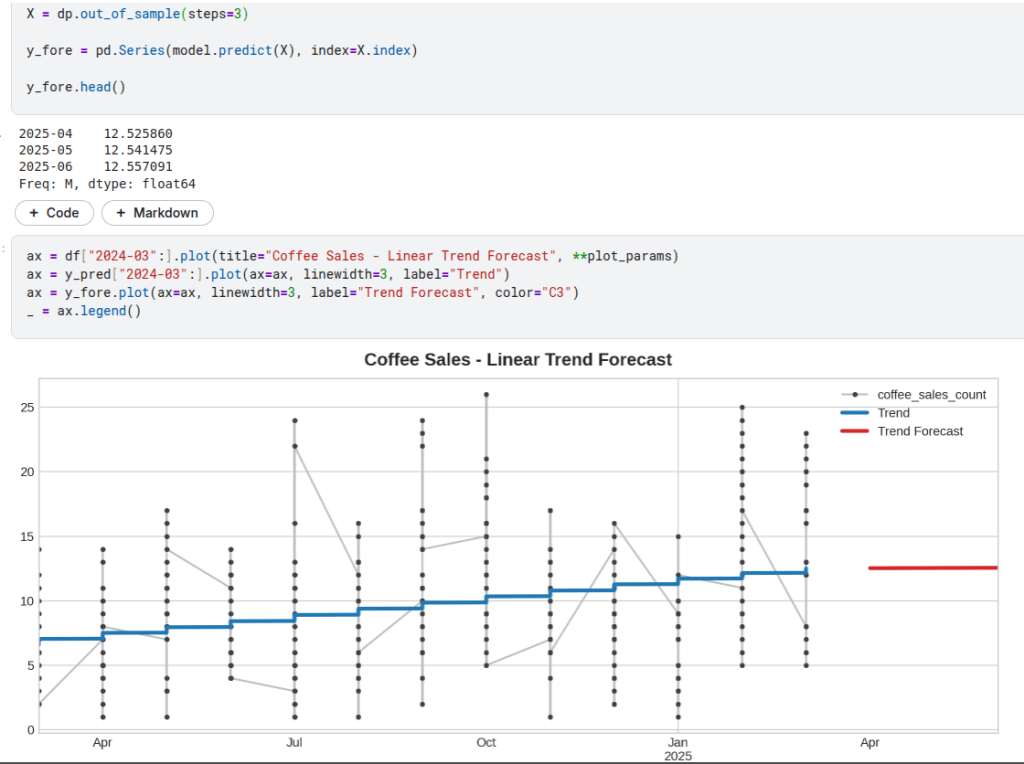
Abaixo uma previsao baseado no Lag das vendas de coffee:
Os melhores modelos de séries temporais geralmente foram adicionados alguma combinação de recursos de tempo (step features) e recursos de atraso (Lag features).
Tendências:
Em uma serie temporal a tendência pode ser de crescimento ou decrescente, mostra alguma tendência no tempo.
O que não consigo explicar com a tendência e a sazonalidade. Normalmente sempre aparecem resíduos e normalmente o plot espera-se a não demonstrar padrão.
Não excluir os resíduos, primeiro compreender, talvez teve falha na coleta, algo assim.
Tipo de modelo:
Multiplicativo: vai até o valor 1.
Sazonalidade:
Existem funções que automaticamente identificam o intervalo da sazonalidade, se é 1 semana, mês, ano. No índice, recomendado que o datatype do índice seja DatetimeIndex, há outras alternativas caso o índice não seja DatetimeIndex.
Normalmente verifica a média da sazonalidade para ter um modelo mais geral possível. Em caso de ter 1 mês atípico, então se pega 12 safras/referencias/cohort
Recursos para modelar Sazonalidade:
Modela sazonalidade com poucas observações, como observações diárias com historico de 1 semana, como One-hot encoding por semana.
Recurso de Fourier : para observações maiores, como historico de 1 ano com coleta a cada 1 hora.
Suavização:
Cada média movel será um “nova” serie, acaba descacterizando os dados, quando usar? exemplo juntar 2 series uma semanal e outra diária, transformar a diária com a média móvel para semanal.
Média Movel Simples:
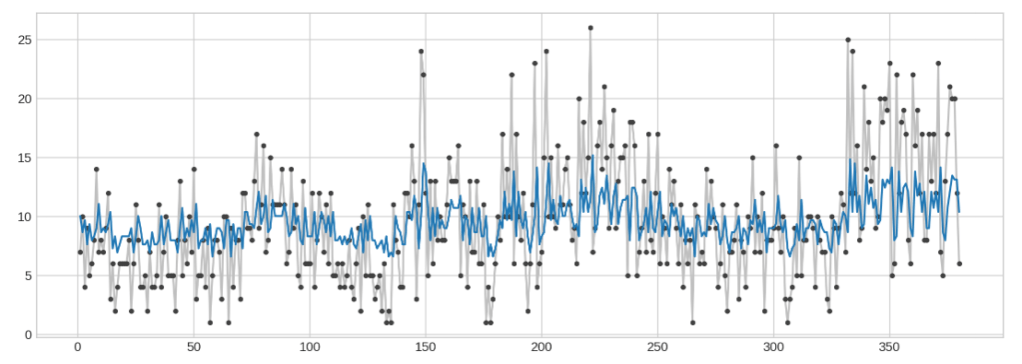
A média móvel ajuda a entender o comportamento da serie, exemplo pega a soma das 7 ultimas observações e vai construindo uma nova série das médias móveis.
Média móvel nada mais é do que a média aritmética das r ultimas observações.
Janela deslizante “rolling().mean” vai calcular a media a cada 6 linhas (pode ser outra medida, como a mediana):
Tambem podemos verificar o tipo de tendência, no caso linear.
DeterministicProcess
Recursos derivados do índice de tempo geralmente serão determinísticos, não serão aleatórios.
O argumento de ordem se refere à ordem polinomial: 1 para linear, 2 para quadrático, 3 para cúbico e assim por diante.
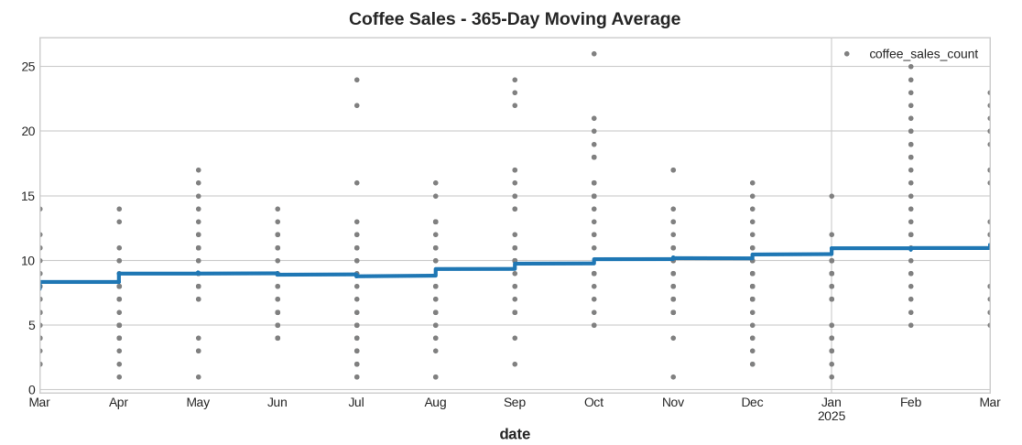
Na figura acima vemos que a previsão com regressão ficou bem parecida com a média móvel, ou seja, sugere que uma tendência linear foi a decisão certa neste caso.
Forecasting de 3 Meses (datetimeindex esta com frequencia/periodo Mensal) – Vendas de café com Regressão Linear:
Média Móvel Exponencialmente ponderada (MMEP):
Pelo calculo, na MMEP acaba dando pesos diferentes para observação anterior, ela não suaviza tanto quanto a média móvel simples. Diferente da média móvel que é aritmética, a exponencial é ponderada.
passageiros['MMEP12'] = passageiros['Milhares de passageiros'].ewm(span=12,adjust=False).mean()
OBS: Média Móvel Simples e Média Móvel Exponencialmente Ponderada não são utilizadas para fazer predição.
Dados Multivariados:
# US Change 1970 a 2016
# Fontes:
# Hyndman, Rob J., and George Athanasopoulos. Forecasting: principles and practice. OTexts, 2018.
# Dados disponíveis em https://github.com/robjhyndman/fpp2-package e
# https://github.com/cibelerusso/Aprendizado-Dinamico/tree/main/Data
# Percentage changes in quarterly personal consumption expenditure, personal disposable income, production, savings and the unemployment rate for the US, 1960 to 2016.
uschange = pd.read_csv('https://raw.githubusercontent.com/cibelerusso/Aprendizado-Dinamico/main/Data/uschange.csv', index_col=0,
parse_dates=True)
uschange.index = uschange.index.to_period("Q")
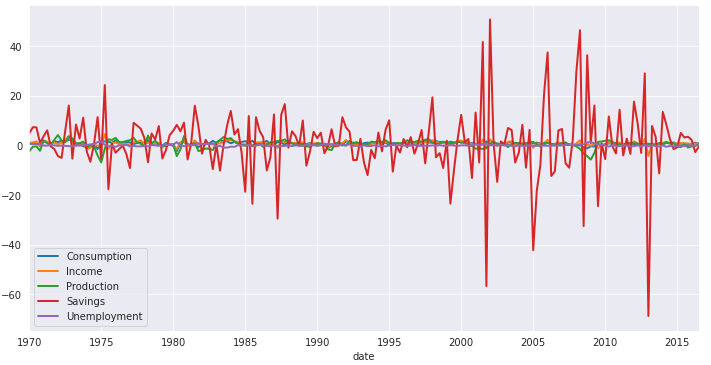
uschange.plot(figsize=(12,6));
A principio o que observamos na serie acima, é que o Savings parece não ter uma tendência ao longo do tempo, porem a variância aumenta no Savings, a variância aumenta comparados a períodos anteriores, aplica-se o conceito da média e variância da Serie temporal ao longo do tempo, os Savings parece que a média não aumenta muito, pois não aumenta a linha vermelha, mas a variabilidade dos dados parece aumentar.
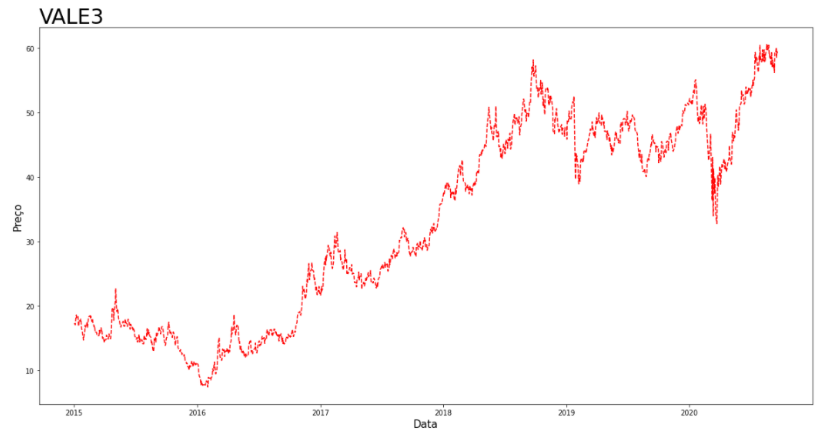
Outros exemplos de dados que não tem uma sazonalidade mais marcada , mas vemos um tendência de altos e depois baixos, no final, é do dataset das ações da Starbucks, como segue abaixo, tem modelos específicos para esse tipo de dados, normalmente dados de ações, financeiros, modelos GARCH, que são modeloas autoregressivos que modelam a Heterocedasticidade, a volatilidade, são modelos mais avançados: